Spark Streaming 流计算优化记录(3)-控制流量与join的地点
好像之前说过”一下子从Kafka拉取几十万条消息进行处理”的事情, 其实酱紫是不对滴, 饭要一口一口吃, 一下子吃太多, 会导致还没吃成胖子就已经被撑死的. 所以我们要对为了做压力测试而早已在Kafka中囤积多时的几十万条消息分批次进行处理, 毕竟实际跑起的时候每秒拥入
我们知道, Spark Streaming进行流处理的原理是micro batch, 即把每秒或每几秒这个时间窗口内流入的数据切分成几个batch提交到YARN集群上进行处理, 而所切分的batch的大
小是可以调节的, 一般通过配置项” spark.streaming.blockInterval”调节,比如” spark.streaming.blockInterval=500ms”就是把每500毫秒中收集到的数据封装成一个batch .

而对于DirectKafkaInputDStream这种模式, 则是通过配置项” spark.streaming.kafka.maxRatePerPartition”进行调节, “spark.streaming.kafka.maxRatePerPartition=2000”的意思
是每2000条消息作为一个batch进行处理, 当然, 每次一般都会处理多个batch, 而每次的处理量一般等于” maxRatePerPartition * Num of Kafka partitions”, 也就是说, 这里配置的
是每个batch有2000条消息, 而测试用的topic有3个partition, 因此整个程序会每次(如果时间窗口是秒的话, 就是每秒)处理2000 * 3 = 6000条消息.
调节了“spark.streaming.kafka.maxRatePerPartition=2000”之后, 把所有消息处理完所需要的时间也有所缩短, 如下图: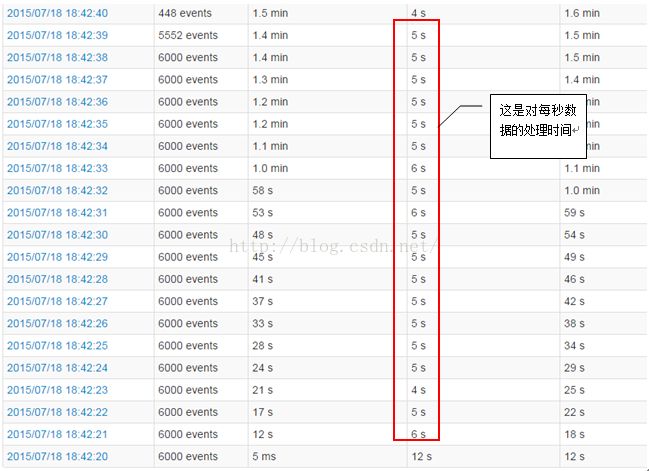
其实调整batch大小表面上看好像限制了处理量, 但实际上如果调不好的话, 就会让集群的OOM频出, executor不断重启, 就像是本来一口一口能够花半小时吃完的饭, 想一口吃完, 结果吃进去后消化不良, 消化了半天才消化完. 因此, 这些参数值得我们依据输入的数据量, 数据的处理量, 处理的复杂度, 资源的多少等, 综合考虑, 不断试验, 也得到一个保险的最优值.
5. 就地Join就好啦,别把数据弄得到处是嘛
背景中提到, 我们需要需要对两个数据流进行join操作, 其实Spark Streaming中提供了方便的方法. 我们可以直接join, 就想酱紫:

其实调用的是介个:

但小心了, 它的默认行为是把kafkaDStream和fileDStream作为mapper side, 另外再找几个executor作为reducer side, 在kafkaDStream, fileDStream 和另外找到的几个reducer三
方之间进行shuffle, 这种情况下, 即使是内存充足, 所引起的网络传输的耗时也不容忽视.
但根据场景可知, 其实kafkaDStream所产生的数据远远不如fileDStream产生的数据, 因此最好能将kafkaDStream的key用与fileDStream同样的分区方式进行分区, 把相应的消息
发送到相应的fileDStream所在的executor中进行join操作, 这样就避免了fileDStream的大量数据的网络传输, 也节省了作为reducer的executor资源.
那么怎样做到呢, 其实Spark的原生方法就可以做到, 但不能直接用DStream, 而需要操作DStream生成的RDD. 如下所示:

DStream.transformWith()方法可以让一个DStream所生成的每一个RDD与另一个DStream所生成的每一个RDD进行交互, 此处是调用了fileRdd的join方法. 但这不是简单的join, 而
是”fileRdd.join(kafkaRdd, fileRdd.partitioner.get)”, 也就是说根据fileRdd.partitioner中的key分区方法进行join, 从而造成了join所基于的key分区策略与fileRdd的key分区策略是一
样的, 在这种情况下, Spark会保持fileRdd中的数据不变, 而是让数据量较少的kafkaRdd进行跨节点的shuffle去join fileRdd中的数据, 减少了shuffle和网络传输.
之后Stage的依赖关系图是酱紫的:
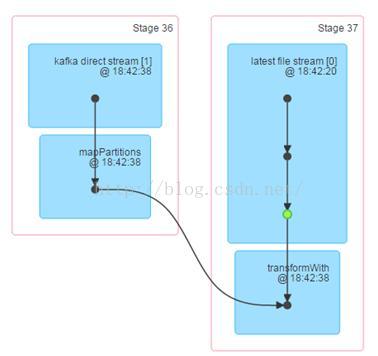
Stage从原有的三个减少到两个, shuffle由两个减少到一个, 只要kafka传入的少量数据是跨节点传输, 而”latest file stream”的数据就呆在原地等待Kafka数据过来join就是了.
“lateset file stream”所在的Stage的RDD关系图如下:
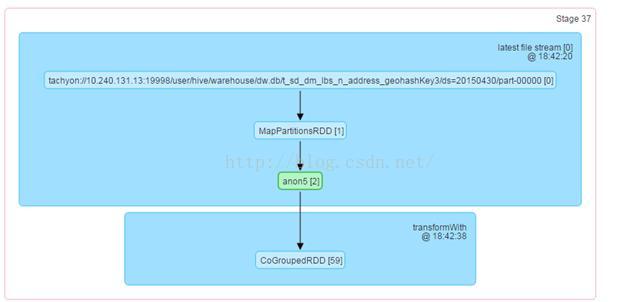
我们看到HDFS加载到内存的数据(绿色的那块)就呆在原有executor不动, 等待Kafka的数据从网卡传来即可.