实验室gpu服务器集群 使用方法探索
文章主要介绍实验室GPU集群服务器的使用方法,具体可以参考官方手册SitonHoly Cluster Manager Platform(SCM)用户手册。如有雷同,请联系作者删除。
此教程仅适用于scm2.0以下版本,有可能系统已经进行了升级(2020年7月以后),针对新版本,请读者自行探索。
目录
目录
普通用户:
一 向管理员申请账号
二 服务器连接互联网
三 文件管理
四 镜像管理
上传镜像:
镜像封装:
五 作业提交
1 提交tensorflow作业 test
2 pycharm 连接服务
3 使用 Jupyter连接服务
管理员:
一 创建用户
创建系统远程用户:
普通用户:
一 向管理员申请账号
包括网页端的账号、harbor账号、系统层面用于制作镜像的ssh远程账号。
二 服务器连接互联网
最近找到一个docker的无头浏览器镜像,操作很简单,在自己电脑的浏览器上打开 服务器ip:端口号(比如 219.216.99.4:6901),即可进入一个界面(密码 vncpassword),打开这个界面内置的浏览器Chrome,按正常上网的方式登录校园网的网关就行了。如果不会请咨询管理员。
一个人登录后服务器所有用户都可上网,请注意流量消耗。
三 文件管理
参考思腾合力 文件管理 文档。
登录服务器
1 档案上传
文件管理里面,新建一个文件夹,点击右上角的 “档案上传”,选择需要上传的文件然后点击上传即可。
注意:这里只可以上传单个文件,不可以上传文件夹,可以上传压缩包后通过网页端进行解压。
2 文件下载
可以直接使用下载按钮下载单个文件
如果需要下载文件夹,启动一个作业(分配尽可能少的计算资源,1核CPU,0张显卡,2G内存),使作业处于空跑状态(执行命令 sleep infinity), 进入作业的详细界面,“网页ssh”,修改镜像密码 (passwd), -> 使用自己电脑远程登录镜像(ssh -p ssh端口号 root@服务器ip),文件在 /root/data/...,-> 使用scp命令即可远程下载。
四 镜像管理
参考思腾合力 镜像管理文档。
上传镜像:
- 命令行远程登录系统,通过groups指令查看是否加入docker组

- 网页端镜像管理里面新建自己的项目
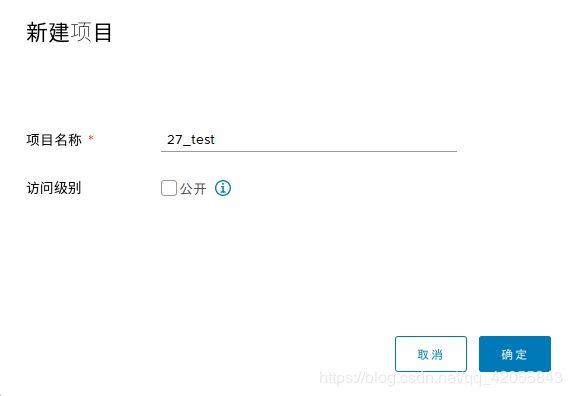
- 命令行登录自己的harbor 镜像仓库,输入对应的harbor用户名和密码。(192.168.137.10:8888是harbor仓库的地址,自己对应着修改。通常为服务器ip8888号端口(ip:8888))
docker login 192.168.137.10:8888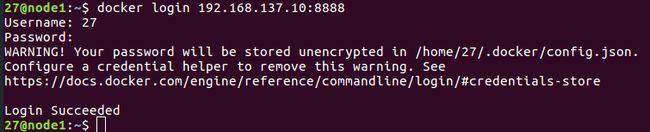
- 可以使用 docker search 搜索需要的镜像
docker search tensorflow-gpu #比如搜索gpu版的tensorflow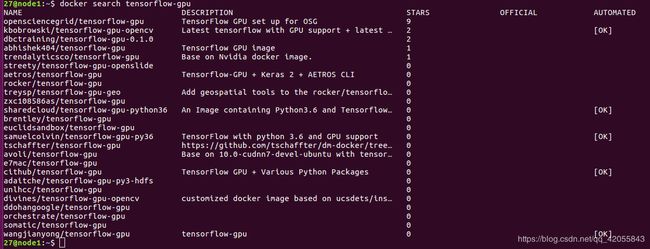
- 使用 docker pull 拉取镜像,如果本地没有,会从docker hub仓库中寻找(如果服务器没有连互联网,就需要通过其他方式拉取)
docker pull walker519/cuda_python_tensorflow-gpu:9.0_3.5_1.12.0 - 使用 docker images 查看本地已经拉取过的镜像
docker images
- 将镜像推送到自己的harbor镜像仓库
在自己的项目里面有一个推送镜像: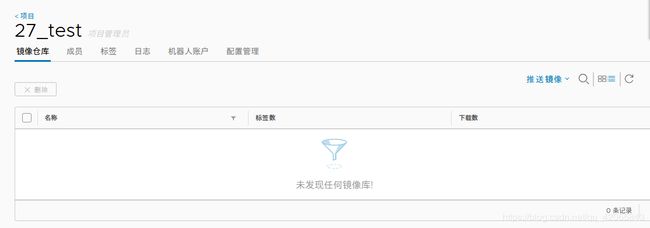
先给镜像打标签后推送到当前项目
docker tag walker519/cuda_python_tensorflow-gpu:9.0_3.5_1.12.0 192.168.137.10:8888/27_test/cuda_python_tensorflow-gpu:9.0_3.5_1.12.0 docker push 192.168.137.10:8888/27_test/cuda_python_tensorflow-gpu:9.0_3.5_1.12.0 -
刷新自己网页端的harbor镜像管理,就可以找到自己推送的镜像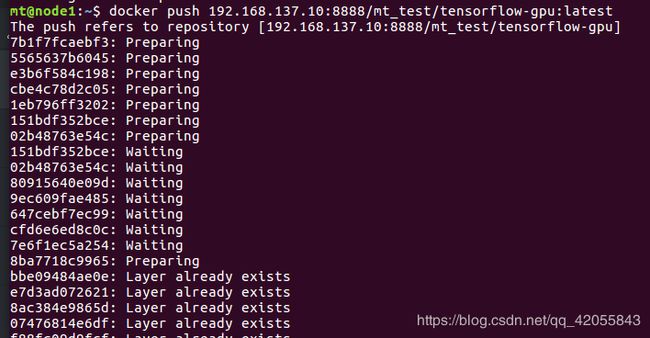
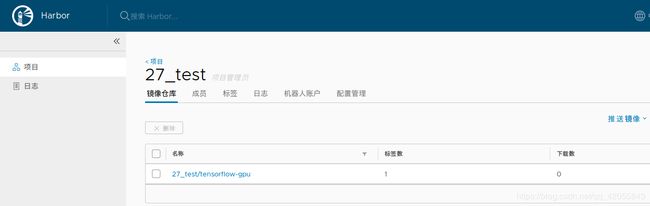
- 提交作业时需要用到的镜像地址
