更快更简单|飞桨PaddlePaddle显存分配与优化最佳实践
飞桨(PaddlePaddle)为用户提供技术领先、简单易用、兼顾显存回收与复用的显存优化策略,在Transformer、BERT、DeepLabV3+上Max Batch Size性能优于对标开源框架,在YOLOv3、Mask-RCNN模型上显存性能与对标开源框架持平,有兴趣的同学可以试一下,上一组数据先睹为快。

测试条件如下:
-
Paddle version:1.5.0
-
Tensorflow version:1.12.0, 1.14.0
-
Pytorch version:1.0.1, 1.1.0
-
GPU:Tesla V100-SXM2
-
CPU:Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz,38核
-
Nvida driver: 418.39
-
NCCL VERSION:2.4.2
-
CUDNN VERSION:7.4.2.24,7.5.0.56
-
CUDA VERSION:9.0.176,单卡模式
1. 飞桨的显存分配策略
由于原生的CUDA系统调用 cudaMalloc 和 cudaFree 均是同步操作,非常耗时。为了加速显存分配,飞桨采用了显存预分配的策略,具体方式如下图所示:
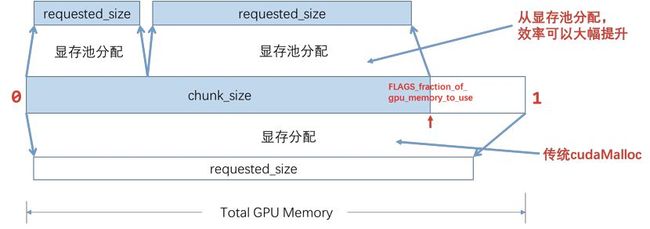
(1)在分配requested_size大小的显存时,先定义一个显存池的大小,记为chunk_size,chunk_size由环境变量 FLAGS_fraction_of_gpu_memory_to_use 确定,表征chunk_size在全部显存的占比,默认值为0.92,即框架预先分配显卡92%的显存。
-
若requested_size<= chunk_size,则框架会预先分配chunk_size大小的显存池chunk,并从chunk中分出requested_size大小的块返回。之后每次申请显存都会从chunk中分配。
-
若requested_size> chunk_size,则框架会直接调用 cudaMalloc 分配requested_size大小的显存返回。
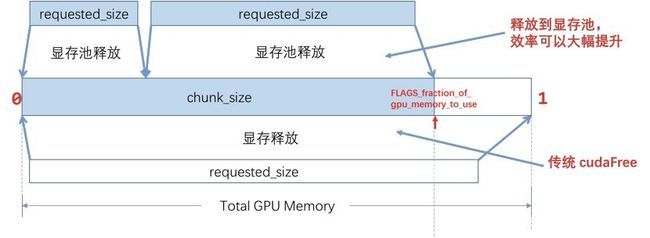
(2)在释放free_size大小的显存时,
-
若free_size<= chunk_size,则框架会将该显存放回预分配的chunk中,而不是直接返回给CUDA。
-
若free_size >chunk_size,则框架会直接调用 cudaFree 将显存返回给CUDA。
注:若GPU卡上有其他任务占用显存,可以适当调整chunk的占比,保证框架能预分配到合适的chunk,比如可以分配40%的显存可以这样设置:
exportFLAGS_fraction_of_gpu_memory_to_use=0.4 # 预先40%的GPU显存提醒:chunk占比应该尽可能大,只有在想测量网络的实际显存占用量时,可以设置该占比为0,观察nvidia-smi显示的显存占用情况。
2. 飞桨的显存优化策略
除了显存预分配,飞桨还提供了多种通用显存优化方法,使得同样网络模型及配置下的显存占用尽可能小,从而可以支持更大batch size的训练,来提升训练效率,下面介绍最重要的两种方法,分别是GC(Garbage Collection)策略和Inplace策略。
2.1. GC策略: 显存垃圾及时回收
GC(GarbageCollection)的原理是在网络运行阶段及时释放无用变量的显存空间,达到节省显存的目的。GC可生效于使用Executor,ParallelExecutor做模型训练/预测时。
GC策略由三个环境变量控制:
(1) FLAGS_eager_delete_tensor_gb
GC策略的使能开关,double类型,默认值为-1。GC策略会积攒一定大小的显存垃圾后再统一释放,FLAGS_eager_delete_tensor_gb 控制的是显存垃圾的阈值,单位是GB。
建议用户设置 FLAGS_eager_delete_tensor_gb=0 。
若 FLAGS_eager_delete_tensor_gb=0 ,则一旦有显存垃圾则马上回收,最为节省显存。
