Medical Image Segmetation : #1 D-UNet
D-UNet: a dimension-fusion U shape network for chronic stroke lesion segmentation
Index Terms: MRI, stroke segmentation, deep learning, dimensional fusion.
Abstract:
1. 主要贡献:
1).采用2D和3D CNN 结合的方法,在少于3D network 计算时间的情况下,获得优于2D network 的分割结果。2). 提出新的loss function – Enhance Mixing Loss (EML)。
2. 解决问题:
针对chronic stroke lesion, 在 ATLAS 数据集上获得 DSC= 0.5349±0.2763 和 precision= 0.6331±0.295的结果。
Introduction
1. Challenging:中风发生位置和大小变化很大且边界模糊。1)移动伪影(motion artifacts)影响分割结果。2)lesion位置多变,可发生在cerebrum(大脑), cerebellum(小脑)或者脑部其他部位。同时lesion 形态差异很大,体积从几百到几万立方毫米都存在。3)lesion 边界模糊, 不同医生可能得到的不同lesion区域有差异的label。
2. Recent Solutions: Not clearly
3. Achievements: 1) Dimension-fusion-UNet 结构,基于UNet设计一个downsampling block,该结构将前部分network中3D 和 2D 各自得到的features 融合在进行2D network处理,通过提取3D特征得到优于2Dnetwork的表现。2)Enhanced Mixing Loss: 该损失函数提升了传统Dics Loss的梯度传播,同时结合了Dics loss 和 Focal loss 两者的优点。3)在ATLAS数据集上进行性能验证。
Related works
1. related research directions: ①hand-crafted feature, ②2D-CNN, ③3D-CNN, ④traditional segmentation loss function.
Methods
D-UNet for extracting three-dimensional information :
- architecture:如图1所示

图1, D-Unet结构
在前部分即卷积过程中同时使用3D CNN 和 2D CNN 进行特征提取,然后混合到Dimension Transform Block。之后在进行反卷积操作。其中Dimension Transform Block融合过程如图2所示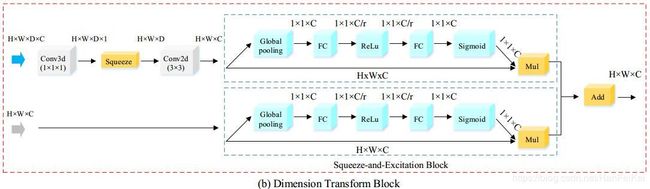
图2 Details of dimension transform block
该结构包括2个输入分别是2D 和 3D 的特征。首先采用1x1x1 3D卷积将3D network 的特征channel压缩为得到channel = 1的序列,然后在由3×3 2D卷积处理压缩序列,再同时对2D 输入特征和处理后的压缩序列进行 SE-block处理,最后把结果加起来。SE-block来源于SE-Net ,可参阅作者讲解。SE 模块如图3所示。
通过 F t r Ftr Ftr(一系列卷积操作)将输入x 的feature channels C 1 C_{1} C1 变换为 C 2 C_{2} C2。接下来进行二个操作对特征通道进行重标定。
① Squeeze 操作: 沿空间维度进行特征压缩,将每个二维的特征通道变为一个实数。其具体实现方式就是采用global average pooling 对每个特征通道 H x W 的二维特征进行处理, Z c = F s q ( U c ) = 1 H × W ∑ i = 1 H ∑ j = 1 W U c ( i , j ) Z_{c}=F_{sq}\left ( U_{c} \right ) = \frac{1}{H\times W}\sum_{i=1}^{H}\sum_{j=1}^{W}U_{c}\left ( i,j \right ) Zc=Fsq(Uc)=H×W1i=1∑Hj=1∑WUc(i,j)
② Excitation 操作:为了对Z (1x1xC) 赋予通道间的相关性----对特征通道增加权重。SE-Net中采用降低特征维度的方式,通过两个全连接层建立通道之间的非线性关系。优点①两个Full connected 比单个可以获得很多非线性,②降维可以极大减少两个Full connected的计算量和参数:
S = F e x ( Z , W ) = σ ( W 2 δ ( W 1 , Z ) ) S = F_{ex}\left ( Z,W \right ) = \sigma \left ( W_{2}\delta \left ( W_{1},Z \right ) \right ) S=Fex(Z,W)=σ(W2δ(W1,Z))
其中 σ \sigma σ表示sigmoid δ \delta δ 表示ReLU。 W 1 ∈ R C r × C W_{1}\in \mathbb{R}^{\frac{C}{r}\times C} W1∈RrC×C, W 2 ∈ R C × C r W_{2}\in \mathbb{R}^{C\times \frac{C}{r}} W2∈RC×rC , r r r表示降维系数
Enhanced Mixing Loss Function
该文结合了两个loss, Focal Loss 和 Dice Coefficient Loss。
Focal Loss :

其中 g ∈ 0 , 1 g \in 0,1 g∈0,1表示图像每个像素的真实值, p ∈ [ 0 , 1 ] p \in [0,1] p∈[0,1] 表示预测值,0表示背景,1表示前景(object)。 N f N_{f} Nf和 N b N_{b} Nb分别表示 foreground 和 background的数量。 α ∈ ( 0 , 1 ] \alpha \in (0,1] α∈(0,1], γ ∈ [ 0 , 5 ] \gamma \in [0,5] γ∈[0,5]。
Dice Coefficient Loss:
D L ( p . g ) = 1 − 2 ∑ i = 1 N p i g i + δ ∑ i = 1 N p i 2 + ∑ i = 1 N g i 2 + δ DL(p.g)=1-\frac{2\sum _{i=1}^{N}p_{i}g{i}+\delta }{\sum _{i=1}^{N}p_{i}^{2}+\sum _{i=1}^{N}g_{i}^{2}+\delta} DL(p.g)=1−∑i=1Npi2+∑i=1Ngi2+δ2∑i=1Npigi+δ
该文结合两种Loss: 提出EML(enhanced mixing loss):

Implementation details:
数据处理:从对角坐标(10,40)到(190,220)裁剪图像,并采用线性插值resize 图片到192x192。再将每个slice,取上层2个slice, 下层1个slice,构成192x192x4的矩阵。网络结构参数列表如下图所示。
Results:
该文采用ATLAS数据集,共229个MRI T1样本,每个样本为233x197x189, 从中随机挑选183个作为训练集,最终给出该模型与2D UNet, 3D UNet 的 DSC , Precision 和 recall结果如下图:

同时也和其它著名模型进行比较,如下图:
