后面这几章节主要是讲机器学习入门的。机器学习入门这里讲的不够详细、建议听视频课程和可能《机器学习实战》和《统计学习方法》
推荐十分钟速成课-统计学
谎言、该死的谎言与统计学
In [3]: import random
In [4]: def juneProb(numTrials):
...: june48 = 0
...: for trial in range(numTrials):
...: june = 0
...: for i in range(446):
...: if random.randint(1,12) == 6:
...: june += 1
...: if june >= 48:
...: june48 += 1
...: jProb = round(june48/numTrials, 4)
...: print('Probability of at least 48 births in June =', jProb)
...:
In [5]: juneProb(10000)
Probability of at least 48 births in June = 0.0435
In [6]: def anyProb(numTrials):
...: anyMonth48 = 0
...: for trial in range(numTrials):
...: months = [0]*12
...: for i in range(446):
...: months[random.randint(0,11)] += 1
...: if max(months) >= 48:
...: anyMonth48 += 1
...: aProb = round(anyMonth48/numTrials, 4)
...: print('Probability of at least 48 births in some month =',aProb)
...:
In [7]: anyProb(10000)
Probability of at least 48 births in some month = 0.4294
聚类
In [25]: def minkowskiDist(v1, v2, p):
...: """假设v1和v2是两个等长的数值型数组
...: 返回v1和v2之间阶为p的闵可夫斯基距离"""
...: dist = 0.0
...: for i in range(len(v1)):
...: dist += abs(v1[i] - v2[i])**p
...: return dist**(1/p)
...:
In [12]: class Example(object):
...: def __init__(self, name, features, label = None):
...: #假设features是一个浮点数数组
...: self.name = name
...: self.features = features
...: self.label = label
...: def dimensionality(self):
...: return len(self.features)
...: def getFeatures(self):
...: return self.features[:]
...: def getLabel(self):
...: return self.label
...:
...: def getName(self):
...: return self.name
...: def distance(self, other):
...: return minkowskiDist(self.features, other.getFeatures(), 2)
...: def __str__(self):
...: return self.name +':'+ str(self.features) + ':'\
...: + str(self.label)
...:
In [23]: class Cluster(object):
...: def __init__(self, examples):
...: """假设examples是一个非空的Example类型列表"""
...: self.examples = examples
...: self.centroid = self.computeCentroid()
...: def update(self, examples):
...: """假设examples是一个非空的Example类型列表
...: 替换examples;返回发生变化的质心数量"""
...: oldCentroid = self.centroid
...: self.examples = examples
...: self.centroid = self.computeCentroid()
...: return oldCentroid.distance(self.centroid)
...: def computeCentroid(self):
...: vals = pylab.array([0.0]*self.examples[0].dimensionality())
...: for e in self.examples: #计算均值
...: vals += e.getFeatures()
...: centroid = Example('centroid', vals/len(self.examples))
...: return centroid
...:
...: def getCentroid(self):
...: return self.centroid
...: def variability(self):
...: totDist = 0.0
...: for e in self.examples:
...: totDist += (e.distance(self.centroid))**2
...: return totDist
...:
...: def members(self):
...: for e in self.examples:
...: yield e
...:
...: def __str__(self):
...: names = []
...: for e in self.examples:
...: names.append(e.getName())
...: names.sort()
...: result = 'Cluster with centroid '\
...: + str(self.centroid.getFeatures()) + ' contains:\n '
...: for e in names:
...: result = result + e + ', '
...: return result[:-2] #除去末尾的逗号和空格
...:
In [16]: def dissimilarity(clusters):
...: totDist = 0.0
...: for c in clusters:
...: totDist += c.variability()
...: return totDist
