Python 异步 协程 线程(池) 进程(池)
文章目录
- 概要
- 一般方法
- 协程
- 异步协程
- 多协程
- 线程
- 多线程
- 线程的数量设置
- 线程池
- 进程
- 多进程
- 进程池
- 结语
概要
当我们在对某些网页进行抓取时,通常会抱怨程序运行时间太长,有时候一个10页的网页都有可能需要运行个一分多钟。其实在这一分多钟里,我们的程序大部分时间是在等待网页响应,也就是说当我们在抓取第一页时,程序需要等待这个第一页加载完毕然后再去提取数据,接着才能进行下一页的抓取,这就导致了过程阻塞。
事实上,在等待响应的时候,我们可以去干其他的事情,比如再发送别的请求,或进行网页解析。这个时候,我们就可以通过异步来解决该问题,即在请求发出之后,程序可以继续执行其他操作,当之前的响应到达时,程序再去处理这个响应。
当你要处理数据量较为庞大,又或者请求较多时,我们可以使用协程、线程(池)、 进程(池)来进行处理。对于协程、线程、进程的概念再此不过多阐述,已经有好多大佬对这些东西进行了解释。在这里我们仅通过几张图来进行说明。

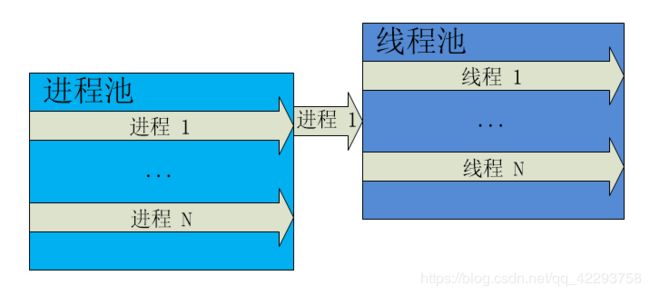
从第一张图中我们可以明显的看出协程、线程、进程的从属关系;从第二张图我们可以看出一个进程中可包含多个线程,需要指出的是一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
对于协程的使用,我想大多数应该已经用过了,最简单的就是yield,它可以使当前运行的某个函数将CPU让出,也就是中断的一种。
接下来,我将通过代码来对异步、协程、线程(池)、进程(池)进行说明。
一般方法
首先,我们写出一个通常情况下的函数,由于后文需要使用多线程,多进程,所以我们有必要把该程序所使用的线程ID和进程ID给表示出来,至于协程,我们在这里并未创建
import time
import os
import threading
def sleep(x):
print('函数的线程ID:', threading.get_ident())
time.sleep(x)
return 'Hello'
if __name__ == '__main__':
t1 = time.time()
print('主进程PID:',os.getpid())
print('主程序线程ID:', threading.get_ident())
for x in range(0, 5):
sleep(x)
t2 = time.time()
print('使用一般方法,总共耗时 %s' % (t2 - t1))
这就是一个自定义延时函数,因为当我们使用异步、协程、线程(池)、进程(池)的最终目的还是为了追求速度,这里的延时可以看作是在等待网页响应。
上述代码的运行结果是
主进程PID: 12052
主程序线程ID: 4236
函数的线程ID: 4236
函数的线程ID: 4236
函数的线程ID: 4236
函数的线程ID: 4236
函数的线程ID: 4236
使用一般方法,总共耗时 10.001280546188354
我们可以看出,这里至始至终只使用了一个进程和一个线程。我们分析一下这个时间可以知道是由‘0+1+2+3+4’所得到的。我们可以想一下,如果让电脑的性能发挥到极致,对该段代码进行修改,我们最少要多少时间呢?
答案是,只要4s多一丢丢!
协程
异步协程
在这里我们考虑使用异步协程的方法,对于异步的具体细节就不在此展开了(主要是我还没学到精髓~~~)
异步协程的代码如下:
import asyncio
import time
import threading
import os
import gevent
async def sleep(x):
print('函数的线程ID:', threading.get_ident())
print('协程目标:', gevent.getcurrent(), x)
await asyncio.sleep(x) # 注意这里不是time.sleep(),若使用time.sleep()将会导致线程阻塞
return 'Hello'
if __name__ == '__main__':
t1 = time.time()
print('主进程PID:',os.getpid())
print('主程序线程ID:', threading.get_ident())
loop = asyncio.get_event_loop() # 得到一个标准的事件循环
tasks = [asyncio.ensure_future(sleep(x)) for x in range(0, 5)] # 获取任务列表
tasks = asyncio.gather(*tasks)
loop.run_until_complete(tasks)
t2 = time.time()
print('使用异步方法,总共耗时 %s' % (t2 - t1))
在输出结果之前,我们可以观察一下我们所建立的sleep()函数类型,我们可以通过以下代码来观察:
typ = sleep(1)
print(typ)
从结果我们可以发现,我们在这里创建了协程,并通过协程来实现了异步操作,当遇到延时阻塞时,便去执行其他操作。
上述完整代码的输出结果是:
主进程PID: 13064
主程序线程ID: 6492
函数的线程ID: 6492
协程目标: 0
函数的线程ID: 6492
协程目标: 1
函数的线程ID: 6492
协程目标: 2
函数的线程ID: 6492
协程目标: 3
函数的线程ID: 6492
协程目标: 4
使用异步方法,总共耗时 4.002932786941528
天哪,我们已经实现了我们的最终目标,得到运行的最快的速度。并且也只用到了一个进程和一个线程,于之前一个程序的不同之处在于,我们使用了协程,并采样了异步操作。在这里我们只创建了一个协程(协程也是单线程),并将所有阻塞的操作都转化为异步操作。
在这里需要注意的是我们的耗时操作使用的不是time.sleep(),而是asyncio.sleep(),因为time.sleep()将会导致线程阻塞,而我们的所有异步操作均是在同一个线程中进行了,若使用time.sleep(),会使得程序表面上去是异步的,但实为不然,对此,我们可以通过一组时序图来进行说明。
使用asyncio.sleep():

使用time.sleep():
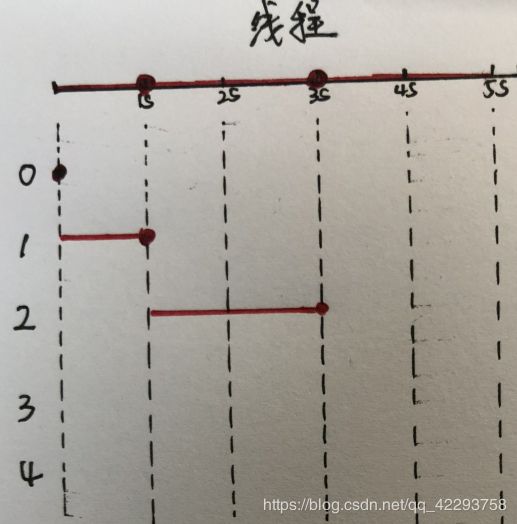
图中,红线加粗的部分表示延时,点表示延时完毕执行输出返回。从使用asyncio.sleep()的图中,我们可以发现,当程序刚遇到延时时,就去执行另外的操作(也就是在1的时候需要延时,马上去执行2的延时,依此类推)。而在使用time.sleep()的图中,则需要去进行等待,等第一个延时结束后,才去执行另外的操作(也就是在1的时候等1s之后再去执行2,依此类推)。所以说,如果在这里我们使用time.sleep()的话就和一般的方法就没有区别了,它的运行时间也需要8s多。
多协程
在上面的代码中,我们实际上只创建了一个协程,实际上,我们可以创建多个协程,并且也可以对同时运行的协程的数量进行限制。接下来,我们便创建多个协程,并对同时运行的协程数量进行限制,在这里我们使用了gevent模块来执行协程操作,代码如下:
import gevent
import os
import threading
from gevent import monkey
from gevent import pool
monkey.patch_socket()
POOL_MAXSIZE = 2
pool = pool.Pool(POOL_MAXSIZE) # 设置最大协程数
def sleep(x):
print('函数的线程ID:', threading.get_ident())
print('协程目标:', gevent.getcurrent(), x)
gevent.sleep(x) # 协程休眠
return 'Hello'
if __name__ == '__main__':
t1 = time.time()
print('主进程PID:',os.getpid())
print('主程序线程ID:', threading.get_ident())
# 方法1
# groups = ([x for x in range(0, 5)])
# pool.map(sleep, groups)
# 方法2
# for i in range(0, 5):
# pool.spawn(sleep, i, )
# pool.join()
# 方法3
_list = []
for i in range(0, 5):
_list.append(pool.spawn(sleep, i, ))
gevent.joinall(_list)
t2 = time.time()
print('使用协程池方法,总共耗时 %s' % (t2 - t1))
运行结果为:
主进程PID: 3400
主程序线程ID: 4412
函数的线程ID: 4412
协程目标: 0
函数的线程ID: 4412
协程目标: 1
函数的线程ID: 4412
协程目标: 2
函数的线程ID: 4412
协程目标: 3
函数的线程ID: 4412
协程目标: 4
使用协程池方法,总共耗时 6.006633043289185
我们可以看出在一个线程中一共创建了5个协程,但是在运行的时候只有两个在同时运行(跑代码的时候可以看的出来的)。这里用时达到了6s多(2+4得到的),这是因为我们在每个协程中,都对协程进行了阻塞操作。如果想要同样达到4s的速度,我们只需要将POOL_MAXSIZE设置为5即可。
