EfficientNet论文笔记及源码
EfficientNet论文笔记
- 1.EfficientNet论文笔记
- (1)Intrudoction
- (2)Compound Model Scaling
- (3)EfficientNet Architecture
- (4)Experiments
- 2.keras实现代码
- 补充
- 1.collections.namedtuple
- 2.python装饰器
- 3.round_filters
前面在做关于图片分类的项目时,在github上面发现了有的项目用的efficientnet网络结构的效果比较好,网上相关资料较少,找到了论文看一下,顺便记录一下。
论文链接:https://arxiv.org/abs/1905.11946
1.EfficientNet论文笔记
(1)Intrudoction
在论文中,作者介绍了放大卷积神经网络是一种常见的提高模型准确率的方法。但是在传统的方法中,通常只是在某单一维度上进行放大(宽度width,深度depth,图片分辨率resolution),宽度就是网络中的过滤器的数量,因为增加了过滤器的数量,该层的输出的通道数就相应变大了,深度可以理解为整个网络结构的长度,及时网络中layer的数量。那么为什么在这几个维度上进行放大可以提高准确率?因为增加了图片的分辨率或则增加了网络的宽度,网络就能够捕获到更过细节的特征,而增加网络的深度能够捕获到更丰富和更复杂的特征。
虽然也可以任意的放大两个或三个维度,但是因为维度变多,设计空间也随之变大,因此随意的放大多个维度需要耗费较大的人力来调整,并且也通常会一个次优的精度和效率。因此作者通过研究实验提出了一种新的缩放方法——复合缩放方法(compound scaling method)。
下图所展示的便是放大神经网络的几种方法:

但是因为网络结构的缩放并不会改变具体某一层的卷积操作,所以一个良好的基线网络是必须的,作者在论文中也提出了一种新的基线网络结构——EfficientNet。
(2)Compound Model Scaling
然后论文提出问题,并具体介绍一下单独在某个维度进行放大的方法以及他们所提出的复合缩放的方法。
问题描述:卷积网络的第i层可以定义为 Y i = F i ( X i ) Y_i=F_i(X_i) Yi=Fi(Xi),其中 F i F_i Fi是对应的卷积层操作, Y i Y_i Yi是输出张量, X i X_i Xi是输入张量,输入的shape为 < H i , W i , C i >
N = ⨀ i = 1... s F i L i ( X < H i , W i , C i > ) ( 1 ) N=\bigodot_{i=1...s}F_i^{L_i}(X_{
F i L i F_i^{L_i} FiLi表示stage i中 F i F_i Fi层重复了 L i L_i Li次(可以参考ResNet的网络结构);s表示总共有s个stage。
不像规则的ConvNets设计集中在找到最好的网络层 F i F_i Fi,模型缩放的方法是通过length,width或则resolution进行放大但不改变 F i F_i Fi, F i F_i Fi事先已经在基线网络中定义好的(因为缩放不再改变 F i F_i Fi,所以基线网络很重要,这也是作者所说要提出新的网络结构EfficientNet的原因)。虽然通过固定 F i F_i Fi,模型缩放简化了资源约束的设计问题,但是要来探索每一层的 H i , W i , C i , L i H_i, W_i, C_i, L_i Hi,Wi,Ci,Li仍然有很大的设计空间,为了更进一步减小设计空间,作者限制所有层都统一以一个常量比例缩放,目标是在给定资源预算下最大化模型精度,可以描述为如下问题:
max d , w , r A c c u r a c y ( N ( d , w , r ) ) ( 2 ) s . t . N ( d , w , r ) = ⨀ i = 1... s F i ^ d ⋅ L i ^ ( X < r ⋅ H i ^ , r ⋅ W i ^ , w ⋅ C i ^ > ) M e m o r y ( N ) ≤ t a r g e t _ m e m o r y F L O P S ( N ) ≤ t a r g e t _ f l o p s \max_{d,w,r}\quad Accuracy(N(d, w, r))\qquad(2)\\ s.t. \quad N(d, w, r)=\bigodot_{i=1...s}\hat{F_i}^{d\cdot\hat{L_i}}(X_{