In [19]: def trykmeans(examples, numClusters, numTrials, verbose = False):
...: """调用kmeans函数numTrials次,返回相异度最小的结果"""
...: best = kmeans(examples, numClusters, verbose)
...: minDissimilarity = dissimilarity(best)
...: trial = 1
...: while trial < numTrials:
...: try:
...: clusters = kmeans(examples, numClusters, verbose)
...: except ValueError:
...: continue #如果失败,则重试
...: currDissimilarity = dissimilarity(clusters)
...: if currDissimilarity < minDissimilarity:
...: best = clusters
...: minDissimilarity = currDissimilarity
...: trial += 1
...: return best
...:
In [21]: def kmeans(examples, k, verbose = False):
...: #随机选取k个初始质心,为每个质心创建一个簇
...: initialCentroids = random.sample(examples, k)
...: clusters = []
...: for e in initialCentroids:
...: clusters.append(Cluster([e]))
...: #迭代,直至质心不再改变
...: converged = False
...: numIterations = 0
...: while not converged:
...: numIterations += 1
...: #创建一个列表,包含k个不同的空列表
...: newClusters = []
...: for i in range(k):
...: newClusters.append([])
...: #将每个实例分配给最近的质心
...: for e in examples:
...: #找到离e最近的质心
...: smallestDistance = e.distance(clusters[0].getCentroid())
...: index = 0
...: for i in range(1, k):
...: distance = e.distance(clusters[i].getCentroid())
...: if distance < smallestDistance:
...: smallestDistance = distance
...: index = i
...: #将e添加到相应簇的实例列表
...: newClusters[index].append(e)
...: for c in newClusters: #Avoid having empty clusters
...: if len(c) == 0:
...: raise ValueError('Empty Cluster')
...: #更新每个簇;检查质心是否变化
...: converged = True
...: for i in range(k):
...: if clusters[i].update(newClusters[i]) > 0.0:
...: converged = False
...: if verbose:
...: print('Iteration #' + str(numIterations))
...: for c in clusters:
...: print(c)
...: print('') #add blank line
...: return clusters
...:
k均值实验
In [8]: def genDistribution(xMean, xSD, yMean, ySD, n, namePrefix):
...: samples = []
...: for s in range(n):
...: x = random.gauss(xMean, xSD)
...: y = random.gauss(yMean, ySD)
...: samples.append(Example(namePrefix+str(s), [x, y]))
...: return samples
...:
In [9]: def plotSamples(samples, marker):
...: xVals, yVals = [], []
...: for s in samples:
...: x = s.getFeatures()[0]
...: y = s.getFeatures()[1]
...: pylab.annotate(s.getName(), xy = (x, y),
...: xytext = (x+0.13, y-0.07),
...: fontsize = 'x-large')
...: xVals.append(x)
...: yVals.append(y)
...: pylab.plot(xVals, yVals, marker)
...:
In [10]: def contrivedTest(numTrials, k, verbose = False):
...: xMean = 3
...: xSD = 1
...: yMean = 5
...: ySD = 1
...: n = 10
...: d1Samples = genDistribution(xMean, xSD, yMean, ySD, n, 'A')
...: plotSamples(d1Samples, 'k^')
...: d2Samples = genDistribution(xMean+3, xSD, yMean+1, ySD, n, 'B')
...: plotSamples(d2Samples, 'ko')
...: clusters = trykmeans(d1Samples+d2Samples, k, numTrials, verbose)
...: print('Final result')
...: for c in clusters:
...: print('', c)
In [26]: contrivedTest(50, 2, False)
Final result
Cluster with centroid [6.25635098 5.87765296] contains:
B0, B1, B2, B4, B5, B7, B9
Cluster with centroid [3.77477509 5.32003372] contains:
A0, A1, A2, A3, A4, A5, A6, A7, A8, A9, B3, B6, B8
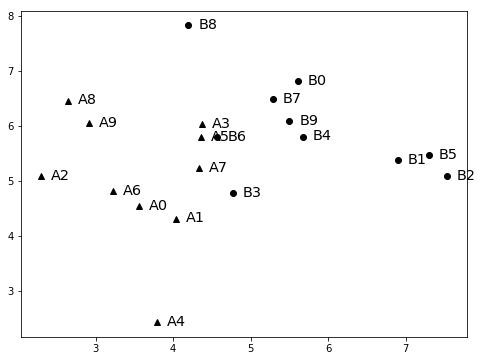
两种分布实例