基于PYNQ-Z2开发板实现矩阵乘法加速详细流程
基于PYNQ-Z2开发板实现矩阵乘法加速
主要内容
1、在Vivado HLS中生成矩阵乘法加速的IP核。
2、在Vivado中完成Block Design。
3、在Jupyter Notebook上完成IP的调用。
完整项目工程文件下载链接见文末
所需硬件
PYNQ-Z2开发板、USB数据线、网线
SD卡、读卡器
开发板配置参考链接
1、Vivado HLS生成矩阵乘法加速IP
- HLS硬件配置信息

- mul.h关键代码
#define MAT_A_ROWS 32
#define MAT_A_COLS 32
#define MAT_B_ROWS 32
#define MAT_B_COLS 32
typedef int mat_a_t;
typedef int mat_b_t;
typedef int result_t;
void matrixmul(
mat_a_t a[MAT_A_ROWS][MAT_A_COLS],
mat_b_t b[MAT_B_ROWS][MAT_B_COLS],
result_t res[MAT_A_ROWS][MAT_B_COLS]);
定义输入的a,b矩阵维度和输出矩阵的维度
- mul.cpp关键代码
#include "mul.h"
void matrixmul(
mat_a_t a[MAT_A_ROWS][MAT_A_COLS],
mat_b_t b[MAT_B_ROWS][MAT_B_COLS],
result_t res[MAT_A_ROWS][MAT_B_COLS])
{
int tempA[MAT_A_ROWS][MAT_A_COLS];
int tempB[MAT_B_ROWS][MAT_B_COLS];
int tempAB[MAT_A_ROWS][MAT_B_COLS];
for (int ia = 0; ia<MAT_A_ROWS ;ia++){
for(int ja = 0; ja< MAT_A_COLS; ja++){
tempA[ia][ja] = a[ia][ja];
}
}
for (int ib = 0; ib<MAT_B_ROWS ;ib++){
for(int jb = 0; jb< MAT_B_COLS; jb++){
tempB[ib][jb] = b[ib][jb];
}
}
/* for each row and column of AB */
row: for(int i = 0; i < MAT_A_ROWS; ++i) {
col: for(int j = 0; j < MAT_B_COLS; ++j) {
/* compute (AB)i,j */
int ABij = 0;
product: for(int k = 0; k < MAT_A_COLS; ++k) {
ABij += tempA[i][k] * tempB[k][j];
}
tempAB[i][j] = ABij;
}
}
for (int iab = 0; iab<MAT_A_ROWS ;iab++){
for(int jab = 0; jab< MAT_B_COLS; jab++){
res[iab][jab] = tempAB[iab][jab];
}
}
}
- 在约束文件中添加接口约束和循环流水,实现矩阵乘法的硬件加速

此处IP核使用ap_ctrl_none接口协议,输入的a,b矩阵和输出的res矩阵均使用axis流数据,注意流数据传输中Block Design中需添加DMAip核进行数据格式转换。 - 编写相关的C仿真代码,此处不表,详见项目文件。
进行C仿真

- C仿真结果

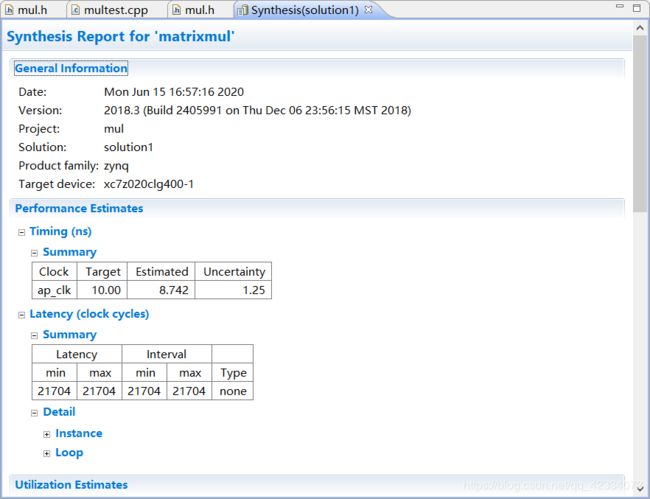
- 进行C综合
- 进行IP导出


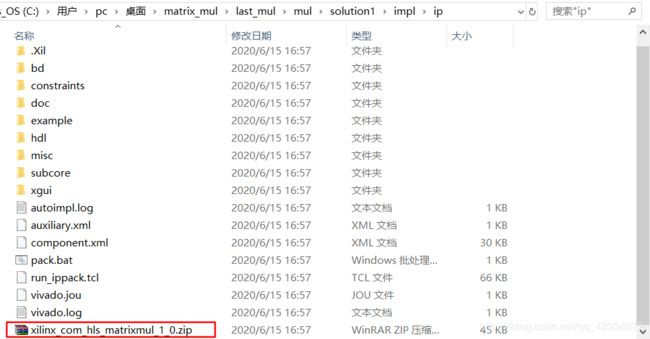
- 生成的IP在./solution1/impl/ip路径下,为一压缩包,如下图所示。
2、Vivado进行Block Design
-
Vivado硬件配置信息