其中, d , w , r d,w,r d,w,r分别是网络对于宽度、深度和分别率的缩放系数,而 H i ^ , W i ^ , C i ^ , F i ^ \hat{H_i}, \hat{W_i}, \hat{C_i}, \hat{F_i} Hi^,Wi^,Ci^,Fi^则是在基线网络中预先定义好的参数。
作者接着介绍了单独在某一维度进行缩放:
- Depth(d):缩放网络深度是许多卷积网络中最常用的方法。更深的卷积网络能够捕获到更丰富和复杂的特征,但是更深的网络由于存在梯度消失的问题而难以训练。尽管有一些方法可以解决梯度消失(例如 跨层连接skip connections和批量归一化 batch normalization),但是对于非常深的网络所获得的准确率的增益会减弱。例如ResNet-1000和ResNet-101有着相近的准确率尽管depth相差很大。下图的中间的曲线图表示用不同的深度系数d缩放模型的准确率曲线,并且表明了对于非常深的网络,准确率的增益会减弱。
- Width(w):缩放网络宽度对于小规模的网络也是很常用的一种方式。更宽的网络更够捕捉到更多细节的特征,也更容易训练。很宽但很浅的网络结构很难捕捉到更高层次的特征。下图中左边的曲线图则是作者的不同宽度系数实验结果曲线,当w不断增大的时候,准确率很快就饱和了。
- Resolution(r):使用更高分辨率的图像,网络能够捕获到更细粒度的特模式。下图中右边的曲线图则是作者的不同分辨率系数实验结果曲线,对于非常高分辨率的图像,准确率的增益会减弱。(r=1.0表示224x224,r=2.5表示560x560)。

通过以上实验得出结论1:对网络深度、宽度和分辨率中的任一维度进行缩放都可以提高精度,但是当模型非常大时,这种放大的增益都会减弱。
作者接着引出复合缩放的方法。
- 复合缩放Compound Scaling:作者通过实验发现缩放的各个维度并不是独立的。直观上来讲,对于分辨率更高的图像,我们应该增加网络深度,因为需要更大的感受野来帮助捕获更多像素点的类似特征。为了证明这种猜测,作者做了一下相关实验:比较宽度缩放在不同深度和分辨率之下对准确率的影响。

通过上图的结果我们可以看到d=2.0,r=1.3时宽度缩放在相同flops下有着更高的准确率。
得到结论2:为了达到更好的准确率和效率,在缩放时平衡网络所有维度至关重要。
在本篇论文中,作者提出的新的复合缩放方法使用了一个复合系数 ϕ \phi ϕ,通过这个系数按照以下原则来统一的缩放网络深度、宽度和分辨率:
d e p t h : d = α ϕ w i d t h : w = β ϕ r e s o l u t i o n : γ ϕ s . t . α ⋅ β 2 ⋅ γ 2 ≈ 2 α ≥ 1 , β ≥ 1 , γ ≥ 1 ( 3 ) depth:d=\alpha ^{\phi}\\width:w=\beta ^{\phi}\\ resolution:\gamma^{\phi}\\s.t. \quad \alpha \cdot \beta^2 \cdot \gamma^2\approx2\\ \alpha \geq1,\beta \geq1,\gamma \geq1 \qquad (3) depth:d=αϕwidth:w=βϕresolution:γϕs.t.α⋅β2⋅γ2≈2α≥1,β≥1,γ≥1(3)
其中, α , β , γ \alpha,\beta,\gamma α,β,γ是通过小网格搜索确定的常数,而 ϕ \phi ϕ是一个特定的系数,用于控制模型缩放能够使用资源的使用量。 α , β , γ \alpha,\beta,\gamma α,β,γ说明了怎么分配资源给width,depth,resolution。并且常规的卷积操作的FLOPS(每秒浮点数计算)是和 α , β 2 , γ 2 \alpha , \beta^2, \gamma^2 α,β2,γ2成比例的,加倍深度会使得FLOPS加倍,但是加倍宽度或分辨率会使得FLOPS加4倍。作者得出结论,使用上面的等式(3)来缩放卷积网络,FLOPS会增加 ( α ⋅ β 2 ⋅ γ 2 ) ϕ (\alpha \cdot \beta^2 \cdot \gamma^2)^{\phi} (α⋅β2⋅γ2)ϕ。在本论文中,作者限制 α ⋅ β 2 ⋅ γ 2 ≈ 2 \alpha \cdot \beta^2 \cdot \gamma^2\approx2 α⋅β2⋅γ2≈2,因此对于任意 ϕ \phi ϕ,FLOPS大约增加 2 ϕ 2^{\phi} 2ϕ倍。