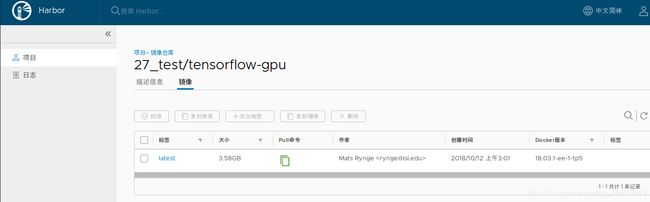
点击pull命令下的两个方框 ,即可复制得到:
其中删除掉 “docker pull 192.168.137.10:8888/27_test/cuda_python_tensorflow-gpu:9.0_3.5_1.12.0docker pull”,后面的内容 “ 192.168.137.10:8888/27_test/cuda_python_tensorflow-gpu:9.0_3.5_1.12.0 ”就是提交作业时需要的镜像地址。
镜像封装:
目前本人也是正在进行探索,后期会进行补充。
可以参考:
- 基于cuda9.0 制作tensorflow镜像
五 作业提交
使用JSON格式提交作业
- 方式一:导入JSON文件
- 方式二:复制JSON文件
- 方式三:填写表单
1 提交tensorflow作业 test
- 准备数据和代码
将代码和数据通过网页端进行上传(注意是在 test_ 文件夹存放的 test.py 文件)
# test.py文件内容如下(最近在学tensorflow,手打的书上的例子程序) import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data INPUT_NODE = 784 OUTPUT_NODE = 10 LAYER1_NODE = 500 BATCH_SIZE = 100 LEARNING_RATE_BASE = 0.8 LEARNING_RATE_DECAY = 0.99 REGULARIZATION_RATE = 0.0001 TRAINNING_SETPS = 30000 MOVING_AVERAGE_DECAY = 0.99 def inference(input_tensor, avg_class, weights1, biases1, weights2, biases2): if avg_class ==None: layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1) return tf.matmul(layer1, weights2) + biases2 else: layer1 = tf.nn.relu(tf.matmul(input_tensor, avg_class.average(weights1)) + avg_class.average(biases1)) return tf.matmul(layer1, avg_class.average(weights2)) + avg_class.average(biases2) def train(mnist): x = tf.placeholder(tf.float32, [None, INPUT_NODE], name='x-input') y_ = tf.placeholder(tf.float32, [None, OUTPUT_NODE], name='y-input') weights1 = tf.Variable(tf.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1)) biases1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE])) weights2 = tf.Variable(tf.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1)) biases2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE])) y = inference(x, None, weights1, biases1, weights2, biases2) global_step = tf.Variable(0, trainable=False) variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step) variables_averages_op = variable_averages.apply(tf.trainable_variables()) average_y = inference(x, variable_averages, weights1, biases1, weights2, biases2) cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1)) cross_entropy_mean = tf.reduce_mean(cross_entropy) regualrizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE) regularization = regualrizer(weights1) + regualrizer(weights2) loss = cross_entropy_mean + regularization learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, global_step, mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY) train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step) with tf.control_dependencies([train_step, variables_averages_op]): train_op = tf.no_op(name='train') correct_prediction = tf.equal(tf.argmax(average_y, 1), tf.argmax(y_, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) with tf.Session() as sess: tf.global_variables_initializer().run() validate_feed = {x: mnist.validation.images, y_: mnist.validation.labels} test_feed = {x: mnist.test.images, y_: mnist.test.labels} for i in range(TRAINNING_SETPS): if i%1000 == 0: validate_acc = sess.run(accuracy, feed_dict=validate_feed) print("After %d training step(s), validation accuracy " "using average model is %g " % (i, validate_acc)) validate_acc = sess.run(accuracy, feed_dict=validate_feed) test_acc = sess.run(accuracy, feed_dict=test_feed) print( "After %d training step(s), validation accuracy using average model is %g, test accuracy using average model is %g" % ( i, validate_acc, test_acc)) xs, ys = mnist.train.next_batch(BATCH_SIZE) sess.run(train_op, feed_dict={x: xs, y_: ys}) test_acc = sess.run(accuracy, feed_dict=test_feed) print("After %d training step(s) ,test accuracy using average " "model is %g " % (TRAINNING_SETPS, test_acc)) def main(argv=None): mnist = input_data.read_data_sets("./mnist/", one_hot=True) train(mnist) if __name__== '__main__': tf.app.run() - 网页端配置JSON文件
作业名称自己随意写,不能和之前的重复,镜像地址在前面第四章中提到过 ( 192.168.137.10:8888/27_test/tensorflow-gpu:latest )
显卡类别选择 generic ,任务角色清单自己对应修改就可以了(共享内存一般为2~4G就行了)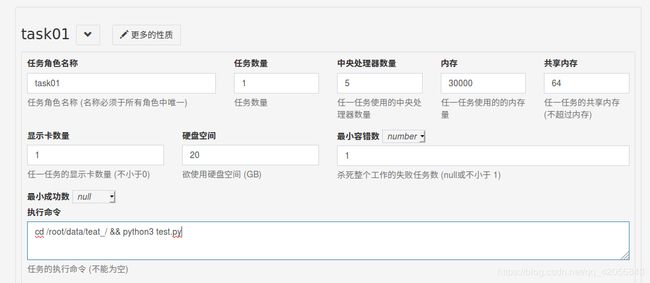
