正则表达式grep、egrep、sed和awk用法
1.1正则表达式
计算机科学中,对“正则表达式”的定义是 :它使用单个字符串来描述或匹配一系列符合某个句子规则的字符串。
1.1.1grep/egrep的 用法
grep的格式:grep [-cinvABC] ‘word’ filename
-c:表示打印符合要求的行号数
-i:表示忽略大小
-n:表示输出符合要求的行及行号
-v:表示打印不符号要求的行
-A:后面跟一个数字(有无空格都可以),例如-A1打印符合要求的行和下面一行
-B:后面跟一个数字(有无空格都可以),例如-B1打印符合要求的行和上面一行
-C:后面跟一个数字(有无空格都可以),例如-C1打印符合要求的行和上下各一行
-A2把包含halt那行以及下面两行打印出来

-B2把包含halt那行以及上面两行打印出来

-C2把包含halt那行以及上下两行打印出来

1.1.2 过滤出带某个关键字的行,并输出行列
#grep ‘bin’ /etc/passwd

1.1.3过滤出带某个关键字的行,并输出行列
grep -nv ‘nologin’ /etc/passwd
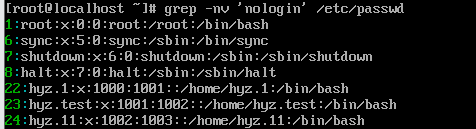
1.1.4过滤出所有包含数字的行
grep ‘[0-9]’ /etc/passwd

1.1.5过滤掉所有包含数字的行

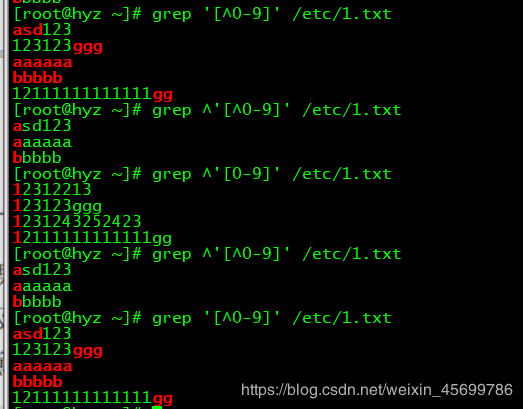
在正则表达式中,可以用’^'表示开始,用$表示结尾,那么空行则可以用[ ^ $]来表示
前面也提到了[ ]的用法,想要过滤掉数或者寻找关键数字,可以用[0-9]这样的形式(如果是[15]这样的形式,则表示只含有数字1和数字5)。如果想要过滤掉数字和大小写字母,则可以使用[a0-0a-zA-Z]这样的形势。另外,[ ^ 字符 ] 表示除[ ]内字符之外的字符,^放在[]外面的则表示以什么什么开头。看以下示例:


这是^的各种用法
1.1.6过滤掉任意一个字符和重复字符
grep ‘r.o’ /etcpasswd

.表示任意字符。上例中r.o表示把r与o之间有一个任意字符的行过滤出来。

*表示零个或多个它前面的字符。上例中,*表示oo、ooo、oooo…。

.*则表示零个或多个任意字符,空行也包括在内。
1.1.7指定要过滤的字符出现次数
egrep ‘o+’ test.1 egrep ‘oo+’ test.1 egrep ‘ooo+’ test.1 grep ‘o?’ test.1 示例:egrep ‘aaa|BBB|AAA’ /etc/hyz/test.1 百度对sed工具强大地方的介绍 sed -n ‘n’p filename sed ’10‘p filename sed -n '/字符串/'p filename sed命令加上-e可以实现多个操作。 sed ‘n’d filename 删除一行 se ‘/n1,n2s /要被替换的字符/替换成的字符/g’ filename 如果想把文档内的所有数字或者字母删除,命令如下: 实列:sed -r ‘s/(root)(.*)(bash)/\3\2\1/’ test.txt sed -i ‘s/ot/to/g’ filename (1)把/etc/passwd复制到/root/test.txt,用sed打印所有行 (12)把test.txt中第一数字移动到本行末尾 (百度对awk工具强大地方的介绍) 1.3.1截取文档中的某个段 awk ‘/root/’ test.txt awk -F ‘:’ ‘$1 ~/oo/’ test.txt awk -F ’:’ ’$3==“0”‘ /etc/passwd awk常用的变量有OFS、NF和NR,OFS和-F选项有类似功能,也是用来定义分隔符,但是他是在输出的时候定义,NF表示用分隔符分隔后一共有多少段,NR表示行号。 head -n3 /etc/passwd |awk -F ‘:’ ‘{print $NF}’ 这里NF是多少段,$NF是最后一段的值。 我们还可以使用NR作为判断条件 head -n 3 /etc/passwd |akw -F ‘:’ ‘$1=“root”’ (1)用awk打印整个test.txt(以下操作都是针对test.txt的,都用awk工具) (1)如何把/etc/passwd/中用户uid大于500的行打印出来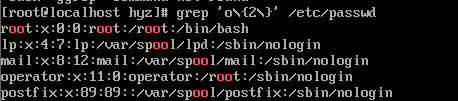
{}内部的数字表示重复出现的次数。**{}两边都要加上转义字符**(这里是我的问题,不应该是{}|这样吗?)。使用{}也可以是一个范围,如{n1,n2},如果其中你n11.1.8过滤出一个或多个指定字符



和grep不同的是,重复出现egrep使用的是+,grep使用的是*,+在grep是不支持使用的。
在egrep里,{}不需要转移符号\,可以直接使用。1.1.9过滤出零个或一个指定字符
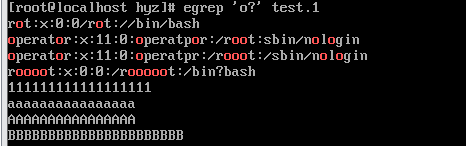
egrep ‘oo?’ test.1

1.1.10过滤字符串
| |可以说是分隔符,寻找多个字符时使用

如果只需找一个字符,则不需要| |,直接用单引号

1.2sed工具的使用
擅长对数据行进行处理,sed是一种流编辑器,处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。利用sed命令可以将数据行进行替换、删除、新增、选取等特定工作。1.21打印某行
![]()
-n 表示只要我们的那一行,其他无关紧要的不打印。

要想把所有行都打印出来,可以用 sed '1,$'p filename

我们也可以打印一个区间
sed -n 'n1,n2’p filename

1.2.2打印包含某个字符串的行
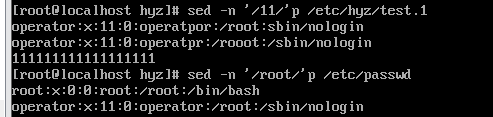
-n 放在后面

1.2.3删除某些行
sed '/字符串/'d filename 删除某个匹配字符串的行
sed 'n1,n2’d filename 删除某个区间的行
这些删除操作都是显示在显示幕上,不会真正的操作到文档里面1.2.4替换字符或字符串
参数s表示替换的意思,参数表示本行全局替换,如果不加g则只替换本行出现的一个个。

除了用分隔符/,还可以用分隔符$或者#,但是不能混搭着来,只能用相同的分隔符。
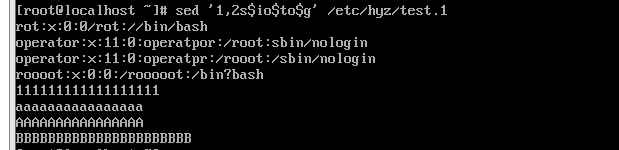
sed 's/[0-9]//g’ filename
与vim的命令还是有些许不同
1.2.5调换两个字符的位置
\3\2\1是先后顺序,本例中将root放在第三位,bash放在第一位