我们将在后面线程池和进程池中也将其数量设置为2,用来和该段程序进行比较。
线程
多线程
一般情况下我们编写的程序只使用到了一个线程,而我们都知道电脑是有许多线程处理的,因此当我们使用多线程时,无疑会加快程序的运行,代码如下:
import time
from threading import Thread
import threading
def sleep(x):
print('新创建的线程ID:', threading.get_ident())
time.sleep(x)
return 'Hello'
if __name__ == '__main__':
t1 = time.time()
print('主程序线程ID:', threading.get_ident())
threads = [] # 用于存放线程
for x in range(0, 5):
th = Thread(target = sleep, args = (x,)) # 创建线程
threads.append(th)
th.start() # 启动线程
# 等待所有线程结束,再运行主程序的线程
for th in threads:
th.join()
t2 = time.time()
print('使用多线程,总共耗时 %s' % (t2 - t1))
运行结果为:
主程序线程ID: 5504
新创建的线程ID: 12600
新创建的线程ID: 3908
新创建的线程ID: 14832
新创建的线程ID: 7080
新创建的线程ID: 13972
使用多线程,总共耗时 4.002230644226074
这里我们创建了5个线程,每个线程对应一个sleep(),因而总耗时也仅需4s多。
线程的数量设置
对于多线程,我们可以选择不是有多少个任务就创建多少个线程的,我们可以对线程的数量进行限制,方法有多中,在这里仅讨论两种。
方法1:
统计当前运行的线程数量len(threading.enumerate())
import time
from threading import Thread
import threading
def sleep(x):
print('新创建的线程ID:', threading.get_ident())
time.sleep(x)
return 'Hello'
if __name__ == '__main__':
t1 = time.time()
print('主程序线程ID:', threading.get_ident())
threads = []
for x in range(0, 5):
th = Thread(target = sleep, args = (x,)) # 创建线程
threads.append(th)
# th.start() # 启动线程
# 设置运行的线程数,在这里我们设置了最大线程数量为3,主程序还有一个线程,也就是说只能再创建2个线程
for th in threads:
th.start()
while True:
#判断正在运行的线程数量,如果小于所设置的线程数量就退出while循环,进入for循环启动新的进程
if(len(threading.enumerate()) < 3):
break
# 等待所有线程结束
for th in threads:
th.join()
t2 = time.time()
print('设置最大线程数,总共耗时 %s' % (t2 - t1))
使用上述方法来设置最大线程数时,需考虑到主程序的线程数量,要不然预期的想创建的线程数量将会变少,因此我们在这里设置了最大线程数为3,即能够再创建两个线程。
方法2:
使用Semaphore
import time
from threading import Thread
import threading
sem = threading.Semaphore(2) # 最多启用多少个线程
def sleep(x):
sem.acquire() #准备创建启用一个线程,可用线程数量就会减1
print('新创建的线程ID:', threading.get_ident())
time.sleep(x)
# return 'Hello'
sem.release() # 释放线程,可用线程数加1
if __name__ == '__main__':
t1 = time.time()
print('主程序线程ID:', threading.get_ident())
threads = []
for x in range(0, 5):
sem.acquire() #准备创建启用一个线程,可用线程数量就会减1
th = Thread(target = sleep, args = (x,)) # 创建线程
threads.append(th)
th.start() # 启动线程
# 等待所有线程结束
for th in threads:
th.join()
t2 = time.time()
print('设置最大线程数,总共耗时 %s' % (t2 - t1))
该方法可以避免考虑主程序的线程数量,只关注于我们想最多创建多少个线程。在这里我们使用了Semaphore,它是同时允许一定数量的线程对数据进行更改。在这里,我们稍带提一下 acquire()和release(),这两个方法通常用来对线程进行锁操作,这样一来就可以对数据进行保护,以免出现脏数据(多个线程同时修改同一条数据),其主要代码如下:
lock = threading.Lock() #实例化一个锁对象
def run(n):
lock.acquire() #获取锁
global num
num += 1
lock.release() #释放锁
线程池
其实线程池和刚刚的限制线程的数量差不多,只是我们一开始就将所有的线程给创建出来,再一个个的取出运行,代码如下:
import threading
import threadpool
import time
import os
def sleep(x):
print('新创建的线程ID:', threading.get_ident())
time.sleep(x)
return 'Hello'
if __name__ == '__main__':
t1 = time.time()
print('主进程PID:',os.getpid())
