在上一篇中我们介绍了 MPI-3 中增强的单边通信方法,下面我们将介绍 MPI-3 中共享内存操作。
当前硬件的发展趋势是向着多核(众核)的大(共享)内存方向发展,单台计算节点上的核数越来越多,内存也越来越大。在此情况下,共享内存并行编程模式的优势也越来越显著。经常采用的并行编程模式有 POSIX 线程和 OpenMP。MPI-1 和 MPI-2 标准没有提供共享内存机制,各个进程拥有独立的内存空间,在 MPI-1 中某个进程只能通过显式的消息传递来读取或更改其它进程的数据,MPI-2 引进了单边通信的方法,允许某个进程以远端内存访问(RMA)的方式获取或者更新其它进程开放窗口内的数据,但在本质上各个进程之间的内存空间并不共享,各个进程之间不能以一种常规的加载与存储 (load and store) 的方式直接操作其它进程的内存空间,即使这些内存空间可能存在于同一台节点上。各进程间显式的消息传递和远端内存访问操作都可能需要额外的内存复制,从而降低运算性能和增大内存消耗。为了获得更高的运算性能和降低内存消耗,通常会在 MPI 程序中混合共享内存的机制,如 POSIX 线程或 OpenMP 等。这种集成 MPI 和其它外部编程模型的编程方式会增加编程的复杂性,甚至可能会导致死锁,数据丢失或其它错误结果等。
MPI-3 定义了一种共享内存机制,多个进程可以通过一种共享内存窗口将自己的部分内存空间暴露给其它进程。这是一种可移植的共享内存机制,各进程间共享的内存可以由 CPU 通过直接的 load/store 指令进行获取,就像 POSIX 线程和 OpenMP 等其它共享内存机制一样。这就允许我们在一个统一的编程模型下进行通常的 MPI 操作和共享内存操作,避免混合进外部的共享内存编程模型及其所带来的各种问题,降低编程的复杂度,提高程序的可移植性,且容易与已经存在的 MPI 程序集成。
线程,标准 MPI 和 MPI-3 共享内存的内存共享模型分别如下图所示:
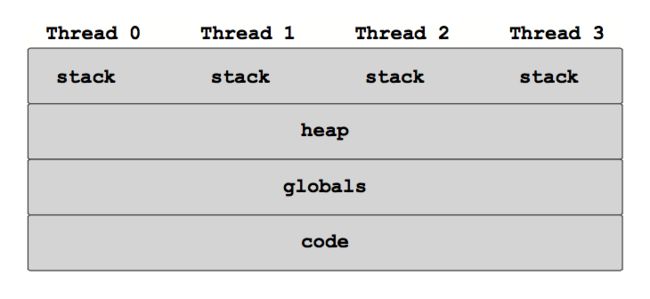
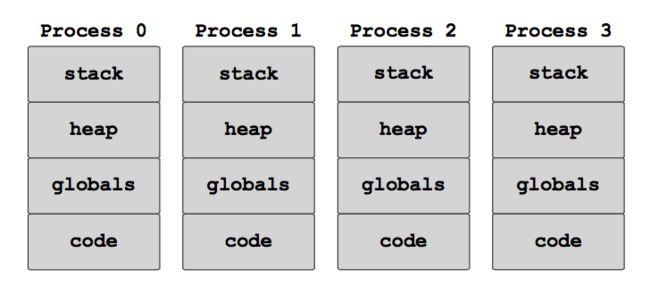
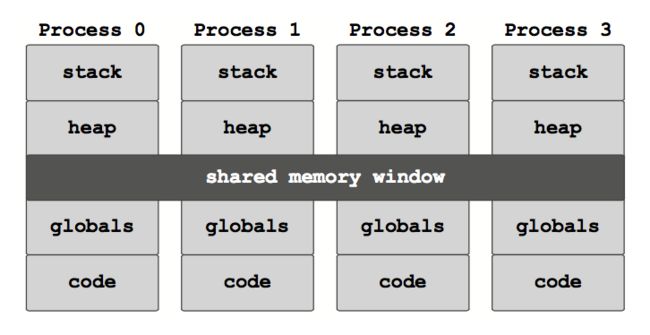
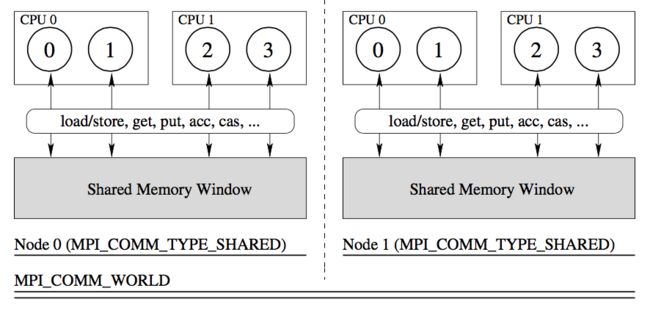
共享内存窗口只能创建在能够共享内存的进程(如处在同一节点上的进程)上,不处在同一个共享内存窗口上的进程之间只能使用标准的 MPI 通信机制,如消息传递或远端内存访问等进行相互之间的数据操作。下图给出这一编程模型的示意图:
方法接口
下面给出 MPI-3 共享内存相关方法接口。
MPI.Comm.Split_type(self, int split_type, int key=0, Info info=INFO_NULL)
根据 split_type 将与当前 comm 相关联的组分解为不相交的子组,并为每个子组创建一个相关联的通信子返回。每个组内进程的 rank 按照 key 参数所指定的方式定义,新通信域中各个进程的顺序编号根据 key 的大小决定,即 key 越小,则相应进程在原来通信域中的顺序编号也越小,若两个进程的 key 相同,则根据这两个进程在原来通信域中的顺序号决定新的编号。该方法是一个集合操作,该通信子内的所有进程的 split_type 参数必须都相同或者为 MPI.UNDEFINED,但是可以提供不同的 key 值。指定 split_type 值为 MPI.UNDEFINED 的进程将返回 MPI.COMM_NULL。MPI 标准定义的 split_type 值只有 MPI.COMM_TYPE_SHARED,表示将当前通信子中的进程分解为可以共享内存(比如进程都在在同一台节点上)的子通信子。各 MPI 实现可能会定义额外的 split_type 值。
MPI.Win.Allocate_shared(type cls, Aint size, int disp_unit=1, Info info=INFO_NULL, Intracomm comm=COMM_SELF)
分配指定大小的共享内存并创建和返回用于单边通信的窗口对象。注意调用该方法的通信子包含的所有进程必须能够操作同一块共享内存(比如说所有进程都处在同一台节点上),否则会出错。在组内通信子 comm 所指定的通信子范围内所有进程上执行集合操作。每个进程所返回的窗口对象会包含一块分配好的 size 大小的共享内存(可以被该通信子内的所有进程访问)。每个进程的 size 可以不同,甚至可以为 0。disp_unit 指定在远端内存访问操作中的地址单位,即 origin 所指定的位置在 target 一侧要以 target 进程所指定的 diap_unit 为单位计算。通常如果采用相同类型创建窗口,则统一将 disp_unit 设置成 1 即可。如果有的进程需要以组合数据类型(type)给出缓冲区,则可能需要指定 disp_unit 为 sizeof(type)。info 对象用于为 MPI 环境提供优化所需的辅助信息。默认情况下,各个进程分配的内存会是一块整体的连续内存区。但是如果设置 info 的 key alloc_shared_noncontig 为 "true",则会分配不连续的内存块。