若 FLAGS_eager_delete_tensor_gb=1 ,则显存垃圾积攒到1G后才触发回收。
若 FLAGS_eager_delete_tensor_gb<0 ,则GC策略关闭。
(2) FLAGS_memory_fraction_of_eager_deletion
GC策略的调节flag,double类型,默认值为1,范围为[0,1],仅适用于使用ParallelExecutor或CompiledProgram+with_data_parallel的场合。GC内部会根据变量占用的显存大小,对变量进行降序排列,且仅回收前 FLAGS_memory_fraction_of_eager_deletion 大的变量显存。
建议用户维持默认值,即 FLAGS_memory_fraction_of_eager_deletion=1 。
若 FLAGS_memory_fraction_of_eager_deletion=0.6 ,则表示仅回收显存占用60%大的变量显存。
若 FLAGS_memory_fraction_of_eager_deletion=0 ,则表示不回收任何变量的显存,GC策略关闭。
若 FLAGS_memory_fraction_of_eager_deletion=1 ,则表示回收所有变量的显存。
(3) FLAGS_fast_eager_deletion_mode
快速GC策略的开关,bool类型,默认值为True,表示使用快速GC策略。快速GC策略会不等待CUDAKernel结束直接释放显存。建议用户维持默认值,即 FLAGS_fast_eager_deletion_mode=True 。
2.2 Inplace策略: Op内部的输出复用输入
Inplace策略的原理是Op的输出复用Op输入的显存空间。例如,reshape操作的输出和输入可复用同一片显存空间。
Inplace策略可生效于使用ParallelExecutor或CompiledProgram加with_data_parallel做模型训练和预测,通过 BuildStrategy 设置。
具体方式为:
build_strategy = fluid.BuildStrategy()
build_strategy.enable_inplace =True# 开启Inplace策略
compiled_program =fluid.CompiledProgram(train_program)
.with_data_parallel(loss_name=loss.name, build_strategy=build_strategy)
由于目前设计上的一些问题,打开inplace策略后必须保证后续要fetch的变量为var.persistable = True,这是因为当Inplace策略打开时,非persistable的变量的显存空间可能被其他变量复用,导致fetch结果出错,设置persistable的目的是防止fetch的变量被复用,保证输出结果的正确性。
即:假如你后续需要fetch的变量为loss和acc,则必须设置:
loss.persistable =True
acc.persistable =True
我们正在积极修复该问题,并在下一个release版本中进行修复,并默认打开Inplace策略。
3. 显存优化最佳实践(Best Practice)
我们推荐你的最佳显存优化策略为:
(1)设置预分配显存池:
FLAGS_fraction_of_gpu_memory_to_use=0.92(2)开启GC策略,设置:
FLAGS_eager_delete_tensor_gb=0 。
FLAGS_memory_fraction_of_eager_deletion=1
FLAGS_fast_eager_deletion_mode=True
(3)开启Inplace策略,设置:
build_strategy.enable_inplace= True ,
fetch_list中的
loss.persistable= True
acc.persistable= True
4. 优化策略效果实测