1.26直接修改文件的内容
1.2.7练习题
答:cp etc/passwd /root/test.txt sed -n '1,$,p test.txt
![]()
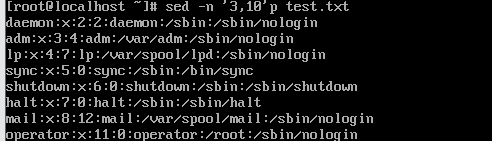
(2)打印text.txt的第三行到第十行
答:sed -n '3,10’p test.txt
(3)打印test.txt包含root的行
答:sed -n '/root/'p /root/test.txt(不是用[ ])

(4)删除text.txt的第十五行以及后面的所有行
答:sed '15,dollar符号’d /root/test.txt
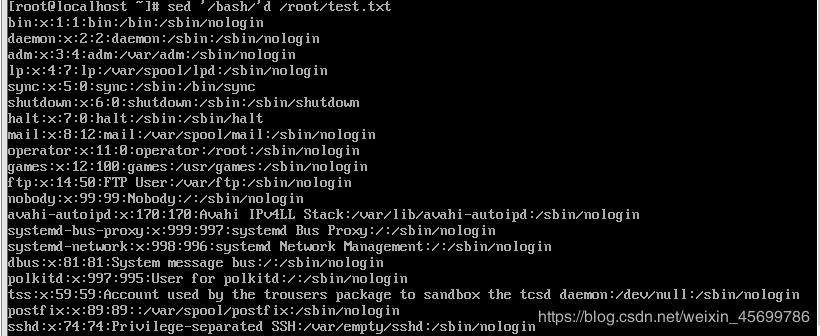
(5)删除test.txt中包含bash的行
答:sed '/bash/'d /root/test.txt
(6)将test.txt中的root替换成toor
答:sed ‘s/root/toor/g’ /root/test.txt

(7)将test.txt中的/sbin/nologin替换为/bin/login
答:sed ‘#/sbin/nologin#sbin/login’ /root/test.txt

(8)删除text.txt中第五行到第十行中所有的数字
答:sed ‘5,10s/[0-9]//g’ /root/test.txt
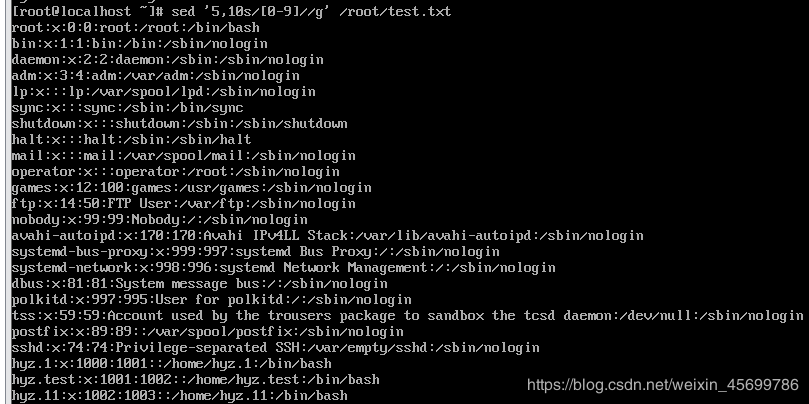
(9)删除test.txt中所有的特殊字符(除了数字以及大小写字母)
答:sed ‘s/[^0-9a-zA-Z]//g’ /root/test.txt

(10)把test.txt中第一个单词和最后一个单词调换位置
答:
(11)把test.txt中第一个数字移动到本行 末尾
答:
(13)在text.txt第二十行到最后一行最前面加aaa
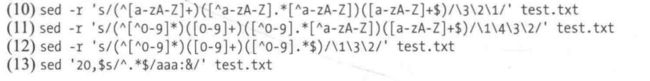
1.3awk工具的使用
awk也是流式编辑器,针对文档中行来操作,擅长对数据列进行处理,就是把数据逐行的读入,以空格为默认分隔符再将每行切断,对切断的部分再进行分析处理。
head -n2 test.txt |awk -F ‘:’ {[print $1}‘
本例中,-F选项的作用是指定分隔符。如果不加-F选项,则以空格或者tab为分隔符。print为打印动作,用来打印某个字段。$1为第一个字段,$0表示整行

