sys
- 和Python解释器关系密切的标准库
-
sys.__doc__中已经说明了:这个模块提供了对一些对象的访问使用或维护的解释器和交互的功能强的解释 - sys.argv 变量,专门用来向Python解释器传递参数,所以名曰:命令行参数
- sys.exit() 退出当前程序,用这个退出会返回SystemExit异常。(os.__exit()也可以退出)
- sys.path 查找模块所在目录,以列表形式显示出来。append()方法可以新增模块目录
- sys.stdin,sys.stdout,sys.stderr 都是类文件流对象,分别表示标准UNIX概念中的标准输入、标准输出和标准错误。
- 流是程序输入或输出的一个连续的字节序列,设备(例如鼠标、键盘、磁盘、屏幕、调制解调器和打印机)的输入和输出都是用流来处理的。程序在任何时候都可以使用它们。一般来讲,stdin(输入)并不一定来自键盘,stdout(输出)也并不一定显示在屏幕上,它们都可以重定向到磁盘文件或其他设备上。
- print 的本质就是 sys.stdout.write(object + '\n')
- 通过sys.stdout 能够做到将输出内容从‘控制台’转到‘文件’,称之为重定向。
- sys.stdin,sys.stderr 输入和错误 也是类似的。
- copy 分为深拷贝(deepcopy)和浅拷贝(copy)。
对象又类型,变量无类型。变量其实是一个标签
-
浅拷贝
- 用赋值方式实现的拷贝 -- ‘假装拷贝’。内存地址是一样的。
- Python 中只存储基础类型数据(int,str。。。),Python不会再被复制的那个对象中重新存储,而是引用的方式,指向原来的值。即:Python在所执行的复制动作中,如果是基本数据类型,就存在内存中重新分配内存空间,如果不是,就不重新分配,而是用标签来引用原来的内存地址。(比较简单,建内存空间;太复杂就引用原来的)
-
深拷贝
- 会重新分配内存地址
os
- os 提供访问操作系统服务的功能,包含内容比较多。
- 操作文件:重命名文件和修改目录名(
os.rename()),删除文件(os.remove())只能删除单个文件,不能删除文件夹目录 - 操作目录:
- os.listdir 显示目录中的文件(返回值是列表,不显示特殊格式命名文件即隐藏文件)
- os.getcwd,os.chdir 当前工作目录,改变当前工作目录
- os.pardir 获得父级目录
- os.makedirs,os.removedirs 创建和删除目录(删除的目录必须是空的)。如果目录不为空可以用shutil模块的rmtree方法(shutil.retree(path))
- os.rmdir()只能一层层建立目录,而os.makedirs()可以同时建立多层
- 文件和目录属性 os.stat() (st_mtime 是文件修改时间)
- 修改目录属性 os.chmod() 修改权限
- 操作命令
- os.system()是在当前进程中执行命令,直到它执行结束。通过shell执行命令。执行结束后将控制权返回到原来的进程
- 如果需要一个新的进程,可以使用os.exec或者os.execvp 执行结束后不将控制权返回到原进程,从而使Python失去控制。
- 操作文件:重命名文件和修改目录名(
sys.stdout -- 重定向
# f = open('stdout.md','w')
# sys.stdout = f #在这步之后,就意味着输出目的转到了打开(建立)的文件中。
# print('Learn Python')#将内容‘打印’到这个文件中,在控制台就不会显示了。
# f.close()
a = 5
b = a
print(a)
print(id(a))
print(id(b))
5
4540405872
4540405872
ad = {"name":"qiwsir", "lang":"python"}
bd = ad
print(bd)
print(id(ad))
print(id(bd))
{'name': 'qiwsir', 'lang': 'python'}
4584102936
4584102936
cd = ad.copy()
print(cd)
print(id(cd))
{'name': 'qiwsir', 'lang': 'python'}
4584179248
cd['name'] = 'itdiffer.com'
print(ad)
print(bd)
print(bd)
print(id(ad))
print(id(bd))
print(id(cd))
{'name': 'qiwsir', 'lang': 'python'}
{'name': 'qiwsir', 'lang': 'python'}
{'name': 'qiwsir', 'lang': 'python'}
4584102936
4584102936
4584179248
#ad 和 bd 是赋值操作的,所以内存地址是一样的,所以变一个另一个也会变
bd['name'] = 'laoqi'
print(ad)
print(bd)
print(id(ad))
print(id(bd))
{'name': 'laoqi', 'lang': 'python'}
{'name': 'laoqi', 'lang': 'python'}
4584102936
4584102936
如果其中一个值不是基础数据类型,比如是列表,则copy()后字典中的这个列表的内存地址不会改变.
x = {"name":"qiwsir", "lang":["python", "java", "c"]}
y = x.copy()
print(x)
print(y)
print("x = " + str(id(x)))
print("y = " + str(id(y)))
print("x-lang = " + str(id(x['lang'])))
print("y-lang = " + str(id(y['lang'])))
{'name': 'qiwsir', 'lang': ['python', 'java', 'c']}
{'name': 'qiwsir', 'lang': ['python', 'java', 'c']}
x = 4584398064
y = 4584349056
x-lang = 4582969800
y-lang = 4582969800
y['lang'].remove('c')
print(x)
print(y)
print("x = " + str(id(x)))
print("y = " + str(id(y)))
print("x-lang = " + str(id(x['lang'])))
print("y-lang = " + str(id(y['lang'])))
{'name': 'qiwsir', 'lang': ['python', 'java']}
{'name': 'qiwsir', 'lang': ['python', 'java']}
x = 4584398064
y = 4584349056
x-lang = 4582969800
y-lang = 4582969800
深拷贝
import copy
x = {"name":"qiwsir", "lang":["python", "java", "c"]}
y = copy.deepcopy(x)
print(x)
print(y)
print("x = " + str(id(x)))
print("y = " + str(id(y)))
print("x-lang = " + str(id(x['lang'])))
print("y-lang = " + str(id(y['lang'])))
{'name': 'qiwsir', 'lang': ['python', 'java', 'c']}
{'name': 'qiwsir', 'lang': ['python', 'java', 'c']}
x = 4585718480
y = 4585704328
x-lang = 4586882248
y-lang = 4586882312
重命名、删除文件
import os
os.rename('oldname.py','newname.py')
import os
os.remove('/Users/yyf/Desktop/test')
heapq
- 堆(heap)
- 是一种数据结构,通常被看桌一棵树的数组对象。
- 堆的实现是通过构造二叉堆,也就是二叉树
- 二叉树:是每个节点最多有两个子树的树结构,通常子树被称作‘左子树’和‘右子树’。二叉树常被用于实现二叉查找树和二叉堆。最顶对的称为‘根’
- 并不是所有节点都有2个子节点,有可能只有一个或者没有,这类二叉树称为完全二叉树
- 有的二叉树,所有的子节点都有2个子节点,这类二叉树称作满二叉树
- 二叉树特点:
- 节点的值大于等于(或小于等于)任何自己点的值
- 节点左子树和右子树是一个二叉堆。如果父节点的值总大于等于任何一个子节点的值,其为最大堆。若父节点的值总小于等于子节点的值。则为最小堆
- heapq模块
heapq中的heap是堆,q就是queue(队列)的缩写
堆用列表来表示:
heappush(heap,x):将x压入堆heap(这是一个列表)。叫会自动按照二叉树的结构进行存储
heappop(heap):删除最小元素,返回删除的值,最后二叉树会完全按照二叉树规范重新进行排列。
-
heapify():将列表转换成为堆。
- 如果已有一个列表,利用heapify()可以直接将列表转化为堆。可以对堆使用heappop()或heappush()等函数。
-
堆里面不只能放数字
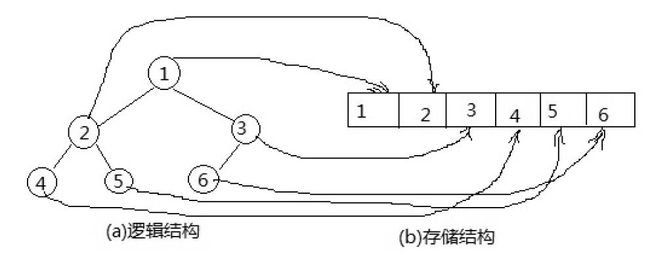 image00328.jpeg
image00328.jpeg
heapreplace() 是heappop()和heappush()的联合,也就是删除一个的同时再加入一个。
deque
- 双端队列 (double - ended queue):
- 需要先把队列转成 deque
- qlst.append() 从右边添加 。
- qlst.appendleft() 从左边添加
- qlst.pop() 从右边删除
- qlst.popleft() 从左边删除
- rotate()
- 将 deque 首位相连,想象成一个圆环,第一个元素是正对你的,旋转后得到的数列。
- 如果list中的是正数,则顺时针旋转
-
负数就逆时针旋转
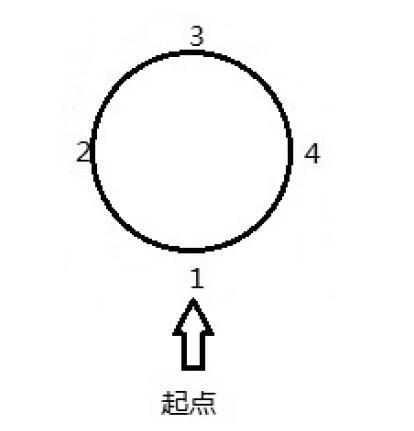 image00331.jpeg
image00331.jpeg
from collections import deque
lst = [1,2,3,4]
qlst = deque(lst)
qlst.append(5) #从右边添加
print(qlst)
qlst.appendleft(7) #从左边添加
print(qlst)
qlst.popleft() #从左边删除
print(qlst)
deque([1, 2, 3, 4, 5])
deque([7, 1, 2, 3, 4, 5])
deque([1, 2, 3, 4, 5])
#
qlst.rotate(3)
print(qlst)
deque([3, 4, 5, 1, 2])

image00332.jpeg
calendar
- calendar(year,w=2,1=1,c=6): 返回一个year年年历,3个月一行,间隔距离为c,每日宽度间隔为w,每行长度为 21w+18+2c, 1是每星期行数。
- isleap(year) : 是否为闰年,是就是True,否是False
- leapdays(y1,y2): 返回在y1-y2两年质检的闰年的总数,包括y1,不包括y2.
- month(year, month, w=2, l=1): year年month月日历,两行标题,一周一行。每日宽度间隔为w字符,每行的长度为7w+61,l是每星期的行数。
- monthcalendar(year, month):返回一个列表,列表内的元素还是列表,这叫嵌套列表。每个星期是一个元素,都是从星期一到星期日,如果没有本月的日期,就用0表示。
- monthrange(year,month):返回一个元组,第一个是代表从这个月的第一天是星期几(从0开是,6代表星期日)。第二个数表示有多少天。
- weekday(year,month,day):输入年月日,知道该日是星期几(0表示星期一,以此类推,6表示星期日)
import calendar
# 2015.2 的日历
cal = calendar.month(2015,2)
print (cal)
February 2015
Mo Tu We Th Fr Sa Su
1
2 3 4 5 6 7 8
9 10 11 12 13 14 15
16 17 18 19 20 21 22
23 24 25 26 27 28
year = calendar.calendar(2015)
print(year)
2015
January February March
Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su
1 2 3 4 1 1
5 6 7 8 9 10 11 2 3 4 5 6 7 8 2 3 4 5 6 7 8
12 13 14 15 16 17 18 9 10 11 12 13 14 15 9 10 11 12 13 14 15
19 20 21 22 23 24 25 16 17 18 19 20 21 22 16 17 18 19 20 21 22
26 27 28 29 30 31 23 24 25 26 27 28 23 24 25 26 27 28 29
30 31
April May June
Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su
1 2 3 4 5 1 2 3 1 2 3 4 5 6 7
6 7 8 9 10 11 12 4 5 6 7 8 9 10 8 9 10 11 12 13 14
13 14 15 16 17 18 19 11 12 13 14 15 16 17 15 16 17 18 19 20 21
20 21 22 23 24 25 26 18 19 20 21 22 23 24 22 23 24 25 26 27 28
27 28 29 30 25 26 27 28 29 30 31 29 30
July August September
Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su
1 2 3 4 5 1 2 1 2 3 4 5 6
6 7 8 9 10 11 12 3 4 5 6 7 8 9 7 8 9 10 11 12 13
13 14 15 16 17 18 19 10 11 12 13 14 15 16 14 15 16 17 18 19 20
20 21 22 23 24 25 26 17 18 19 20 21 22 23 21 22 23 24 25 26 27
27 28 29 30 31 24 25 26 27 28 29 30 28 29 30
31
October November December
Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su
1 2 3 4 1 1 2 3 4 5 6
5 6 7 8 9 10 11 2 3 4 5 6 7 8 7 8 9 10 11 12 13
12 13 14 15 16 17 18 9 10 11 12 13 14 15 14 15 16 17 18 19 20
19 20 21 22 23 24 25 16 17 18 19 20 21 22 21 22 23 24 25 26 27
26 27 28 29 30 31 23 24 25 26 27 28 29 28 29 30 31
30
calendar.monthcalendar(2015, 5)
[[0, 0, 0, 0, 1, 2, 3],
[4, 5, 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23, 24],
[25, 26, 27, 28, 29, 30, 31]]
time
- time 模块很常用,比如记录某个程序运行时间长短。
- time.time():
- 获取当前时间戳
- 转换成时间戳
- localtime():
- 当前时间,需要哪个通过索引取得
- 可以传入时间戳,返回时间戳对应的时间
- gmtime():国际化时间,格林威治时间。
- asctime():
- 得到格式化的时间
- 默认参数是时间元组(localtime()方法的返回值模式)
- ctime():
- 参数默认是time.time()时间戳
- mktime():
- 已时间元组为参数,返回的不是可读性更好的样式,而是时间戳,类似localtime()的逆过程
- strftime():
- 将时间元组按照指定格式要求转化为字符串
- 不指定时间元组,就默认为localtime()的值
- 格式化需要用到下表中的格式
- strptime():
- 将格式化的字符串时间转化为时间元组,
- 参数2个:
- 时间字符串
- 时间字符串对应的格式

image00335.jpeg
import time
time.time() #获取当前时间戳
1512720384.557906
time.localtime()
time.struct_time(tm_year=2017, tm_mon=12, tm_mday=8, tm_hour=15, tm_min=15, tm_sec=50, tm_wday=4, tm_yday=342, tm_isdst=0)
time.gmtime()
time.struct_time(tm_year=2017, tm_mon=12, tm_mday=8, tm_hour=7, tm_min=17, tm_sec=41, tm_wday=4, tm_yday=342, tm_isdst=0)
time.asctime()
'Fri Dec 8 15:18:45 2017'
time.strftime("%y,%m,%d")
'17,12,08'
time.strftime("%y-%m-%d")
'17-12-08'
time.strptime("17-12-08","%y-%m-%d")
time.struct_time(tm_year=2017, tm_mon=12, tm_mday=8, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=4, tm_yday=342, tm_isdst=-1)
datatime
- datetime.date:
- 日期类,常用的属性有year/month/day。
- 生成了一个日期对象,然后操作这个对象
- datetime.time:
- 时间类,生产 time 对象
- 常用的有hour/minute/second/microsecond。
- datetime.datetime:
- 日期时间类。
- 主要用来做时间运算
- datetime.timedelta:
- 时间间隔,即两个时间点之间的时间长度。
- datetime.tzinfo:
- 时区类。
import datetime
today = datetime.date.today()
print('today === %s' %today)
print('today.ctime === %s' %today.ctime())
print('today.timetuple === ' ,today.timetuple())
print('today.year === ' ,today.year) # 年
print('today.month === ' ,today.month) # 月
print('today.day === ' ,today.day) # 日
today === 2017-12-08
today.ctime === Fri Dec 8 00:00:00 2017
today.timetuple === time.struct_time(tm_year=2017, tm_mon=12, tm_mday=8, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=4, tm_yday=342, tm_isdst=-1)
today.year === 2017
today.month === 12
today.day === 8
# 时间戳与格式化时间格式的转换
to = today.toordinal()
print("to ===",to)
print (datetime.date.fromordinal(to))
to === 736671
2017-12-08
import time
t = time.time()
print('t === ',t)
print(datetime.date.fromtimestamp(t))
t === 1512722664.2843149
2017-12-08
# 更灵活的修改日期
d1 = datetime.date(2015,5,1)
print('d1===',d1)
d2 = d1.replace(year = 2017,day = 5)
print('d2===',d2)
d1=== 2015-05-01
d2=== 2017-05-05
urllib
- 已 Python3 为例.
