干货|python进阶系列(三)--序列
点击上方“中兴开发者社区”,关注我们
每天读一篇一线开发者原创好文

前面两篇我们分别介绍了python中的装饰器和多继承,了解了一些平时容易踩到的坑以及没能深入理解原理的常见语法。本节我们来介绍一个更基础也更加频繁使用的内容:python的序列。
所谓序列,就是指有序队列(sequence),是程序设计中常用到的数据存储方式。python常用的序列数据类型主要有三种:字符串(string)、元组(tuple)、列表(list),大家在python编码过程中肯定经常接触。但是最基础的内容往往容易被忽略,序列这几个最基础的数据类型中有一些特性需要我们注意,本节主要结合我自己在工作过程中遇到过的问题,来给大家提个醒,避免以后犯类似的错误。
1.索引
序列可以根据变量的下标来定位元素,这是最基础的知识。python所不同的是,支持从序列尾部来进行索引。
_str = "abc"
_tuple = (1, 2, 3)
_list = ['xyz', 4, 'bc']
print _str[1] #b
print _tuple[-1] #3
print _list[0] #xyz
我们知道,元组是不可变序列,列表是可变序列,即元组定义完成后不可以增删改序列内容,但列表可以。那么字符串呢,它是可变还是不可变?我们做个简单的实验即可。
_str = "abc"
_tuple = (1, 2, 3)
_list = ['xyz', 4, 'bc']
_list[0] = 'zte'
# _tuple[-1] = 5
# TypeError: 'tuple' object does not support item assignment
_str[1] = 'd'
# TypeError: 'str' object does not support item assignment
可以看出字符串也是不可变序列,即定义后不可以改变。
另外关于元组的定义,这里有一个陷阱要提醒大家。我们来看下面这个代码片段。
_tuple_a = (1, 2, 3)
_tuple_b= (4)
print _tuple_a[0]
print _tuple_b[0]
# TypeError: 'int' object has no attribute '__getitem__'
运行报错,提醒_tuple_b是int类型,无法索引。稍微思考一下能够发现,这是因为python在运行时将"(4)"当做算术表达式来处理了,把结果4赋值给_tuple_b,因此是一个int型的变量。这里由于int型变量无法通过索引来定位元素,所以编译器会抛出异常,试想一下,如果赋值的元素是字符串的时候会是什么情况呢?请注意,这很危险!
_tuple_a = ('xyz','abc')
_tuple_b = ('xyz')
print _tuple_a[0] #xyz
print _tuple_b[0] #x
由于字符串类型也支持索引,导致代码能够运行,但是结果却是错误的,这给排查问题带来很大的干扰。我曾经在代码中踩过这类坑,某函数入参是元组,传入只有单个元素的“元组”后输出结果不正确,结果花费大量时间来排查问题。
那如果实际需要用到单个元素的元组是如何定义呢?其实也很简单,如下代码段所示,在元素后添加逗号分隔即可。
_tuple_a = ('xyz')
_tuple_b = ('xyz',)
_tuple_c = 'a', 'b'
print _tuple_a, type(_tuple_a) #xyz
print _tuple_b, type(_tuple_b) #('xyz',)
print _tuple_c, type(_tuple_c) #('a', 'b')
更为神奇的是从_tuple_c的定义我们可以看出,定义元组的关键是逗号分隔符,而不是括号。但为了代码的可读性,还是建议使用括号。
2.分片
索引支持定位序列的单个元素,而分片(也称 切片)则能够获取指定范围内的元素。python对分片的支持比较灵活,结合步长可以很方便的处理一个序列,简化操作。
_str = "zte better future"