(3)EfficientNet Architecture
在论文的这部分作者介绍了他们所提出的新的网络模型——EfficientNet。
下图就是作者所提出的EfficientNet的基线网络结构。

受到MnasNet的启发,作者利用多目标的神经网络结构搜索(能够同时优化精度和FLOPS)来开发基线网络。使用和MnasNet相同的搜索空间并将 A C C ( m ) ACC(m) ACC(m)x [ F L O P S ( m ) / T ] w [FLOPS(m)/T]^w [FLOPS(m)/T]w作为优化目标,其中 A C C ( m ) ACC(m) ACC(m)和 F L O P S ( m ) FLOPS(m) FLOPS(m)分别表示模型m的准确率和FLOPS,T是目标FLOPS,w是用于权衡准确率和FLOPS的超参数,w=-0.07。不像MnasNet中的优化目标,这里优化的是FLOPS而不是延迟,因为没有针对任何特定硬件设备。利用这个搜索方法得到了一个高效的网络——EfficientNet-B0。因为所使用的搜索空间和MnasNet相似,所以得到的网络结构也相似,不过由于FLOPS目标(目标FLOPS为400M)更大,因此EfficientNet-B0也更大一些,其主要构建块就是移动倒置瓶颈MBConv(可以从上面的网络结构图中看到MBConv为主要部分)。
补充:移动倒置瓶颈卷积(MBConv)的主要结构如下图所示,主要有带有SE(squeeze-and- excitation)和不带SE的。MBConv的开始部分(expand phase)和输出部分(output phase)都使用的是1X1卷积核大小的卷积层,括号内的k5x5/k3x3表明了中间深度卷积(DWConv)所使用的卷积核大小

在提出基线网络EfficientNet-B0之后,就可以将前面提出的复合缩放的方法应用在基线网络上,不断放大得到EfficientNet-B1到B7。主要的放大方式如下:
- step1:假设有两倍可利用的资源(相对于未进行放大的基线网络而言),先设 ϕ = 1 \phi=1 ϕ=1,在前面的等式(2)和(3)的基础上对 α , β , γ \alpha,\beta,\gamma α,β,γ进行小范围搜索,最后找到在 α ⋅ β 2 ⋅ γ 2 ≈ 2 \alpha \cdot \beta^2 \cdot \gamma^2\approx2 α⋅β2⋅γ2≈2条件下对于EfficientNet-B0最优的值: α = 1.2 , β = 1.1 , γ = 1.15 \alpha=1.2, \beta=1.1, \gamma=1.15 α=1.2,β=1.1,γ=1.15。
- step2:然后固定 α , β , γ \alpha,\beta,\gamma α,β,γ为常数不变,在式子(3)的基础下通过改变 ϕ \phi ϕ来放大基线网络,从而得到EfficientNet-B1到B7。
(4)Experiments
在实验阶段作者分别分别在已有的卷积网络(MobileNets和ResNets)和本文提出的EfficientNet网络上验证复合放大的方法。
1)下图展示了单维度的缩放和复合缩放在不同卷积网络上对准确率的提高。

2)采用了和MnasNet相似的设置对EfficientNet模型在ImageNet数据集上进行训练:
- RMSProp优化器,decay为0.9,momentum为0.9;
- batch norm momentum为0.99;
- weight decay为1e-5;
- 初始学习率为0.256,并且每2.4个epoches衰减0.97;
- 激活函数使用swish,以及使用固定的增强技术,随机深度( survival probability 为0.8),同时线性地增加dropout比率从EfficientNet-B0的0.2到EfficientNet-B7的0.5。
下表展示了所有通过Efficien-B0缩放的EfficientNet模型的性能,可以看到EfficientNet模型相比其他卷积网络有着更少的参数和FLOPS,但却有着相近的准确率。
其中的top-1和top-5精度的含义:ImageNet数据集有大概1000个分类,而模型预测某张图片时,会给出1000个概率,所谓的Top-1 Accuracy是指排名第一的类别与实际结果相符的准确率(Top-1也就是我们通常所说的精度),而Top-5 Accuracy是指排名前五的类别包含实际结果的准确率(Top-5则范围更大,对于某一个预测结果只要排名前5的概率中包含了实际类别,那么就正确)。

下面两张图分别展示了参数-准确率 和 FLOPS-准确率曲线,其中缩放后的EfficientNet模型都以更少的参数和FLOPS达到了更好的准确率。


3)作者还在一些常用的数据集上进行评估了EfficientNet,通过使用在ImageNet上与训练好的模型,然后在新的数据集上面微调。
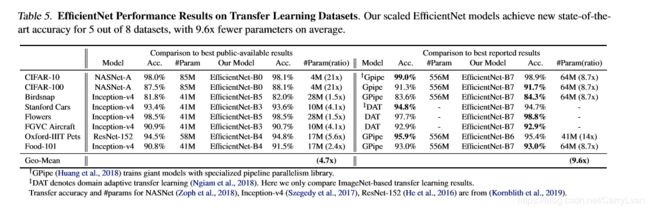
下表展示了EfficientNet去迁移学习的性能:
和公共可用模型相比(例如NASNet-A和Inception-v4),EfficientNet都达到了更好的准确率,但平均参数少了4.7倍(最多相差21倍);和最先进的模型相比(例如DAT和Gpipe),EfficientNet也在下表中8个数据集里的5个达到了最高的准确率,但是少了9.6倍的参数。
2.keras实现代码
完整代码:https://github.com/keras-team/keras-applications/blob/master/keras_applications/efficientnet.py
这里对其中的EfficientNet和EfficientNet-B5简单说一下:
先看到代码(这里代码简化过,完整代码看上方链接):
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import keras
import os
import json
import math
import string
import collections
import numpy as np
from six.moves import xrange
from keras_applications.imagenet_utils import _obtain_input_shape
from keras.applications.imagenet_utils import decode_predictions
from keras.applications.imagenet_utils import preprocess_input as _preprocess_input
backend = None
layers = None
models = None
keras_utils = None
#权重下载地址
BASE_WEIGHTS_PATH = (
'https://github.com/Callidior/keras-applications/'
'releases/download/efficientnet/')
WEIGHTS_HASHES = {
'efficientnet-b5': ('30172f1d45f9b8a41352d4219bf930ee'
'3339025fd26ab314a817ba8918fefc7d',
'9d197bc2bfe29165c10a2af8c2ebc675'
'07f5d70456f09e584c71b822941b1952')
}
#collections.namedtuple创建一个继承tuple的子类,第一个参数是类名,第二个参数是字段名称,即类的各个属性名。
BlockArgs = collections.namedtuple('BlockArgs', [
'kernel_size', 'num_repeat', 'input_filters', 'output_filters',
'expand_ratio', 'id_skip', 'strides', 'se_ratio'
])
#(None,) * len(BlockArgs._fields)的输出结果: (None, None, None, None, None, None, None, None)
BlockArgs.__new__.__defaults__ = (None,) * len(BlockArgs._fields)
#创建每个stage所包含的参数,一共有7个stage
DEFAULT_BLOCKS_ARGS = [
BlockArgs(kernel_size=3, num_repeat=1, input_filters=32, output_filters=16,
expand_ratio=1, id_skip=True, strides=[1, 1], se_ratio=0.25),
BlockArgs(kernel_size=3, num_repeat=2, input_filters=16, output_filters=24,
expand_ratio=6, id_skip=True, strides=[2, 2], se_ratio=0.25),
BlockArgs(kernel_size=5, num_repeat=2, input_filters=24, output_filters=40,
expand_ratio=6, id_skip=True, strides=[2, 2], se_ratio=0.25),
BlockArgs(kernel_size=3, num_repeat=3, input_filters=40, output_filters=80,
expand_ratio=6, id_skip=True, strides=[2, 2], se_ratio=0.25),
BlockArgs(kernel_size=5, num_repeat=3, input_filters=80, output_filters=112,
expand_ratio=6, id_skip=True, strides=[1, 1], se_ratio=0.25),
BlockArgs(kernel_size=5, num_repeat=4, input_filters=112, output_filters=192,
expand_ratio=6, id_skip=True, strides=[2, 2], se_ratio=0.25),
BlockArgs(kernel_size=3, num_repeat=1, input_filters=192, output_filters=320,
expand_ratio=6, id_skip=True, strides=[1, 1], se_ratio=0.25)
]
CONV_KERNEL_INITIALIZER = {
'class_name': 'VarianceScaling',
'config': {
'scale': 2.0,
'mode': 'fan_out',
# EfficientNet actually uses an untruncated normal distribution for
# initializing conv layers, but keras.initializers.VarianceScaling use
# a truncated distribution.
# We decided against a custom initializer for better serializability.
'distribution': 'normal'
}
}
DENSE_KERNEL_INITIALIZER = {
'class_name': 'VarianceScaling',
'config': {
'scale': 1. / 3.,
'mode': 'fan_out',
'distribution': 'uniform'
}
}
def preprocess_input(x, **kwargs):
return _preprocess_input(x, mode='torch', **kwargs)
#swish激活函数
def get_swish(**kwargs):
backend, layers, models, keras_utils = get_submodules_from_kwargs(kwargs)
def swish(x):
if backend.backend() == 'tensorflow':
try:
# The native TF implementation has a more
# memory-efficient gradient implementation
return backend.tf.nn.swish(x)
except AttributeError:
pass
return x * backend.sigmoid(x)
return swish
def round_filters(filters, width_coefficient, depth_divisor):
"""基于宽度系数缩放的过滤器的数量"""
filters *= width_coefficient
new_filters = int(filters + depth_divisor / 2) // depth_divisor * depth_divisor
new_filters = max(depth_divisor, new_filters)