注意awk的格式,-F后面紧跟单引号’ ’ ,单引号里面为分隔符。print的动作要用{ } 括起来,否则会报错。print还可以打印自定义的内容,但是自定义的内容要用双引号括起来,例如:

1.3.2匹配字符或字符串

这跟sed的用法类似,能实现grep的功能,但没有颜色显示,肯定没有grep用起来方便,但有比sed更强大的匹配。如:
![]()
它可以让某个段去匹配,这里~是匹配的意思,awk也可以多次匹配。如:
awk -F ‘:’ ‘/root/ {print $1,$3#} /test/ {print $!,$3}’ test.txt

本例中awk匹配完root,再匹配test,它还可以只打印匹配的段。1.3.3条件操作符
![]()
akw中可以中逻辑符号进行旁段,比如==就是i等于,也可以理解为精确匹配。另外还有>、<=、!=等。若把比较的数字用双引号括起来,那么awk不会认为是数字,而会认为是字符。如:
awk -F ‘:’ ‘$3>=“500”’ / etc/passwd
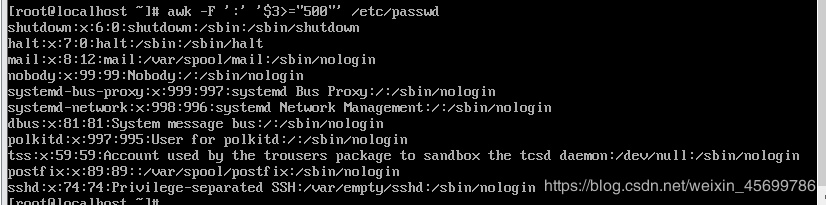
本例中想把uid大于500的打印出来,但因为给500加上了双引号,系统认成字符。如果没有了双引号

1.3.4awk的内置变量
head -5 /etc/passwd |awk -F ‘:’ ‘{OFS=’#’} {print $1,$3,$4}‘

变量NF的具体用法如下:
head -n3 /etc/passwd |awk -F ‘:’ ‘{print NF}’

akw ‘NR>20’ /etc/passwd

NR也可以配合匹配一起使用
awk -F ‘:’ ‘NR<20 &&$1 ~/roo/’ /etc/passwd
![]()
1.3.5zwk中的数学运算

1.3.6awk练习题
答:awk ‘{print $0}’ test.txt(太多了就不截图全部啦)
![]()
(2)查找所有包含bash的行。
答 :awk ‘/bash/’ test.txt

(3)用:作为分隔符,查找第三个字段等于0的行
答:awk -F ‘:’ t$3==“o”’ test.txt
![]()
(4)用:作为分隔符,查找第一个字段为root的行,并把该段的root换成toor。
答:awk -F ‘:’ '$1=“root” test.txt | sed ‘s/root/toor/’
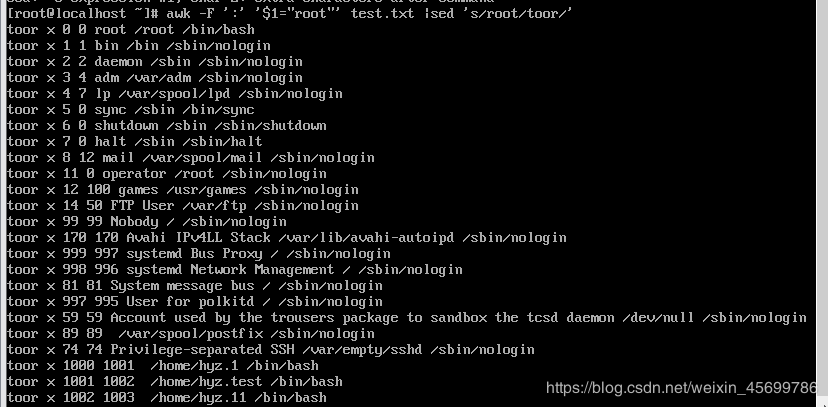
(5)用:作为分隔符,打印最后一个字段
答:awk -F ‘:’ ‘{print $NF}’ test.txt