_list = [1, 2, 3, 4]
_tuple = (5, 6, 7, 8, 9, )
print _str[4:-7] # better
print _list[::2] # [1, 3]
print _tuple[-1::-1] # (9, 8, 7, 6, 5)
需要注意的是,分片返回的是一个新的序列对象。有些同学在初学python时肯定遇到过一类问题:遍历处理列表的过程中改变列表的长度,导致运行报错或者结果不正确。而这个问题正好可以利用分片来处理。
_list = [1, 2, 3, 4]
for i in _list:
if 2 != i:
_list.remove(i)
print _list
#[2, 4]
上面这个示例中,我们的需求是将列表中不等于2的元素删除,但实际结果却和预期的不同(可以简单断点调试,看一下为何最终输出这个结果)。最初我们能想到的解决方法是定义一个临时变量,将_list赋值给它,然后利用临时变量来遍历,修改原来_list列表的元素。
_list = [1, 2, 3, 4]
_temp = _list
for i in _temp:
if 2 != i:
_list.remove(i)
print _list #[2, 4]
print id(_list) #59014728
print id(_temp) #59014728
实际结果仍然错误,打印两个变量的id发现,他们其实指向同一地址。这是因为python序列的赋值其实是对象引用(内存地址)传递,所有对_list和_temp的操作都落到同一个对象上去。此时我们可以利用分片返回新对象的特性,来实现这个功能。
_list = [1, 2, 3, 4]
_temp = _list[:]
for i in _temp:
if 2 != i:
_list.remove(i)
print _list #[2]
print id(_list) #58949192
print id(_temp) #59552456
可以看出此时_list和_temp已经指向不同的对象了。
3.拷贝
接着上述示例,我们再深入了解一下分片的工作原理。我们来看一个稍微复杂一点的例子。
_list = ["null", [1, 2, 3, 4]]
_temp = _list[:]
_temp[0] = "zte"
_temp[1][0] = 3000
print id(_list) # 57778888
print id(_temp) # 57780296
print _list # ['null', [3000, 2, 3, 4]]
print _temp # ['zte', [3000, 2, 3, 4]]
同样是利用分片来拷贝一个新的对象,在修改元素时却发现对_temp[0]的修改没有影响原来的_list,对_temp[1][0]的修改却导致_list的元素也被修改了!这边我画一个简单的示意图,带大家理解分片的原理。
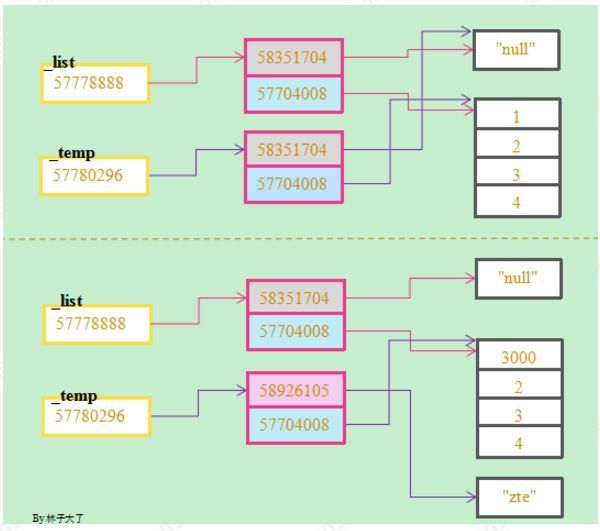
在分片赋值时,将_list指向的内容复制一份给_temp,由于_list存储的是复杂对象(包含字符串和列表),因此拷贝的实际只有目的对象的地址(引用),在改变_temp[0]字符串的内容时,由于字符串是不可变对象,因此_temp[0]存储了新字符串的地址,而_list[0]的内容并未被改变;在更新_temp[1][0]的内容时,实际是变更了57704008这个地址指向的列表的第一个元素,而_list[1]也指向同一个地址,所以最终_list[1]也被更新。
实际上python提供了标准的对象拷贝机制,来处理不同的拷贝需求,分为深拷贝和浅拷贝。我们来比较一下他们的区别。
import copy
_list = ["null", [1, 2, 3, 4]]
_simple = _list
_burst = _list[:]
_shallow_copy = copy.copy(_list)
_deep_copy = copy.deepcopy(_list)
_list[0] = "zte"
_list[1][0] = 3000