# Make sure that round down does not go down by more than 10%.
if new_filters < 0.9 * filters:
new_filters += depth_divisor
return int(new_filters)
def round_repeats(repeats, depth_coefficient):
"""基于深度系数缩放的重复次数"""
#math.ceil向上取整
return int(math.ceil(depth_coefficient * repeats))
def mb_conv_block(inputs, block_args, activation, drop_rate=None, prefix='', ):
"""移动倒置瓶颈MBConv"""
has_se = (block_args.se_ratio is not None) and (0 < block_args.se_ratio <= 1)
bn_axis = 3 if backend.image_data_format() == 'channels_last' else 1
# Expansion phase
filters = block_args.input_filters * block_args.expand_ratio
if block_args.expand_ratio != 1:
x = layers.Conv2D(filters, 1,
padding='same',
use_bias=False,
kernel_initializer=CONV_KERNEL_INITIALIZER,
name=prefix + 'expand_conv')(inputs)
x = layers.BatchNormalization(axis=bn_axis, name=prefix + 'expand_bn')(x)
x = layers.Activation(activation, name=prefix + 'expand_activation')(x)
else:
x = inputs
# Depthwise Convolution
x = layers.DepthwiseConv2D(block_args.kernel_size,
strides=block_args.strides,
padding='same',
use_bias=False,
depthwise_initializer=CONV_KERNEL_INITIALIZER,
name=prefix + 'dwconv')(x)
x = layers.BatchNormalization(axis=bn_axis, name=prefix + 'bn')(x)
x = layers.Activation(activation, name=prefix + 'activation')(x)
# Squeeze and Excitation phase
if has_se:
num_reduced_filters = max(1, int(
block_args.input_filters * block_args.se_ratio
))
se_tensor = layers.GlobalAveragePooling2D(name=prefix + 'se_squeeze')(x)
target_shape = (1, 1, filters) if backend.image_data_format() == 'channels_last' else (filters, 1, 1)
se_tensor = layers.Reshape(target_shape, name=prefix + 'se_reshape')(se_tensor)
se_tensor = layers.Conv2D(num_reduced_filters, 1,
activation=activation,
padding='same',
use_bias=True,
kernel_initializer=CONV_KERNEL_INITIALIZER,
name=prefix + 'se_reduce')(se_tensor)
se_tensor = layers.Conv2D(filters, 1,
activation='sigmoid',
padding='same',
use_bias=True,
kernel_initializer=CONV_KERNEL_INITIALIZER,
name=prefix + 'se_expand')(se_tensor)
if backend.backend() == 'theano':
# For the Theano backend, we have to explicitly make
# the excitation weights broadcastable.
pattern = ([True, True, True, False] if backend.image_data_format() == 'channels_last'
else [True, False, True, True])
se_tensor = layers.Lambda(
lambda x: backend.pattern_broadcast(x, pattern),
name=prefix + 'se_broadcast')(se_tensor)
x = layers.multiply([x, se_tensor], name=prefix + 'se_excite')
# Output phase
x = layers.Conv2D(block_args.output_filters, 1,
padding='same',
use_bias=False,
kernel_initializer=CONV_KERNEL_INITIALIZER,
name=prefix + 'project_conv')(x)
x = layers.BatchNormalization(axis=bn_axis, name=prefix + 'project_bn')(x)
if block_args.id_skip and all(
s == 1 for s in block_args.strides
) and block_args.input_filters == block_args.output_filters:
if drop_rate and (drop_rate > 0):
x = layers.Dropout(drop_rate,
noise_shape=(None, 1, 1, 1),
name=prefix + 'drop')(x)
x = layers.add([x, inputs], name=prefix + 'add')
return x
def EfficientNet(width_coefficient,
depth_coefficient,
default_resolution,
dropout_rate=0.2,
drop_connect_rate=0.2,
depth_divisor=8,
blocks_args=DEFAULT_BLOCKS_ARGS,
model_name='efficientnet',
include_top=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
**kwargs):
global backend, layers, models, keras_utils
backend, layers, models, keras_utils = get_submodules_from_kwargs(kwargs)
#如果不使用默认权重或者所给权重路径不存在,则报错!
if not (weights in {'imagenet', None} or os.path.exists(weights)):
raise ValueError('The `weights` argument should be either '
'`None` (random initialization), `imagenet` '
'(pre-training on ImageNet), '
'or the path to the weights file to be loaded.')
#如果使用默认权重imagenet,但是包含网络顶部的全连接层但是输出层的神经元不等于原始网络的神经元个数(1000),则报错!
if weights == 'imagenet' and include_top and classes != 1000:
raise ValueError('If using `weights` as `"imagenet"` with `include_top`'
' as true, `classes` should be 1000')
# 返回元祖input_shape,参数data formate默认使用channels_last (None, None, 3)
input_shape = _obtain_input_shape(input_shape,
default_size=default_resolution,
min_size=32,
data_format=backend.image_data_format(),
require_flatten=include_top,
weights=weights)
#img_input为网络的输入tensor
if input_tensor is None:
img_input = layers.Input(shape=input_shape)
else:
if not backend.is_keras_tensor(input_tensor):
img_input = layers.Input(tensor=input_tensor, shape=input_shape)
else:
img_input = input_tensor
#bn_axis为批量归一化的维度,在通道上进行唯一化,所以需要根据数据格式确定
bn_axis = 3 if backend.image_data_format() == 'channels_last' else 1
#激活函数swish
activation = get_swish(**kwargs)
# Build stem
x = img_input
x = layers.Conv2D(round_filters(32, width_coefficient, depth_divisor), 3,
strides=(2, 2),
padding='same',
use_bias=False,
kernel_initializer=CONV_KERNEL_INITIALIZER,
name='stem_conv')(x)
x = layers.BatchNormalization(axis=bn_axis, name='stem_bn')(x)
x = layers.Activation(activation, name='stem_activation')(x)
# Build blocks
num_blocks_total = sum(block_args.num_repeat for block_args in blocks_args)
block_num = 0
for idx, block_args in enumerate(blocks_args):
assert block_args.num_repeat > 0
#对网络的宽度(filters的数量)和深度(每个stage中层重复的次数)分别基于宽度系数和深度系数进行缩放
block_args = block_args._replace(
input_filters=round_filters(block_args.input_filters,
width_coefficient, depth_divisor),
output_filters=round_filters(block_args.output_filters,
width_coefficient, depth_divisor),
num_repeat=round_repeats(block_args.num_repeat, depth_coefficient))
# The first block needs to take care of stride and filter size increase.
drop_rate = drop_connect_rate * float(block_num) / num_blocks_total
x = mb_conv_block(x, block_args,
activation=activation,
drop_rate=drop_rate,
prefix='block{}a_'.format(idx + 1))
block_num += 1
if block_args.num_repeat > 1:
block_args = block_args._replace(
input_filters=block_args.output_filters, strides=[1, 1])
for bidx in xrange(block_args.num_repeat - 1):
drop_rate = drop_connect_rate * float(block_num) / num_blocks_total
block_prefix = 'block{}{}_'.format(
idx + 1,
string.ascii_lowercase[bidx + 1]
)
x = mb_conv_block(x, block_args,
activation=activation,
drop_rate=drop_rate,
prefix=block_prefix)
block_num += 1
# Build top
x = layers.Conv2D(round_filters(1280, width_coefficient, depth_divisor), 1,
padding='same',
use_bias=False,
kernel_initializer=CONV_KERNEL_INITIALIZER,
name='top_conv')(x)
x = layers.BatchNormalization(axis=bn_axis, name='top_bn')(x)
x = layers.Activation(activation, name='top_activation')(x)
if include_top:
x = layers.GlobalAveragePooling2D(name='avg_pool')(x)
if dropout_rate and dropout_rate > 0:
x = layers.Dropout(dropout_rate, name='top_dropout')(x)
x = layers.Dense(classes,
activation='softmax',
kernel_initializer=DENSE_KERNEL_INITIALIZER,
name='probs')(x)
else:
if pooling == 'avg':
x = layers.GlobalAveragePooling2D(name='avg_pool')(x)
elif pooling == 'max':
x = layers.GlobalMaxPooling2D(name='max_pool')(x)
# Ensure that the model takes into account
# any potential predecessors of `input_tensor`.
if input_tensor is not None:
inputs = keras_utils.get_source_inputs(input_tensor)
else:
inputs = img_input
# Create model.
model = models.Model(inputs, x, name=model_name)