前面我们了解到,GC策略为飞桨的主要显存优化策略,Inplace是一个辅助策略,可在GC策略基础上进一步降低模型显存占用,有利于进一步提高最大batch size。一般而言,使用GC策略能满足您绝大部分模型的显存优化需求;若您仍想进一步提高batch size,建议您打开Inplace策略作为补充。
我们以Transformer模型为例了解一下优化策略的实际效果:
4.1 Transformer模型原理介绍
Transformer 是论文《AttentionIs All You Need》中提出的用以完成机器翻译(machine translation, MT)等序列到序列(sequence to sequence, Seq2Seq)学习任务的一种全新网络结构。其同样使用了 Seq2Seq 任务中典型的编码器-解码器(Encoder-Decoder)的框架结构,但相较于此前广泛使用的循环神经网络(Recurrent Neural Network, RNN),其完全使用注意力(Attention)机制来实现序列到序列的建模,整体网络结构如图1所示。
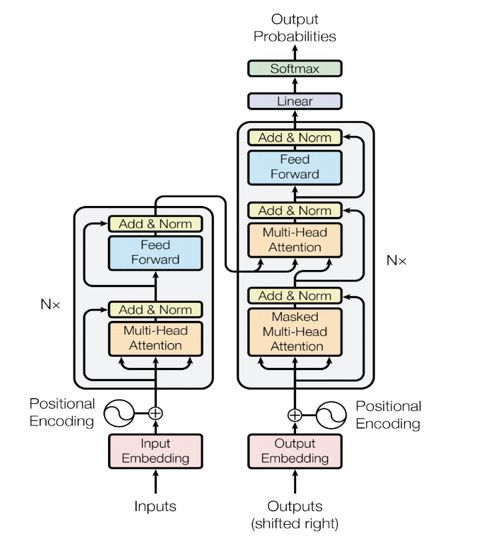
图 1.Transformer 网络结构图
Encoder 由若干相同的layer 堆叠组成,每个 layer 主要由多头注意力(Multi-Head Attention)和全连接的前馈(Feed-Forward)网络这两个 sub-layer 构成。
Multi-Head Attention 在这里用于实现 Self-Attention,相比于简单的 Attention 机制,其将输入进行多路线性变换后分别计算 Attention 的结果,并将所有结果拼接后再次进行线性变换作为输出。参见图2,其中 Attention 使用的是点积(Dot-Product),并在点积后进行了 scale 的处理以避免因点积结果过大进入 softmax 的饱和区域。
Feed-Forward网络会对序列中的每个位置进行相同的计算(Position-wise),其采用的是两次线性变换中间加以 ReLU 激活的结构。
此外,每个 sub-layer 后还施以 Residual Connection 和 Layer Normalization 来促进梯度传播和模型收敛。
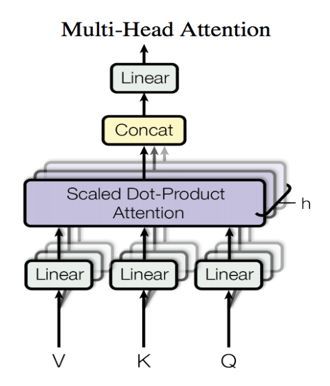
图 2.Multi-Head Attention
Decoder 具有和 Encoder 类似的结构,只是相比于组成 Encoder 的 layer ,在组成 Decoder 的 layer 中还多了一个 Multi-Head Attention 的 sub-layer 来实现对 Encoder 输出的 Attention,这个 Encoder-Decoder Attention 在其他 Seq2Seq 模型中也是存在的。
4.2 显存优化策略在Transformer模型下的实测效果
按照模型建立项目,实际测试一下显存的优化效果,打开Inplace前后,显存占用和最大batch size的变化如下表所示:
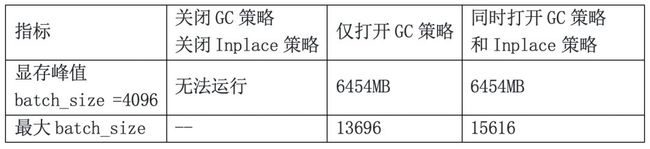
可以看到,打开GC策略对于显存优化的非常重要;虽然Inplace策略在这个实例中对显存峰值没有提升,但可以显著提升最大batch size,也具有实际意义。
如果您加入官方QQ群,您将遇上大批志同道合的深度学习同学,官方QQ群:432676488。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
Transformer项目地址:
https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/neural_machine_translation/transformer?fr=gzh
下载最新版本的 Paddle Fluid v1.5,请点击阅读原文或查看以下链接:
https://www.paddlepaddle.org.cn?fr=gzh
最后给大家推荐一个GPU福利 - Tesla V100免费算力!配合PaddleHub能让模型原地起飞~ 扫码下方二维码申请~