print _list # ['zte', [3000, 2, 3, 4]]
print _simple # ['zte', [3000, 2, 3, 4]]
print _burst # ['null', [3000, 2, 3, 4]]
print _shallow_copy # ['null', [3000, 2, 3, 4]]
print _deep_copy # ['null', [1, 2, 3, 4]]
从结果来看,只有深拷贝能做到和原来对象完全无关,而浅拷贝则和分片赋值一样(实际上分片就是浅拷贝的一种方式)。我们再通过简单的图示来了解一下他们的区别。
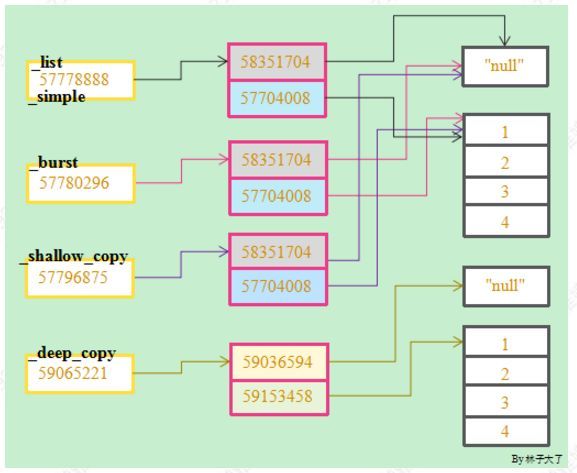
实际上浅拷贝是是指创建一个新的对象,其内容是原对象中元素的引用,但是不拷贝子对象,也就是说新的容器中的地址指向了旧的元素。如果原来的对象是个简单对象,那么浅拷贝就可以达到拷贝的要求,但如果对象又包含其他容器或对象,那么就需要深拷贝来遍历拷贝。所谓深拷贝是指创建一个新的对象,然后递归的拷贝原对象所包含的子对象。深拷贝出来的对象与原对象没有任何关联。
在性能上深拷贝会牺牲时间和空间来保证操作的独立性,但通常来讲性能差别微乎其微。我们在使用复杂对象时一定要注意两类拷贝的区别,避免操作互相干扰。
4.其他操作
序列本身除了索引和分片外还包含一些通用的内置操作,包括操作符和内置函数。我以表格形式整理如下表所示(表格部分内容参考博客Python序列类型)。
操作 |
描述 |
操作 |
描述 |
s+r |
连接操作 |
any(s) |
s中所有项为False则返回False,否则返回True |
s*n, n*s |
制作序列s的n个副本,n为整数 |
len(s) |
长度 |
s[i] |
索引 |
min(s) |
s中的最小项 |
s[i:j:step] |
分片 |
max(s) |
s中的最大项 |
x in s, x not in s |
从属关系,返回值True/False |
sum(s, start) |
s所有项的和加上初值start |
for x in s |
迭代 |
s.count(i) |
s中i出现的次数 |
all(s) |
s中所有项为True则返回True,否则返回False |
s.index(i) |
s中i第一次出现位置的索引 |
列表由于内容和长度可变,有一些特殊的操作,整理如下表所示。
操作 |
描述 |
操作 |
描述 |
s[i] = x |
索引赋值 |
s.insert(i,x) |
将x作为元素插入到s[i]之前 |
s[i:j] = r |
分片赋值 |
s.pop(i) |
移除s[i],默认i=-1 |
del s[i] |
删除元素 |
s.remove(x) |
移除s中第一个元素x |
del s[i:j] |
删除分片 |
s.reverse() |
转制(逆序化)列表s |
s.append(x) |
将x作为元素追加至s的尾部 |
s.sort() |
对s的元素进行升序排序 |
s.extend(x) |
将x扩展至s的尾部 |
s.clear() |
删除s中所有元素 |
其中需要注意的是append和extend的区别,简单的示例了解一下即可。
a = [1, 2, 3]
b = [5, 6, 7]
a.append(b)
print a # [1, 2, 3, [5, 6, 7]]
a.extend(b)
print a # [1, 2, 3, [5, 6, 7], 5, 6, 7]
可以看出,append是将参数作为一个整体追加到列表的尾部,而extend则是将参数展开后一一追加至列表的尾部(请注意,参数展开只有一层,如果参数展开后任然有列表等容器,则不会再次展开)。千万要小心这两个函数的区别,实际开发中经常会遇到错用导致的各类异常。
5.小结
本篇主要介绍了python序列中最常用到的三类数据类型,结合平时工作中踩到过的坑给大家提个醒。在编码过程中一定要小心序列相关操作,尤其是拷贝、扩展、变更列表的过程。另外在确认某些序列是否指向同一对象时,可以利用内置函数id()来打印对象的内存地址,判断是否指向正确的对象。