# Load weights.
if weights == 'imagenet':
if include_top:
file_name = model_name + '_weights_tf_dim_ordering_tf_kernels_autoaugment.h5'
file_hash = WEIGHTS_HASHES[model_name][0]
else:
file_name = model_name + '_weights_tf_dim_ordering_tf_kernels_autoaugment_notop.h5'
file_hash = WEIGHTS_HASHES[model_name][1]
weights_path = keras_utils.get_file(file_name,
BASE_WEIGHTS_PATH + file_name,
cache_subdir='models',
file_hash=file_hash)
model.load_weights(weights_path)
elif weights is not None:
model.load_weights(weights)
return model
def EfficientNetB1(include_top=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
**kwargs):
return EfficientNet(1.0, 1.1, 240, 0.2,
model_name='efficientnet-b1',
include_top=include_top, weights=weights,
input_tensor=input_tensor, input_shape=input_shape,
pooling=pooling, classes=classes,
**kwargs)
#设置EfficientNetB5的文档字符串(用引号的第一段注释)为EfficientNet的文档字符串
setattr(EfficientNetB1, '__doc__', EfficientNet.__doc__)
"""下面是__init__.py中的代码,合到一起了。
因为在上面网络结构的代码中并没有指定keras的backend等变量,因为keras使用的backend可以是tensorflow,theano等后端。"""
import functools
_KERAS_BACKEND = None
_KERAS_LAYERS = None
_KERAS_MODELS = None
_KERAS_UTILS = None
def get_submodules_from_kwargs(kwargs):
backend = kwargs.get('backend', _KERAS_BACKEND)
layers = kwargs.get('layers', _KERAS_LAYERS)
models = kwargs.get('models', _KERAS_MODELS)
utils = kwargs.get('utils', _KERAS_UTILS)
for key in kwargs.keys():
if key not in ['backend', 'layers', 'models', 'utils']:
raise TypeError('Invalid keyword argument: %s', key)
return backend, layers, models, utils
def inject_keras_modules(func):
import keras
#python装饰器
@functools.wraps(func)
def wrapper(*args, **kwargs):
kwargs['backend'] = keras.backend
kwargs['layers'] = keras.layers
kwargs['models'] = keras.models
kwargs['utils'] = keras.utils
return func(*args, **kwargs)
return wrapper
EfficientNetB1 = inject_keras_modules(EfficientNetB1)
model = EfficientNetB5(weights=None,include_top=False,input_shape=(224, 224, 3),classes=40,pooling=max)
model.summary()
输出的结构即是其网络结构。
补充
1.collections.namedtuple
首先介绍一下namedtuple的用法:collections.namedtuple是一个工厂方法,它可以动态的创建一个继承tuple的子类。跟tuple相比,返回的子类可以使用名称来访问元素。
nametuple一共支持4个参数:def namedtuple(typename, field_names, verbose=False, rename=False):
- typename是类名称;
- field_names字段名,它的值可以是一个能保证元素间顺序不变的可遍历对象或者是逗号链接起来的字符串;
- 第三个参数verbose当为true时,会打印类的定义代码;
- rename默认为False,namedtuple会检查我们传递的属性名称是否符合规范,对于不符合规范的名称会抛出异常。当我们设置rename为True时,将会对不符合规范的名称设置为_$d($d的值为属性设置时候的index)
2.python装饰器
可以参考这篇博客:
理解Python装饰器(Decorator)
3.round_filters
官方解释depth_divisor是网络宽度中的基本单位,因为对filters的数量是有要求的不能随意缩放,需要是基本单位的倍数,如果宽度系数缩放后需要进行相应的调整。代码中的int(filters + depth_divisor / 2) // depth_divisor可以看成:int(int(f)/d+1/2),这个其实就是四舍五入的一个过程,因为//是向下取整,如果小数部分大于0.5也会被舍弃。并且filters的最小值就是一个基本单位depth_divisor。
参考论文:
https://arxiv.org/abs/1905.11946
https://arxiv.org/abs/1807.11626
参考博客:
python中的collections.namedtuple
keras中Conv, SeparableConv2D, DepthwiseConv2D三种卷积过程浅谈