区块链
区块链
文章目录
- 区块链
- 1. 概述
- 2. 比特币
- 2.1 密码学原理
- 2.1.1 比特币使用的哈希函数的性质
- 2.1.2 签名
- 2.2 数据结构
- 2.2.1 Hash pointer
- 2.2.2 merkle tree
- 2.3 比特币的协议
- 2.4 比特币系统实现
- 2.4.1 UTXO
- 2.4.2 比特币区块例子
- 2.4.3 比特币交易的例子
- 2.4.4 出块时间和概率
- 2.4.5 selfish mining
- 2.5 比特币网络
- 2.6 挖矿难度
- 2.7 挖矿
- 2.7.1 挖矿的设备
- 2.7.2 大型矿池
- 2.8 比特币脚本
- 2.8.1 脚本在哪里呢?
- 2.8.2 有几种类型的脚本?
- 2.8.2.1 P2PK(Pay to Public Key)
- 2.8.2.2 P2PKH(Pay to Public Key Hash)
- 2.8.2.3 P2SH(Pay to Script Hash)
- 2.8.2.3 Proof of Burn
- 2.9 分叉
- 3. 以太坊
- 参考资料:
1. 概述
有人说,区块链是最慢的数据库,还有人说是新型商业模式,但是并不是这样的,区块链是一个去中心化的账本,比特币采用的是基于交易的账本模式。
Ps:比特币不等于区块链,比特币只是区块链的一种加密货币。
比特币的价格走向图:

描述:2017年是加密货币价格大爆发的一年,从2017年1月开始暴涨,不要觉得现在去了解区块链算晚了,现在还是区块链发展的早期阶段。
各种加密货币的市场占比:
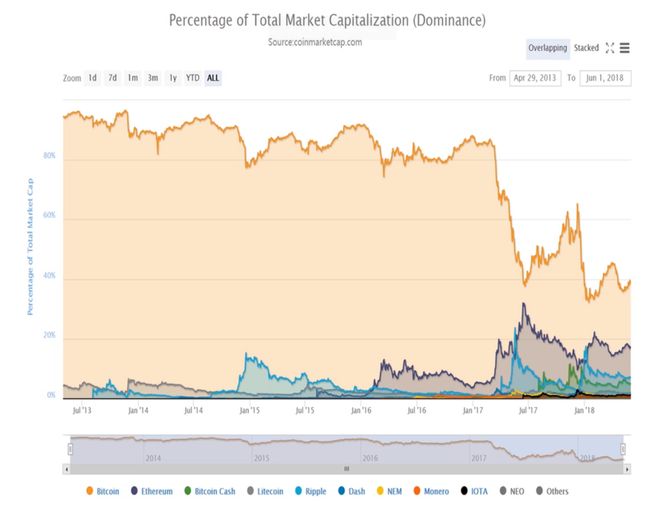
描述:一开始一直是比特币一家独大,从2015年某一天出现以太坊后,各种加密货币都能在市场上占据一定定位,本文也主要说明比特币和以太坊两种加密货币。
课程大纲:


2. 比特币
2.1 密码学原理
比特币主要使用了密码学的两个东西:哈希、签名。
2.1.1 比特币使用的哈希函数的性质
抗碰撞性:
将不同的输入进行哈希后,可能得到相同的结果,这就叫哈希碰撞。
X ≠ Y,H(X) = H(Y)
产生的原因是,输入空间大于输出空间,输入空间是无限的,输出空间为 2256。
在哈希碰撞的情况下,我们发现人为去找两个哈希值相同但是信息不同的数据非常难,所以引出一个概念:抗碰撞性,也就是说,我们可以根据信息的hash值来判断信息是否被篡改过。
PS:常用Hash算法MD5已经被破解了,可以人为制造哈希碰撞。
Hiding:
我们将X进行hash后得到H(X),这个时候想以H(X)反推原数据X目前是无法做到的,这就叫hiding。
X --> H(X),H(X) -//->X
Puzzle friendly:
如果想要得到一个固定类型的Hash值,并且从H(X)推算出X大概落在哪个范围,是不现实的,比如想要得到一个前K位为0,后256-K位为字符串的H(X),去估算X大概的范围,是无法做到的,这就保证了我想得到一个比特币,一定是要付出很大工作量去找满足要求的nonce。
比特币用的Hash函数是:SHA-256(Secure Hash Algorithm)
2.1.2 签名
签名要提到一个概念:非对称加密,用户创建账户后,会获得属于他自己的公钥和私钥,并且公钥和私钥是不一样的,公钥是对外公开的,私钥只有用户自己知道,用户在发起交易后,首先会对交易进行hash,hash后使用用户的私钥进行签名,其他用户可以使用发起交易用户的公钥对这笔交易进行验证签名,这样就可以保证交易不会被伪造,。每个用户的公钥私钥都不相同,这个是通过使用非常好的随机源保证的,如果出现不同用户拥有相同的公钥私钥,那么就全完了。
2.2 数据结构
2.2.1 Hash pointer
区块链使用的是Hash指针,Hash指针不仅保存了数据的地址,还保存了数据的Hash值,保证数据不被篡改。
区块链结构图:
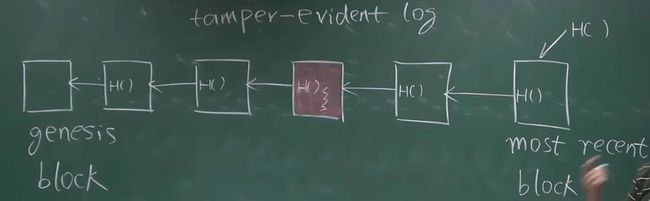
每一个区块含有:自己的数据、上一个区块的Hash指针,Hash指针的Hash值会根据区块的整个内容来进行Hash。这么设计的好处在于可以保护数据不被篡改。当途中红色区块的数据被篡改后,指向它的Hash指针的Hash值就会改变,蝴蝶效应,会导致再下一个区块的Hash值改变…最后导致后面所有的区块的Hash值都会变。
有两种Hash指针:
- 连接区块的Hash指针;
- 记录交易的比特币来源(上一个交易)的Hash指针。
2.2.2 merkle tree
merkle tree的结构:
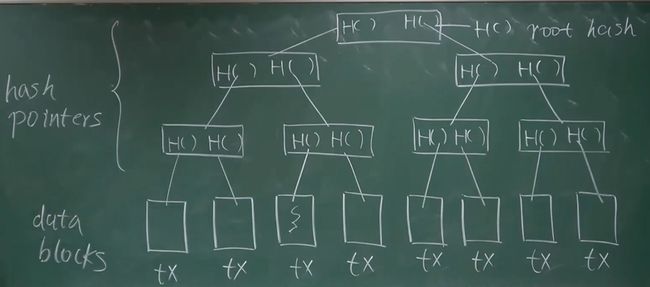
描述:最下面的是一个个交易,将交易两两组合进行Hash,如果交易数为奇数,会复制一个交易凑成偶数,通过一层层Hash,最后得到一个根Hash值,通过判断根Hash值,就可以保证整个merkle tree的交易不被篡改。
区块包括区块头和区块体:
- 区块头
block header包括:- version,比特币协议版本;
- hash of previous block header,前一个区块的hash值;
- merkle root hash,merkle tree根节点的hash值;
- target,挖矿的目标;
- nonce,随机字符串。
- 区块体