print('主程序线程ID:', threading.get_ident())
pool = threadpool.ThreadPool(2) # 创建线程池
list_ = [x for x in range(0, 5)]
requests = threadpool.makeRequests(sleep, list_) # 创建任务,返回的list对象
[pool.putRequest(req) for req in requests] # 线程池依此执行
pool.wait() # 等待所有线程完成
t2 = time.time()
print('使用线程池,总共耗时 %s' % (t2 - t1))
主进程PID: 8720
主程序线程ID: 14312
新创建的线程ID: 15340
新创建的线程ID: 15340
新创建的线程ID: 1744
新创建的线程ID: 15340
新创建的线程ID: 1744
使用线程池,总共耗时 6.00337815284729
我们在这里设置线程池中的线程数量为2,换句话说,线程池一次只能执行两个线程。心细的同学可能会发现,在刚开始创建新线程时,创建了两个ID一样的线程,这主要是一开始0s的阻塞所造成的。在这里,我们还需要去看一下所创建的任务列表:
[, , , , ]
在任务列表中,发现所有的请求任务都被仍进了线程池中,当有线程池余线程时,取出一个请求来执行。
进程
多进程
对于多进程的创建与多线程的创建有异曲同工之妙,其主要通过multiprocessing库中的Process类来实现,代码如下
import time
from multiprocessing import Process
import os
def sleep(x):
print('子进程ID:',os.getpid())
time.sleep(x)
return 'Hello'
if __name__ == '__main__':
t1 = time.time()
print('主进程PID:',os.getpid())
process_list = []
for x in range(0, 5):
process = Process(target = sleep, args = (x,)) # 创建进程
process_list.append(process)
process.start() # 启用进程
# 等待所有进程结束
for process in process_list:
process.join()
t2 = time.time()
print('使用多进程,总共耗时 %s' % (t2 - t1))
运行结果为:
主进程PID: 14716
子进程ID: 12728
子进程ID: 11992
子进程ID: 356
子进程ID: 1992
子进程ID: 9076
使用多进程,总共耗时 4.118034839630127
需指出的时,这里是为主进程创建了多个子进程,因为这段代码它本身就是在一个进程中执行,从之前的多个例子中也可以看出。
对于进程的数量的限制不进行展开,因为在使用进程时,多使用的是进程池。
进程池
进程池的概念和线程池也类似,只是它里面是放的是创建的子进程而已,代码如下:
import time
from multiprocessing.pool import Pool
import os
def sleep(x):
print('子进程ID:',os.getpid())
time.sleep(x)
return 'Hello'
if __name__ == '__main__':
t1 = time.time()
print('主进程PID:',os.getpid())
pool = Pool(2) # 设置进程池数量
# 方法1
# groups = ([x for x in range(0, 5)]) # 构造任务列表
# pool.map(sleep, groups) # 执行任务
# pool.close()
# pool.join()
# 方法2
# for x in range(0, 5):
# pool.apply_async(sleep, (x,)) # 执行子进程
# pool.close()
# pool.join()
t2 = time.time()
print('使用进程池,总共耗时 %s' % (t2 - t1))
在方法1中,我们使用了map函数,来对我们任务列表中的任务进行执行;而在方法2中,我们使用了apply_async来执行任务,这主要是因为apply_async是异步非阻塞的,不用等待当前进程执行完毕,而不取使用阻塞的apply,若使用apply,所有的子进程就要排着队一个个等了。
程序执行结果为:
主进程PID: 12376
子进程ID: 1472
子进程ID: 1472
子进程ID: 1472
子进程ID: 9952
子进程ID: 9952
使用进程池,总共耗时 6.170445919036865
到这里,我们已经将异步、协程、线程(池)、进程(池)的程序都已经罗列出来,现在,我们需要对他们各种的性能进行比较,将每个程序的运行时间给提取出来,
多线程、多进程:
使用多线程,总共耗时 4.002230644226074
使用多进程,总共耗时 4.118034839630127
协程池、线程池、进程池:
使用协程池方法,总共耗时 6.006633043289185
使用线程池,总共耗时 6.00337815284729
使用进程池,总共耗时 6.170445919036865
协程池也可以看作是多协程的一种
我们可以看出,多进程的耗时多于多线程和协程的耗时,这主要是因为在多进程中进行进程切换时需要运行时间,因而其需要额外的运行时间。
结语
到这儿里了,你可能会问那我在编程的时候该用什么方法呢?多进程和多线程各有优缺点(可参阅该博客),多进程稳定性好,一个子进程崩溃了,不会影响主进程以及其余进程,但是其需要系统调度,代价较大;多线程效率较高一些,但是任何一个线程崩溃都可能造成整个进程的崩溃。爬虫,web等可使用多进程,数据分析等可使用多进程。对于协程,可中断控制,性能较好,效率高。所以说,在日常生活中使用那种方法还是要视情况(看会写那个吧)。但是,对于这些方法的组合,无疑可以达到百万并发!!!
以后将通过爬虫来进一步分析。
好好学习,天天向上!