- python3中和Python2 使用中稍微有些区别。2中只需
import urllib,而 3 中需要from urllib import request这样的形式使用。 - 用于读取来自网上服务器的数据,Python爬虫就可以使用这个模块
- urlopen(url,data=None,proxies=None)
- url : 远程数据路径,常是网址
- data : 如果用post 方式请求,这里就是所提交的数据
- proxies : 设置代理
- 常用方法
- read()、readline()、readlines()、fileno()、close():都与文件操作一样,这里不再赘述。
- info():返回头信息。
- getcode():返回http状态码。
- geturl():返回url。
- 对url编码、解码
- url对其中的字符有严格要求,不许可某些特殊字符直接使用某些字符,比如url中有空格,会自动将空格进行处理,这个过程需要对url进行编码和解码。web开发中需要异常注意。
- quote(string[,safe]):对字符串进行编码。参数safe指定了不需要编码的字符。
- request.unquote(string):对字符串进行解码。
- quote_plus(string[,safe]):**需要导入
urllib.parse**.与urllib.quote类似,但这个方法用“+”来替换空格,而quote用“%20”来代替空格。 - unquote_plus(string):对字符串进行解码。**需要导入
urllib.parse**. - urllib.urlencode(query[,doseq]):将dict或者包含两个元素的元组列表转换成url参数。需要导入
urllib.parse。例如{'name':'laoqi','age':40}将被转换为“name=laoqi&age=40”。 - pathname2url(path):将本地路径转换成url路径。
- url2pathname(path):将url路径转换成本地路径。
- urlretrieve(): 虽然urlopen()能够建立类文件对象,但是不能与将远程文件保存在本地存储其中,urlretrieve()可以将远程文件保存在本地的。
- urllib.urlretrieve(url[, filename[, reporthook[, data]]])
- url:文件所在的网址。
- filename:可选。将文件保存到本地的文件名,如果不指定,urllib会生成一个临时文件来保存
- reporthook:可选。是回调函数,当链接服务器和相应数据传输完毕时触发本函数。
- data:可选。用post方式所发出的数据
- 执行完毕,返回的结果是一个元组
- filename 保存在本地的文件名
- headers 服务器响应头信息
- urllib.urlretrieve(url[, filename[, reporthook[, data]]])
from urllib import request
itdiffer = request.urlopen('http://www.baidu.com')
#print(itdiffer.read())
du = 'http://www.baidu.com'
print('编码 --- ',request.quote(du))
from urllib.parse import quote_plus,unquote_plus,urlencode
print('编码 --- ',quote_plus(du))
print('解码 --- ',unquote_plus(du))
print('将本地路径转换成url路径 --- ',request.pathname2url(du))
print('将本地路径转换成url路径 --- ',request.url2pathname(du))
编码 --- http%3A//www.baidu.com
编码 --- http%3A%2F%2Fwww.baidu.com
解码 --- http://www.baidu.com
将本地路径转换成url路径 --- http%3A//www.baidu.com
将本地路径转换成url路径 --- http://www.baidu.com
# 存储一张图片到本地存储器中
def go(a,b,c):
per = 100 * a * b / c
if per > 100:
per = 100
print("%.2f%%" % per)
url = 'https://pic2.zhimg.com/50/6812c133c2010062b5d83b05d3706489_hd.jpg'
local = '/Users/yyf/Desktop/test.jpg'
request.urlretrieve(url, local, go)
0.00%
49.02%
98.04%
100.00%
('/Users/yyf/Desktop/test.jpg', )
urllib2
- urllib2是另外一个模块,它跟urllib有相似的地方——都是对url相关的操作,也有不同的地方。
- Python2的urllib和urllib2与Python3的对应关系
XML
- 定义:
- XML指可扩展标记语言(EXtensible Markup Language)。
- XML是一种标记语言,很类似于HTML。
- XML的设计宗旨是传输数据,而非显示数据。
- XML标签没有被预定义,你需要自行定义标签。
- XML被设计为具有自我描述性。
- XML是W3C的推荐标准。
- 用于传输数据,特别是在web编程中
- xml.dom.* 模块:Document Object Model。合适于处理DOM API。它能够将XML数据再内存中解析成一棵树,然后通过对树的操作来操作XML,但是,犹豫这种方式将XML数据映射到内存中的书,导致比较慢,且消耗更多内存。
- xml.sax.* 模块:simple API for XML.犹豫SAX以流式读取XML文件,从而速度较快,且少占用内存,但是操作上稍复杂,需要用户实现回调函数。
- xml.parser.expat: 是一个直接的,低级一点的基于C的expat的语法分析器。expat 接口基于事件反馈,有点像SAX但又不太像,因为它的接口并不是完全规范与expat库的