注意:虽然每个进程可以分配不同大小的内存区域,但是为了提高程序的性能,如果要分配连续的共享内存,通常让单个进程分配此完整的连续内存区,其它进程设置 size 为 0,然后将此连续内存(虚拟地)分配给各个进程。
MPI.Win.Shared_query(self, int rank)
该方法查询 rank 为 rank 的进程通过 MPI.Win.Allocate_shared 方法所分配的内存区在当前进程的地址等信息。对内存中的同一块内存区,该方法对不同的进程可能会返回不同的(虚拟)地址。该方法只能由 flavor 为 MPI.WIN_FLAVOR_SHARED 的窗口对象调用,否则会产生 MPI.ERR_RMA_FLAVOR 错误。该方法会返回由内存缓冲区和偏移单位组成的二元 tuple。当 rank 参数设置成 MPI.PROC_NULL 时,会返回分配内存非 0 的 rank 最小的那个进程的内存缓冲区和偏移单位组成的二元 tuple。
例程
下面给出使用例程。
# shm.py
"""
Demonstrates the usage of MPI-3 shared memory operation.
Run this with 4 processes like:
$ mpiexec -n 4 -host node1,node2 python shm.py
"""
import numpy as np
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
# split the 4 processes into 2 sub-comms, each can share memory
shm_comm = comm.Split_type(MPI.COMM_TYPE_SHARED)
shm_rank = shm_comm.rank
itemsize = MPI.INT.Get_size()
if shm_rank == 0:
nbytes = 10 * itemsize
else:
nbytes = 0
# on rank 0 of shm_comm, create the contiguous shared block
win = MPI.Win.Allocate_shared(nbytes, itemsize, comm=shm_comm)
# create a numpy array whose data points to the shared mem
buf, itemsize = win.Shared_query(MPI.PROC_NULL)
# create a numpy array from buf
buf = np.array(buf, dtype='B', copy=False)
ary = np.ndarray(buffer=buf, dtype='i', shape=(10,))
# in process rank 1 of shm_comm:
# write the numbers 0, 1, 2, 3, 4 to the first 5 elements of the array
if shm_comm.rank == 1:
ary[:5] = np.arange(5, dtype='i')
# wait in process rank 0 of shm_comm until process 1 has written to the array
shm_comm.Barrier()
# check that the array is actually shared and process 0 can see
# the changes made in the array by process 1 of shm_comm
if shm_comm.rank == 0:
print ary
# show non-contiguous shared memory allocation
if shm_rank == 0:
nbytes = 4 * itemsize
else:
nbytes = 6 * itemsize
info = MPI.Info.Create()
info.Set('alloc_shared_noncontig', 'true')
win = MPI.Win.Allocate_shared(nbytes, itemsize, comm=comm, info=info)
info.Free()
运行结果如下:
$ mpiexec -n 4 -host node1,node2 python shm.py
[0 1 2 3 4 0 0 0 0 0]
[0 1 2 3 4 0 0 0 0 0]
以上介绍了 MPI-3 中共享内存操作,在下一篇中我们将介绍 MPI 中多线程的使用。