block body包括:- transaction list,交易列表
merkle tree 将区块头和区块体连接起来,交易放在区块体,根Hash值放在区块头。
比特币的节点分为两类:
- 轻节点,比如手机的比特币钱包,只包括
block header; - 全节点,包括
block header,block body。
如果轻节点要想要知道特定交易是否已经进入区块链应该怎么做呢?
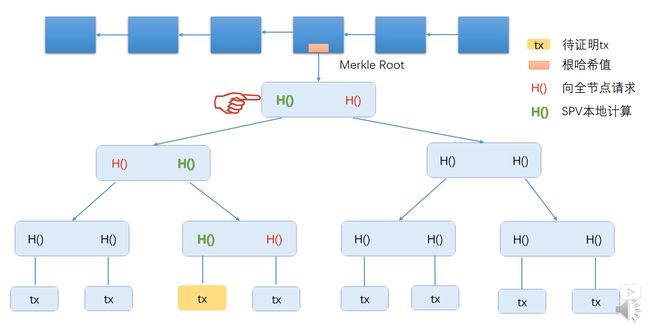
步骤:
- 轻节点向全节点发起请求,从全节点那里拿到途中红色的Hash值;
- 轻节点从交易数据块开始,不断的往上Hash;
- 将计算得到的根Hash值与轻节点记录的Hash值进行比较,如果相等,就证明交易已经进入区块链,如果不相等,那么交易被篡改,没有真正进入区块链。
Ps:使用Hash指针的时候,必须是无环的,如果有环,那么环内每个区块的Hash指针会出现循环依赖的情况,每个区块的Hash指针的Hash值都无法求出来。
2.3 比特币的协议
共识协议:
由于每个用户都有机会获得记账的权利,往区块链中加入新的区块,那么出现了以下几个问题,解决这些问题的方法也就是共识协议:
-
为什么用户会有记账的欲望?
因为用户将满足标准的新区块加入区块链后,会获得奖励,在比特币数量区间为[0,21W]时,一个新区块奖励50比特币,比特币数量区间为[21W,42W]时,一个新区块奖励25比特币,如此往复;用户还会从区块中的交易中抽取一部分当做手续费,这样可以保证用户不会仅仅只将自己的交易打包进区块。
-
其他用户怎么分辨,新加入的区块的交易有没有被篡改?
交易流程图:
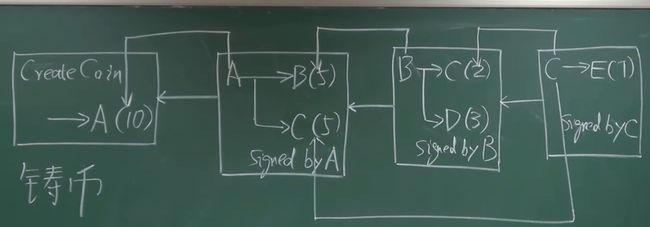
交易大致流程:A获得了10个比特币,在一次交易中,A需要给B和C各转账5个比特币,首先,A通过解析B和C的公钥拿到B和C的收款地址,A在交易里写明对B和C个转5个比特币,接着A使用A的私钥对这笔交易进行了签名且将A的10个币的来源信息进行Hash存进交易里。对于B和C来说,通过使用A的公钥进行解密,可以知道这笔钱是A转过来的;对于BC和其他所有用户,通过验证A的10比特币来源信息的Hash值,从区块链中A获得币的区块开始一步步往下验证交易信息,就可以知道A是不是真正有10个比特币,再通过使用A的公钥进行解密去验证交易的签名,就可以知道这笔交易确实是A发起的。
交易时时刻刻都在发生,只有当交易被打包成区块,收入区块链后,交易才算生效。
新的交易已经可以保证真实可靠了,那么如果有人想篡改区块链中原有的交易会出现什么问题呢?见2.2.1↑。
-
在短时间内,如果同时出现两个用户都添加了新的区块,我们应该选哪一个作为正确的区块?
在用户不断的记账时,可能发生以下情况:
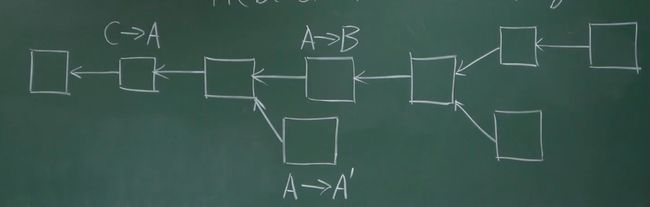
图中一个方块代表一个区块,区块上面的A->B表示的是区块的交易中有一则A转账给B的交易,以此来表示区块的不同。我们可以看到,区块链发生了分叉,在一条链中,新的区块为A转账给B,在另一条链中,新的区块为A转账给A‘,我们应该将哪一个区块作为新的区块呢?为了保证区块链的唯一性,采用最长区块链原则,哪一条区块链最长,就使用哪一条作为区块链,旧的分叉的链就直接抛弃,旧链的奖励也会回滚,所以A转账给B的区块所在的链最长,我们将它记账入区块链。
-
记账成功的概率和什么因素有关?
非常明显,受算力影响,因为挖矿的时候,要不断的计算出符合标准的
