小白python爬虫入门实战(爬取糗事百科)
一.前期准备:
1.需要软件:pycharm,xpath helper,python3.6,chrome浏览器。
第一步,百度下载以上软件。
附上链接:pycharm的https://www.jetbrains.com/pycharm/ 点击首页download ,下载免费使用的community
xpath helper的https://pan.baidu.com/s/1c2vYUOw 提取密码mutu,下载好后在谷歌浏览器右上方,更多工具,扩展程序里面,把下载好的xpath helper拖动进去即可。
python的https://www.python.org/ 在download里面下载相应版本即可。并配置好环境。这里就不详细解说。
谷歌浏览器直接在百度上面下载即可。
以及下载相应的库包
2.cmd控制台里面直接下载(注意,Pip必须是最新版本的,否则可能下载不成功):pip install requests
pip install lxml
二.开始写爬虫。
思路分析
提取url,发送请求,获取相应, 提取数据,保存数据。
我所要爬取的事糗事百科,首先分析一下他的url规律,以及想要爬取的内容。
右键点击检查。开始查找
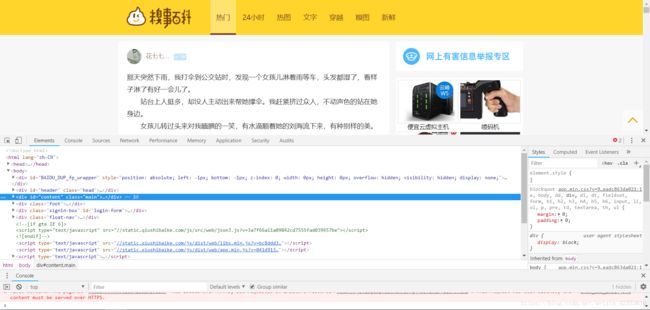
先看network
刚开始可能没有内容。点击刷新即可
点击第一个,从里面提取user-agent
把网页拉到下面,不难发现我们所爬取的网页有13页多,每页点击一下,看一下url地址,不难发现规律:
![]()
![]()

也就是page后面的数字改变了,对应的就是相应的页数。
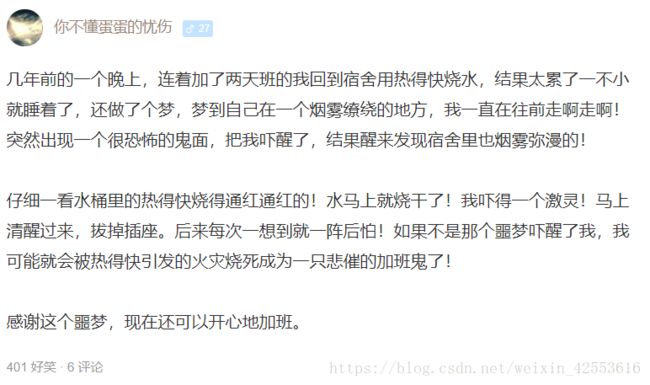
ctrl+shift+c,鼠标指向你想爬取的地方,这里我打算爬取用户名,好笑数量,评论数和一些段子有图片的图片地址

ctrl+shift+x,使用xpath helper得到所对应的xpath为.//h2/text() ps:右键点击copy xpth也可。

同样的道理,找出另外三条我们想要爬取信息的xpath。分别如下:
文本内容:.//div[@class='content']/span/text()
好笑数量:.//span[@class='stats-vote']/i/text()
评论数:.//span[@class='stats-comments']//i/text()
图片地址:.//div[@class='thumb']//img/@src
好了,基础工作已经完成。下面开始写代码。
提取url
def __init__(self):#初始化函数
self.url_temp = "https://www.qiushibaike.com/8hr/page/{}/" #爬糗事百科 这里的{}用来存放页数
self.headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36"}#拿取user-agent def get_url_list(self):#这里定义一个拿取url列表的函数。
url_list = [self.url_temp.format(i)for i in range(1,14)] #用format字符串格式化,这就是糗事百科1到13页
return url_list #返回url列表发送请求,获取相应
def parse_url(self,url):#定义一个分析函数,用来发送请求,获取相应用的。
print("now parsing:",url)
response = requests.get(url,headers=self.headers) #response接收返回的rul
return response.content.decode() #返回 def save_content_list(self,content_list):# 保存
with open("qiubai.txt","a",encoding="utf-8")as f: #因为是追加填写,所以用a
for content in content_list:
f.write(json.dumps(content,ensure_ascii=False))#写进去
f.write("\n")
print("保存成功")提取数据
def get_content_list(self,html_str):
html = etree.HTML(html_str) #得到element对象
div_list = html.xpath("//div[@id='content-left']/div") #所爬取的内容在这个div里面
content_list = []
for div in div_list: #所爬取的内容多,需要遍历分组
item = {} #item字典来分组
item["用户名"] = div.xpath(".//h2/text()")[0] if len(div.xpath(".//h2/text()"))>0 else None #内容很多,所以取列表取第0个即可,所以加if判断
item["文本内容"] = div.xpath(".//div[@class='content']/span/text()")#这里文本内容可能有两段,所以不用判断
item["文本内容"] = [i.strip() for i in item["文本内容"]]#由于文本内容有很多\n,所以strip掉,但是不能直接strip,所以要放在i里弄。
item["好笑数量"] = div.xpath(".//span[@class='stats-vote']/i/text()")[0]if len(div.xpath(".//span[@class='stats-vote']/i/text()"))>0 else None
item["评论数"] = div.xpath(".//span[@class='stats-comments']//i/text()")[0]if len(div.xpath(".//span[@class='stats-comments']//i/text()"))>0 else None
item["图片地址"] = div.xpath(".//div[@class='thumb']//img/@src")
item["图片地址"] = "https:"+item["图片地址"][0] if len(item["图片地址"])>0 else None
content_list.append(item)#获取的内容全部放在conteng_list里面
return content_list保存数据
def save_content_list(self,content_list):# 定义一个保存
with open("qiubai.txt","a",encoding="utf-8")as f:
for content in content_list:
f.write(json.dumps(content,ensure_ascii=False)) #ensure_ascii这参数保证显示正常,该中文的中文该英文的英文。
f.write("\n")#把Python类型转换为字符串,放在txt文件夹中
print("保存成功")执行
def run(self):定义有一个run的函数,用来执行程序。
url_list = self.get_url_list()#这是用来提取url
for url in url_list:
html_str = self.parse_url(url)#这是发送请求,获取相应
content_list = self.get_content_list(html_str)#提取数据
self.save_content_list(content_list)#这是用来保存写一个Main函数执行
if __name__ == '__main__':
qiubai = Qiushibaike_Spider()
qiubai.run()
成果如下:

小白新手入门写博客,如有写错,请纠正。谢谢。