- xml.etree.ElementTree(以下简称ET):元素树。它提供了轻量级的Python式的API,相对于DOM,ET快了很多,而且有很多令人愉悦的API可以使用;相对于SAX,ET也有ET.iterparse提供了“在空中”的处理方式,没有必要加载整个文档到内存,节省内存。ET性能的平均值和SAX差不多,但是API的效率更高一点而且使用起来很方便
- python2 和 Python3 有区别

image00337.jpeg
-
常用属性和方法
- Element对象
- 常用属性如下
-tag:string,元素数据种类。- text:string,元素的内容。
- attrib:dictionary,元素的属性字典。
- tail:string,元素的尾形。
- 针对属性的操作如下。
- clear():清空元素的后代、属性、text和tail也设置为None。
- get(key,default=None):获取key对应的属性值,如该属性不存在则返回default值。
- items():根据属性字典返回一个列表,列表元素为(key,value)。
- keys():返回包含所有元素属性键的列表。
- set(key,value):设置新的属性键与值。
- 针对后代的操作如下。
- append(subelement):添加直系子元素
- extend(subelements):增加一串元素对象作为子元素。
- find(match):寻找第一个匹配子元素,匹配对象可以为tag或path。
- findall(match):寻找所有匹配子元素,匹配对象可以为tag或path。
- findtext(match):寻找第一个匹配子元素,返回其text值。匹配对象可以为tag或path。
- insert(index,element):在指定位置插入子元素。
- iter(tag=None):生成遍历当前元素所有后代或者给定tag的后代的迭代器。
- iterfind(match):根据tag或path查找所有的后代。
- itertext():遍历所有后代并返回text值。
- remove(subelement):删除子元素。
- 常用属性如下
2.ElementTree 对象
- find(match)。
- findall(match)。
- findtext(match,default=None)。
- getroot():获取根节点。
- iter(tag=None)。
- iterfind(match)。
- parse(source,parser=None):装载xml对象,source可以为文件名或文件类型对象。
- write(file,encoding="us-ascii",xml_declaration=None,default_namespace=None,method="xml")。 - Element对象
#python2
try:
import xml.etree.cElementTree as ET
except importError:
import xml.etree.ElementTree as ET
#python3
import xml.etree.ElementTree as ET
JSON
- 轻量级数据交换格式
- 结构:
- ‘名称/值’对的集合,不同语言中,它被理解为对象object、记录record、结构struct、字典dictionary、哈希表hashtable、有键列表keyed list 或者关联数组associative array。
- 值的有序列表,在大部分语言中,它被理解为数组
- Python中的标准库中有JSON模块,主要执行序列化和反序列化:
- 序列化:encoding,把一个Python对象编码转化成JSON字符串
- 反序列化:decoding,把JSON格式字符串解码转换为Python数据对象
- encoding:dunmps(): 序列化后元组会变成列表,反序列化后也不会改回来
- decoding:loads()
- 大型JSON解析时需要引入
tempfile临时模块
import json
#序列化
data = [{"name":"qiwsir", "lang":("python", "english"), "age":40}]
print('data == ',data)
data_json = json.dumps(data)
print('data_json == ',data_json)
print('dataType -> ',type(data))
print('data_jsonType -> ',type(data_json))
#反序列化
new_data = json.loads(data_json)
print('new_data == ',new_data)
print('new_dataType -> ',type(new_data))
data == [{'name': 'qiwsir', 'lang': ('python', 'english'), 'age': 40}]
data_json == [{"name": "qiwsir", "lang": ["python", "english"], "age": 40}]
dataType ->
data_jsonType ->
new_data == [{'name': 'qiwsir', 'lang': ['python', 'english'], 'age': 40}]
new_dataType ->
#大JSON字符串
import tempfile
print('data == ',data)
f = tempfile.NamedTemporaryFile(mode='w+')
json.dump(data,f)
f.flush()
print('大JSON字符串 -> ',open(f.name,'r').read())
data == [{'name': 'qiwsir', 'lang': ('python', 'english'), 'age': 40}]
大JSON字符串 -> [{"name": "qiwsir", "lang": ["python", "english"], "age": 40}]