nonce随机字符串,要满足整个区块头的Hash值小于target,所以只要你算的快、运气好,就能比别人先一步添加新的区块。
2.4 比特币系统实现
2.4.1 UTXO
UTXO:Unspent Transaction Output,是所有没有被花掉的交易的输出组成的集合。
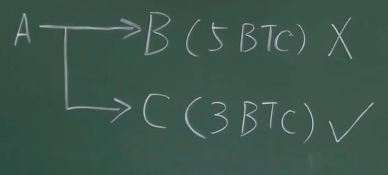
描述:在一个交易中,A转账给B 5个比特币、C 3个比特币,如果B和C都没有将获得的比特币花掉,那么都会进入UTXO集合,但是B花掉了,C没花掉,所以B的记录会从集合中删除,C的记录会保存在集合中。集合中会记录这个交易的Hash值,并且记下C留有3个比特币。
记录这个UTXO集合的目的是,防止二次转账,比如B将获得的5个比特币转给了D,那么B持有5个比特币的记录就会从UTXO集合删掉,这个时候B再想转给E比特币的时候,会因为UTXO集合里面没有B持有比特币的记录而导致交易失败,就防止了二次转账。
2.4.2 比特币区块例子
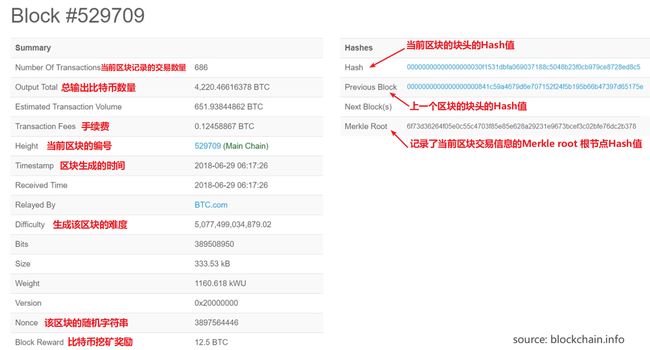
由于现在挖矿的人很多,难度被调得非常高,所以可能会导致nonce就算遍历完了也没办法找到匹配的,这个时候我们还可以通过改变merkle tree里面的铸币交易中的一个域CoinBase去进行调整,Coinbase可以写入任何的内容,这个域里面的内容是没有啥影响的,但是可以增加挖矿的空间范围。
2.4.3 比特币交易的例子
2.4.4 出块时间和概率
比特币系统设定,每隔10分钟出一个新的区块,每次去计算nonce时,都可以看做是一次伯努利实验(Bernoulli trial),意思就是概率和之前的实验是无关的,就相当于抛硬币,每次正面的概率都是50%。这样设定的目的是为了限制算力高的用户挖到矿的概率,不会太高,使挖到矿的概率绝大部分受算力的影响,极少部分受运气的影响。如果不这样设定,让实验次数影响概率的话,算力高的用户挖到矿的概率会随着时间的进行越来越大,就违背了比特币系统的约束。
2.4.5 selfish mining
selfish mining 的意思是指,用户挖到矿以后,不发布,而是接着继续挖矿,最后挖出来的链比现在区块链要长的时候,一次性发布出来,替代区块链中现有的链。这种攻击方式显然是不显示的,因为需要非常高的算力,当一个用户的算力比比特币系统总算力的50%要多的时候,用户可以随意篡改区块链,那么这么牛逼的用户可以利用这个机制干什么呢?在目前现有的链里面M向A付款5个比特币,并且由于写入了区块链,M在现实生活中拿到了A付出的3W美金,但是M呢又自己挖了一个区块,自己挖的区块里面是没有向A付款的,接着M利用自己的算力不断挖矿,挖到比现有的区块链长的时候,M发布所有区块,这个时候区块链回滚,M付给A的5个比特币又回到了M手上,但是M玩起了消失,不将5W美金还给A。
这么大的算力是不现实的,如果出现了这么大的算力,区块链就木得了,对于M不还钱的线下行为,线上是没办法管理的,但是线上能做一些交易确认的处理。对于一些别的情况,比如在区块链分叉的刚开始,就分了两个区块,不知道选哪一个作为真正的区块的时候,区块链有确认机制保证交易安全–confirmation,当新的区块进入区块链后,会记录confirmation的值,一个新区块confirmation值就加一,直到在这个区块后增加了6个新的区块,confirmation = 6,才能保证这个区块是安全的、不可篡改的。