- 提交作业
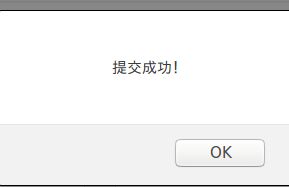
- 在作业管理界面可以看到自己提交的作业


- 可以在标准输出中查看输出结果
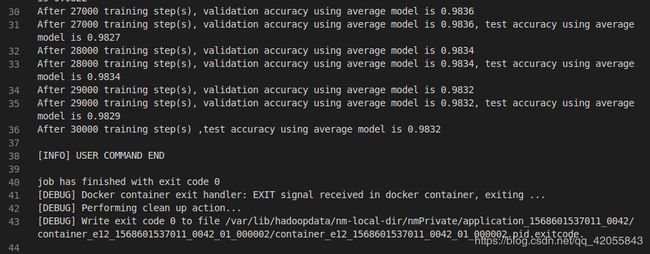
- 任务结束
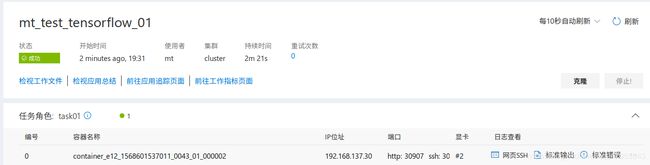
2 pycharm 连接服务
参考思腾合力给的手册 Pycharm连接服务
安装pycharm专业版,提供一个我曾经购买过的 Activation code:
QYYBAC9D3J-eyJsaWNlbnNlSWQiOiJRWVlCQUM5RDNKIiwibGljZW5zZWVOYW1lIjoi6LaF57qnIOeoi+W6j+WRmCIsImFzc2lnbmVlTmFtZSI6IiIsImFzc2lnbmVlRW1haWwiOiIiLCJsaWNlbnNlUmVzdHJpY3Rpb24iOiIiLCJjaGVja0NvbmN1cnJlbnRVc2UiOmZhbHNlLCJwcm9kdWN0cyI6W3siY29kZSI6IklJIiwiZmFsbGJhY2tEYXRlIjoiMjAyMC0wMS0wNCIsInBhaWRVcFRvIjoiMjAyMS0wMS0wMyJ9LHsiY29kZSI6IkFDIiwiZmFsbGJhY2tEYXRlIjoiMjAyMC0wMS0wNCIsInBhaWRVcFRvIjoiMjAyMS0wMS0wMyJ9LHsiY29kZSI6IkRQTiIsImZhbGxiYWNrRGF0ZSI6IjIwMjAtMDEtMDQiLCJwYWlkVXBUbyI6IjIwMjEtMDEtMDMifSx7ImNvZGUiOiJQUyIsImZhbGxiYWNrRGF0ZSI6IjIwMjAtMDEtMDQiLCJwYWlkVXBUbyI6IjIwMjEtMDEtMDMifSx7ImNvZGUiOiJHTyIsImZhbGxiYWNrRGF0ZSI6IjIwMjAtMDEtMDQiLCJwYWlkVXBUbyI6IjIwMjEtMDEtMDMifSx7ImNvZGUiOiJETSIsImZhbGxiYWNrRGF0ZSI6IjIwMjAtMDEtMDQiLCJwYWlkVXBUbyI6IjIwMjEtMDEtMDMifSx7ImNvZGUiOiJDTCIsImZhbGxiYWNrRGF0ZSI6IjIwMjAtMDEtMDQiLCJwYWlkVXBUbyI6IjIwMjEtMDEtMDMifSx7ImNvZGUiOiJSUzAiLCJmYWxsYmFja0RhdGUiOiIyMDIwLTAxLTA0IiwicGFpZFVwVG8iOiIyMDIxLTAxLTAzIn0seyJjb2RlIjoiUkMiLCJmYWxsYmFja0RhdGUiOiIyMDIwLTAxLTA0IiwicGFpZFVwVG8iOiIyMDIxLTAxLTAzIn0seyJjb2RlIjoiUkQiLCJmYWxsYmFja0RhdGUiOiIyMDIwLTAxLTA0IiwicGFpZFVwVG8iOiIyMDIxLTAxLTAzIn0seyJjb2RlIjoiUEMiLCJmYWxsYmFja0RhdGUiOiIyMDIwLTAxLTA0IiwicGFpZFVwVG8iOiIyMDIxLTAxLTAzIn0seyJjb2RlIjoiUk0iLCJmYWxsYmFja0RhdGUiOiIyMDIwLTAxLTA0IiwicGFpZFVwVG8iOiIyMDIxLTAxLTAzIn0seyJjb2RlIjoiV1MiLCJmYWxsYmFja0RhdGUiOiIyMDIwLTAxLTA0IiwicGFpZFVwVG8iOiIyMDIxLTAxLTAzIn0seyJjb2RlIjoiREIiLCJmYWxsYmFja0RhdGUiOiIyMDIwLTAxLTA0IiwicGFpZFVwVG8iOiIyMDIxLTAxLTAzIn0seyJjb2RlIjoiREMiLCJmYWxsYmFja0RhdGUiOiIyMDIwLTAxLTA0IiwicGFpZFVwVG8iOiIyMDIxLTAxLTAzIn0seyJjb2RlIjoiUlNVIiwiZmFsbGJhY2tEYXRlIjoiMjAyMC0wMS0wNCIsInBhaWRVcFRvIjoiMjAyMS0wMS0wMyJ9XSwiaGFzaCI6IjE2MDgwOTA5LzAiLCJncmFjZVBlcmlvZERheXMiOjcsImF1dG9Qcm9sb25nYXRlZCI6ZmFsc2UsImlzQXV0b1Byb2xvbmdhdGVkIjpmYWxzZX0=-I7c5mu4hUCMxcldrwZEJMaT+qkrzrF1bjJi0i5QHcrRxk2LO0jqzUe2fBOUR4L+x+7n6kCwAoBBODm9wXst8dWLXdq179EtjU3rfJENr1wXGgtef//FNow+Id5iRufJ4W+p+3s5959GSFibl35YtbELELuCUH2IbCRly0PUBjitgA0r2y+9jV5YD/dmrd/p4C87MccC74NxtQfRdeUEGx87vnhsqTFH/sP4C2VljSo/F/Ft9JqsSlGfwSKjzU8BreYt1QleosdMnMK7a+fkfxh7n5zg4DskdVlNbfe6jvYgMVE16DMXd6F1Zhwq+lrmewJA2jPToc+H5304rcJfa9w==-MIIElTCCAn2gAwIBAgIBCTANBgkqhkiG9w0BAQsFADAYMRYwFAYDVQQDDA1KZXRQcm9maWxlIENBMB4XDTE4MTEwMTEyMjk0NloXDTIwMTEwMjEyMjk0NlowaDELMAkGA1UEBhMCQ1oxDjAMBgNVBAgMBU51c2xlMQ8wDQYDVQQHDAZQcmFndWUxGTAXBgNVBAoMEEpldEJyYWlucyBzLnIuby4xHTAbBgNVBAMMFHByb2QzeS1mcm9tLTIwMTgxMTAxMIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAxcQkq+zdxlR2mmRYBPzGbUNdMN6OaXiXzxIWtMEkrJMO/5oUfQJbLLuMSMK0QHFmaI37WShyxZcfRCidwXjot4zmNBKnlyHodDij/78TmVqFl8nOeD5+07B8VEaIu7c3E1N+e1doC6wht4I4+IEmtsPAdoaj5WCQVQbrI8KeT8M9VcBIWX7fD0fhexfg3ZRt0xqwMcXGNp3DdJHiO0rCdU+Itv7EmtnSVq9jBG1usMSFvMowR25mju2JcPFp1+I4ZI+FqgR8gyG8oiNDyNEoAbsR3lOpI7grUYSvkB/xVy/VoklPCK2h0f0GJxFjnye8NT1PAywoyl7RmiAVRE/EKwIDAQABo4GZMIGWMAkGA1UdEwQCMAAwHQYDVR0OBBYEFGEpG9oZGcfLMGNBkY7SgHiMGgTcMEgGA1UdIwRBMD+AFKOetkhnQhI2Qb1t4Lm0oFKLl/GzoRykGjAYMRYwFAYDVQQDDA1KZXRQcm9maWxlIENBggkA0myxg7KDeeEwEwYDVR0lBAwwCgYIKwYBBQUHAwEwCwYDVR0PBAQDAgWgMA0GCSqGSIb3DQEBCwUAA4ICAQAF8uc+YJOHHwOFcPzmbjcxNDuGoOUIP+2h1R75Lecswb7ru2LWWSUMtXVKQzChLNPn/72W0k+oI056tgiwuG7M49LXp4zQVlQnFmWU1wwGvVhq5R63Rpjx1zjGUhcXgayu7+9zMUW596Lbomsg8qVve6euqsrFicYkIIuUu4zYPndJwfe0YkS5nY72SHnNdbPhEnN8wcB2Kz+OIG0lih3yz5EqFhld03bGp222ZQCIghCTVL6QBNadGsiN/lWLl4JdR3lJkZzlpFdiHijoVRdWeSWqM4y0t23c92HXKrgppoSV18XMxrWVdoSM3nuMHwxGhFyde05OdDtLpCv+jlWf5REAHHA201pAU6bJSZINyHDUTB+Beo28rRXSwSh3OUIvYwKNVeoBY+KwOJ7WnuTCUq1meE6GkKc4D/cXmgpOyW/1SmBz3XjVIi/zprZ0zf3qH5mkphtg6ksjKgKjmx1cXfZAAX6wcDBNaCL+Ortep1Dh8xDUbqbBVNBL4jbiL3i3xsfNiyJgaZ5sX7i8tmStEpLbPwvHcByuf59qJhV/bZOl8KqJBETCDJcY6O2aqhTUy+9x93ThKs1GKrRPePrWPluud7ttlgtRveit/pcBrnQcXOl1rHq7ByB8CFAxNotRUYL9IF5n3wJOgkPojMy6jetQA5Ogc8Sm7RG6vg1yow==或者也可以参考教程: 链接:https://pan.baidu.com/s/1ePUA0OiFFmij7sxpcrKQKQ 提取码:dsy0