(6)打印行数大于20的所有行
答:awk -F ‘:’ ‘NR>20’ test.txt

(7)用:作为分隔符,打印所有第三个字段小于第四个字段的行。
答:awk -F ‘:’ ‘$3<$4’ test.txt

(8)用:作为分隔符,打印带一个字段以及最后一个字段,并且用@连接
答:awk -F ‘:’ ‘{print 1 " @ " 1"@" 1"@"NF}’ test.txt

(9)用:作为分隔符,把整个文档的第四个字段相加,求和。
答:awk -F ‘:’ ‘{(sum+=$4)}; END {print sum}’ test.txt
![]()
1.4课后练习题
答:Awk -F ‘:’ ‘$3>=“500”’ /etc/passwd
(2)awk中变量NR和NF分别表示什么含义?命令awk -F ‘:’ ‘{print $NR}’ /etc/passwd会打印出什么结果
答:awk中NF和NR的意义,NF代表的是一个文本文件中一行中的字段个数,NR代表的是这个文本文件的行数;会依次打印对应的行数的段,一直到了最后就打印空行了。
(3)用grep把test.1文档中包含abc或者123的行过滤出来,并在过滤出来的行前面加上行号。
答:grep -n ‘abc’ test.1;grep -n ‘123’ test.1
(4)命令grep -v ‘^‘dollar符号’ 1.txt会过滤出哪些行?
答:会将全部行输出在屏幕上
(5)符号.、.和分别表示什么含义?符号+和?表示什么含义?这五个符号是否可以zz哎grep、egrep、sed以及awk中使用
答:‘.’ 代表匹配任意字符
‘’表示任一个字符(包括0个)
‘+’表示至少一个字符
‘?’表示0个或1个
grep和sed可以使用’.’ 、 '’ 和 ‘.*’,但是不能使用’+‘和’?’ egrep和awk全部可以使用。
(6)grep里面的符号{}用在什么情况下?
答:用在里面是数字、区间或者字符串。
(7) sed有一个选项,可以直接更改文本文件,是哪个选项?
答:sed -i + 操作 +filename
(8)sed -i ‘s/.ie//;s/["|&].//’ file 这条命令表示什么操作呢?
答:
(9)如何删除一个文档中的所有数字或者字母?
答:删除所有字母: sed -i ‘s/[a-Z]//g’ file
删除所有数字: sed -i ‘s/[0-9]//g’ file
(10)截取日志1.log的第一段(以空格为分隔符), 按数字排序、然后去重,但是需要保留重复的数量如何做?
答:awk ‘{print $1}’ 1.log |sort -n|uniq -c|sort -n
(11) 使用awk过滤出1.log中第7段(空格分隔)为’200’ 并且第8段为’11897’的行。
答:awk ‘$7 == “200” && $8 == “11897”’ 1.log
(12)请比较这两个命令的异同: grep -v ‘^【0-9】’ 1.txt 和 grep ‘[0-9]’ 1.txt
答:输出文件中不以数字开头的行,但输出空行;
输出文件中不以数字开头的行,但不输出空行。
(13)awk中的$0表示什么?为什么以下两条命令的$0结果不一致呢?
awk -F ‘:’ ‘{print $0}’ 1.txt 和
awk -F ‘:’ ‘$7=1 {print $0}’ 1.txt
答:打印所有的行;以冒号为分隔符,输出时将每行的第七段的内容更改为1,并打印所有的行
(14)使用grep过滤某个关键词时,如何把包含关键词的行连同上面一行打印出来?联通下面一行也打印呢?同时打印上下各一行呢?
答:
grep -B1 上面一行
grep -A1 下面一行
grep -C1 上下各一行