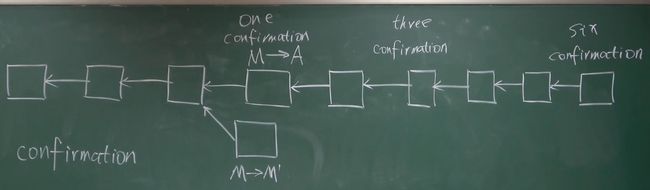
2.5 比特币网络
比特币系统的结构:
- 比特币的应用层:区块链;
- 比特币的网络层:P2P覆盖网络,所有节点都是平等的,没有超级节点(Super node/ Master node),节点之间通过种子节点来找到位置,再通过PCP协议进行通信。
比特币的设计原则是:简单、鲁棒、非高效。
交易在比特币网络如何发布?
比特币网络中每个节点都要维护一个等待上链的交易的集合,第一次听到一个合法交易的时候,将这个交易加入等待集合,再将交易随机转发给其他邻近节点,以后再收到同一个交易的时候,就不会再转发了。有可能会出现恶意节点发布双重消费的交易,就是A转账给B,A又将同一笔比特币转账给C,每个节点由于网络的位置不同,可能会收到不同的交易记录,比如D收到了A转账给B的交易,E收到了A转账给C的交易。由于交易还没有被打包上链,那么对于D来说,先收到A转账给B,是合法的,再收到A转账给C就知道是不合法的,就不将A->C的交易记录入D的交易等待集合了;对于E来说,先收到A->C的交易,再收到A->B的交易就认为是不合法的了。如果这个时候新发布了一个区块,区块中记录了A->B的交易,那么D就会将A->B的交易删除,因为已经入链不需要再保存,E会将A->C的交易删除,因为不合法。
区块在比特币网络如何发布?
和交易的类似,每个节点都要确定区块内的交易是不是合法,并且要判断区块是不是在最长合法链上,越是大的区块在网络上就传输得越慢,所以比特币网络对区块大小做了限制:1M。
比特币网络中的节点分类:
- 全节点;
- 一直在线;
- 在本地硬盘上维护完整的区块链信息;
- 在内存里维护UTXO集合,以便快速验证交易的正确性;
- 监听比特币网络的交易信息,验证每个交易的合法性;
- 决定哪些交易会被打包在区块里;
- 监听别的矿工挖出来的区块,验证其合法性;
- 挖矿,决定沿着哪条链挖下去、分叉时选择分叉。
- 轻节点。
- 不是一直在线;
- 不需要保存整个区块链,只需要保存每个区块的区块头;
- 不用保存全部交易,只保存与自己相关的交易;
- 只能验证与自己相关交易的合法性,其余的交易无法验证;
- 无法验证新的区块的正确性;
- 可以验证挖矿难度;
- 只能检测出最长链,但是不知道哪条是最长合法链。
2.6 挖矿难度
挖矿就是不断调整block header里面的nonce值,使整个block header的hash值小于等于目标阈值,比特币使用的hash算法是 SHA-256,产生的hash值是256位,所以整个输出空间是2256。
H(block header) ≤ target
调整挖矿难度就是调整目标空间在整个输出空间所占比例。
为什么我们要调整挖矿难度?
- 如果不调整挖矿难度,控制出块时间为10分钟的话,随着参与挖矿游戏的用户越来越多,出块的时间就会越来越短,出块时间越来越短就会导致分叉成为常态,甚至可能出现几十个分叉,对于系统达成共识是没有好处的;
- 比特币系统是假设大部分算力掌握在诚实的矿工手里的,分叉越多,会导致系统中的诚实矿工的总算力被分散了,如下图,假设A->B的交易后出了6个新块,那么A->B的交易就会被确认,这个时候恶意矿工开始从A->B交易的前一个块开始挖恶意的区块,由于诚实矿工总算力被分去确认原区块链上的最长链了,那么就会导致恶意矿工的算力不需要超过系统的50%,只需要比别的诚实的矿工速度快就可以对系统进行攻击。