谷歌云盘 https://drive.google.com/file/d/1YyepbD7pYjgVA0fHReHQ6DIvFsRPfFVb/view?usp=sharing
提供一个JSON文件进行参考:
{
"jobName": "mt_test_tensorflow_02",
"image": "docker push 192.168.137.10:8888/27_test/cuda_python_tensorflow-gpu:9.0_3.5_1.12.0",
"authFile": "",
"dataDir": "",
"outputDir": "",
"codeDir": "",
"retryCount": 0,
"taskRoles": [
{
"name": "task",
"taskNumber": 1,
"cpuNumber": 10,
"memoryMB": 20480,
"shmMB": 1024,
"gpuNumber": 1,
"storageGB": 80,
"minFailedTaskCount": 1,
"minSucceededTaskCount": null,
"command": "sleep infinity",
"portList": []
}
],
"jobEnvs": {},
"extras": {
"virtualGroup": "cluster"
},
"gpuType": "generic"
}注意:
- pycharm界面里需要将输入的内网ip替换成公网ip。
- 在官方手册3.(2)下载秘钥时需要ssh远程登录,先下载到远程目录下,再通过scp传回本地电脑。
- 使用SFTP连接时,user name为root,这里只是一root账号连接,并不需要填写密码
3 使用 Jupyter连接服务
参考思腾合理文档,第3节(使用Jupyter连接服务)。
注意需要将内网ip替换成公网ip 。
1. 选择镜像、设置计算资源和之前都差不多,在执行命令这一栏填写下面内容来启动jupyter服务:

jupyter notebook --allow-root --no-browser --ip 0.0.0.0 --port=$PAI_CONTAINER_HOST_jupyter_PORT_LIST --NotebookApp.token=\"\" --NotebookApp.allow_origin=\"*\" --NotebookApp.base_url=\"/\"上面的命令表示启动jupyter服务:
- --allow-root:以root用户启动
- --no-browser:启动后不要在浏览器中打开笔记本
- --ip 0.0.0.0:使用本服务器的所有ipv4地址
- --port=$PAI_CONTAINER_HOST_jupyter_PORT_LIST:开放jupyter端口
- --NotebookApp.token=\"\":不为notebook设置初始口令牌
- --NotebookApp.allow_origin=\"*\":允许所有地址来访问jupyter。(Use '*' to allow any origin to access your server.
) - --NotebookApp.base_url=\"/\":不设置URL
2.然后在下方添加一个容器映射端口:

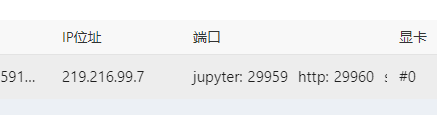
3.启动任务后会有一个ip和jupyter端口号,在浏览器输入即可进行访问。
管理员:
可以把计算资源细分为多个集群。如果有比较紧急的计算任务(比如项目检查、发表论文等),可以将这些用户划分到一个单独的集群里面去,提供更多的计算资源。
一 创建用户
创建系统远程用户:
sudo useradd -rms /bin/bash test01 #用户名为test01, 不能以数字开头sudo passwd test01 #修改用户test01的密码添加docker权限:
sudo usermod -aG docker test01可以使用 groups 命令查看是否加入docker