比特币协议中规定,每个2016个区块,就会调整一下目标阈值,大概是每两个星期调一次,难度调节公式: t a r g e t = t a r g e t × a c t u a l t i m e e x p e c t e d t i m e target\ =\ target\ \times\ \frac{actual\ time}{expected\ time} target = target × expected timeactual time ,注意分母的expectedtime是2016*10分钟,actualtime是产生2016个区块的时间,target越大,出块越容易,target被设定一次最多增加或减少4倍。
注意:目标阈值不是挖矿难度,目标阈值只是反映了挖矿难度,目标阈值和挖矿难度成反比,挖矿难度的计算公式: n e x t _ d i f f i c u l t y = p r e v i o u s _ d i f f i c u l t y × 2 w e e k s t i m e t o m i n e l a s t 2016 b l o c k s next\_difficulty\ =\ previous\_difficulty\ \times\ \frac{2\ weeks}{time\ to\ mine\ last\ 2016\ blocks} next_difficulty = previous_difficulty × time to mine last 2016 blocks2 weeks,实际比特币代码里算的是目标阈值。
2.7 挖矿
2.7.1 挖矿的设备
挖矿设备的演化趋势是越来越专业化,从每个人的电脑都使用的CPU挖矿,到后来更适合的GPU挖矿,再到出来一款只能挖矿、专业挖矿的芯片ASIC。为啥要从CPU换成GPU呢,因为使用CPU挖矿,我们电脑上有很多其他资源比如硬盘、一些其他的部件是闲置的,所以划不来,GPU适合通用并行计算,里面有很多负责运算的部件,所以效率比CPU挖矿高很多;从GPU到ASIC是因为,GPU挖矿时,还是有很多部件用不上,比如负责浮点数计算的部件,很适合深度学习计算,但是挖矿用不上;ASIC的产生就是专门为了挖比特币矿的。
随着挖矿的竞争越来越激烈,ASIC芯片也会不断的更新,会出现更好的矿机打败它,所以购买ASIC矿机的时间也很重要,算力是不断变化的,而且一些提供新型强力矿机的厂商做出来后不会马上交货给矿工,会自己先用着挖矿,等挖了2个月了,再给矿工,导致矿工挖矿的风险很大。
2.7.2 大型矿池
由于算力很容易掌握在一少部分人手中,所以单干的矿工获得奖励的几率就更低,风险就更大,大型矿池就成为了趋势。
矿池就是将一些分散的算力集合起来,为矿主打工,在挖出框后,根据每个矿工的工作量去分配获得的比特币,确定矿工工作量是根据每个矿工提供的接近target的nonce数量确定的,矿主会个每一位矿工分配一个范围的nonce区间,并且在merkle tree的coinBase域的收款参数会填上矿主的收款地址,这使得矿工不可以挖到矿后自己找别的全节点发布,因为收款地址对不上就取不出比特币来。
矿池的优点:减少了矿工的经济风险,以前没有矿池的时候,矿工可能2年才能挖出一个区块,也可能2年都挖不到,有了矿池后,矿工可能每天都能得到分红。
矿池的缺点:增加了51%攻击的风险,因为每个矿工都是接受了矿主分配的任务,并且一个机构可能拥有很多个矿池,这使得有一些矿工可能在不知情的情况下去帮矿主干坏事。
2.8 比特币脚本
比特币有自己的脚本语言,主要是为了验证交易的真实性,但是也有一些用户用脚本语言去记录一些知识产权等等,想把这些记录加入区块链中。交易的脚本分为两类:input scripts和output scripts,每个交易都有这两个脚本,交易的输入脚本要和上一笔交易的输出脚本匹配,说明交易真实有效,如果不匹配,交易非法无效。
比特币的脚本语言是基于栈的,也就意味着,脚本中最上面的程序,最晚被执行。
2.8.1 脚本在哪里呢?
脚本肯定在交易里,那么我们从交易的结构入手,慢慢往脚本进行推导。
交易结构:

交易结构中vin的结构:

交易结构中vout的结构:

所以交易的输入和输出脚本就在交易结构里的vin和vout中。
2.8.2 有几种类型的脚本?
2.8.2.1 P2PK(Pay to Public Key)
使用下面的例子,来对P2PK的脚本进行讲解。
当前交易的输入脚本:

上一笔交易的输出脚本:

脚本执行:

实例:

2.8.2.2 P2PKH(Pay to Public Key Hash)
使用下面的例子,来对P2PKH的脚本进行讲解,这个脚本与上面P2PK的脚本相比,在输出脚本里,没有直接给出上一笔交易的收款人的公钥,而是给的公钥的Hash值。
当前交易的输入脚本:

上一笔交易的输出脚本:

脚本执行:
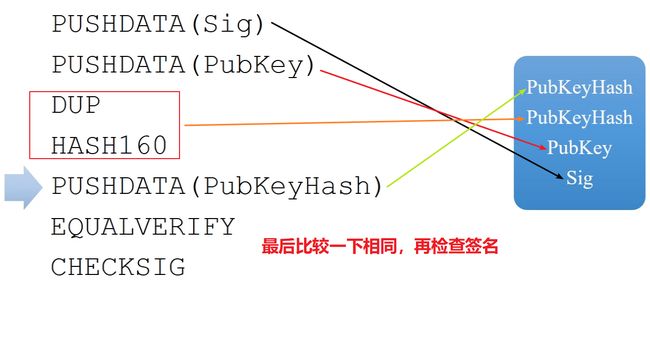
实例:
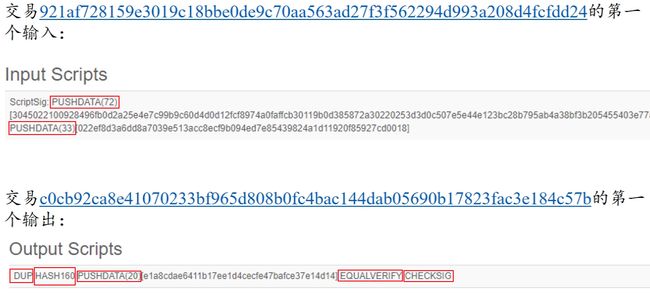
2.8.2.3 P2SH(Pay to Script Hash)
P2SH主要解决了,当验证交易需要多重签名的时候,付款人在写入output script时由于收款人提供的公钥过多,导致付款人写的很累的问题。
以前没有用到P2SH的多重签名例子:

说明:我们发现在input script的第一行有一个false,是历史遗留问题,因为在运行最下面的CHECKMULTISIG的时候,会多出一个对象,所以才多加一个false去抵消。
脚本执行:

我们确实能发现,上一个交易的output script里面东西很多,上一笔交易的付款人要将收款人如此多的公钥装进output script里,不同的收款人他们要求的公钥数量也不一样,这就导致每次付款人付款的时候,要根据不同的收款人提供的公钥去写output script,非常麻烦。为了减少付款人的压力,P2SH将这些收款人提供的公钥封装在另外一个脚本(redeemScript)里,并且付款人只要将这个脚本的Hash值放入output script里面就可以了。
P2SH多重签名的例子:

所以在验证的时候,P2SH需要验证两步:
- 验证赎回脚本的Hash值是否匹配;
- 验证赎回脚本的内容是否和input script里面的签名匹配。
步骤一脚本执行:

上面的脚本执行完,在堆栈中还剩下:

所以我们还需要执行步骤二的脚本:

P2SH的实例:

2.8.2.3 Proof of Burn
这是一种特殊的脚本形式,有人在交易的output script里面开头写上一句return,这会导致下一笔交易在验证的时候,拼接input script和out script执行后,碰到output script里面的return就直接返回了,使得验证不通过,这会导致output script里面有return的那些交易中输出的比特币永远无法被花出去,其对应的UTXO里面的数据也可以被删除了。
使用场景:
- 一些小的加密币种会要求用户销毁一部分比特币来换取小的加密币,通过使用在output script 里面加return的方法就可以销毁比特币;
- 一些人使用区块链去记录一些东西,比如知识产权啊之类的,也可以使用这个方法完成。
那么为啥不用coinbase去做一样的处理呢?是因为coinbase域所在的交易只有获得记账权的全节点才有资格去写,而使用Proof of Burn就可以让随便一个用户完成操作。
2.9 分叉
分叉就是指区块链变成了多条链,分叉有下面几种类型:
-
state fork,自然挖矿产生的分叉;
-
deliberate fork,人为恶意分叉;
-
protocol fork,比特币协议发生修改时,由于有一些旧节点更新慢或者不愿意接受更新而造成的分叉,根据协议的不同分为硬分叉(hard fork)和软分叉(soft fork);
- 硬分叉,对比特币协议的内容产生分歧后导致永久分叉。比如更新比特币中的区块大小限制,每一个区块容量从1M扩容到4M,大部分节点都更新了,小部分没有更新,对于这小部分不更新的旧节点,会认为那些容量大于1M的新区块是非法的,这就会导致分叉,而旧节点永远不更新,这种分叉就一直会存在。
- 软分叉,往比特币协议里面加一些限制导致临时分叉。比如给目前协议中一些没有规定的域增加新的含义,每一个区块的coinbase transaction(铸币交易)中有coinbase域,有人提出将UTXO集合的hash值放在coinbase域的区块才合法,那么占绝大多数的更新了软件的新节点们就只认封装了UTXO集合hash值的区块,而没有更新的小部分旧节点们认为封装UTXO的区块和没有封装的都是合法的,就造成了临时性的软分叉。
硬分叉软分叉都是由于比特币协议发生了变化导致的。比特币协议改变后,旧节点不认可协议更新后产生的区块,会因为旧节点不更新就永远存在分叉,那么就是硬分叉;如果旧节点认可协议更新后的新区快,新节点只认符合新协议的区块(因为旧节点挖出来的区块不符合新协议),因为大部分算力掌握在新节点手中,旧节点挖出来的区块不会被认可所以会经常被回滚,导致分叉临时存在,那就是软分叉。
3. 以太坊
以太坊的内容暂时没看,等需要用到的时候再了解~
参考资料:
北京大学肖臻老师《区块链技术与应用》公开课