-
添加Vivado HLS生成的IP,PROJECT MANAGER->Settings

-
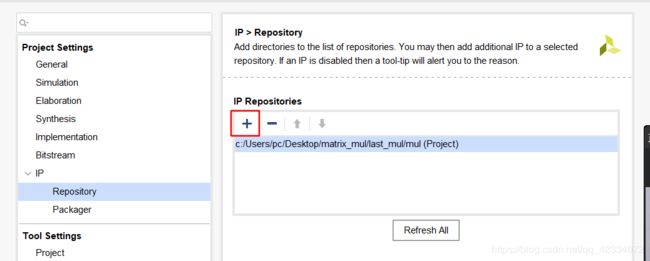
Project Settings->IP->Repository
- 点击+号,选择IP所在路径进行IP的添加
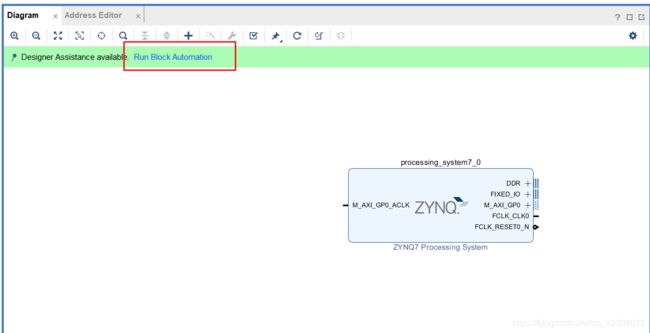
- 然后进行Block Design


- 首先添加ZYNQ的IP


- 双击生成的ZYNQip核,进行配置参数的修改,首先使能HP接口

- 取消勾选USB接口,然后点击OK

- 添加HLS编写的IP

- 添加两个DMA的IP
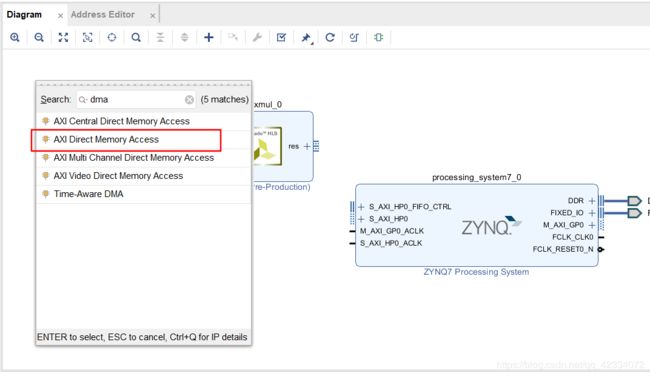
- 结果如下

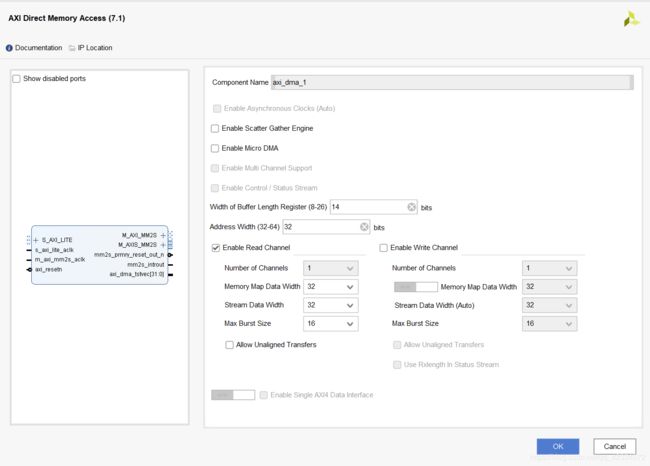
- 因为我们有两个AXI流数据的入口,一个AXI流数据的输出,所以要对DMA的读写端口数量进行修改,配置两个DMA的读端口,1个DMA的写端口。下面对DMA的IP参数进行设置。
- DMA0:

- DMA1:
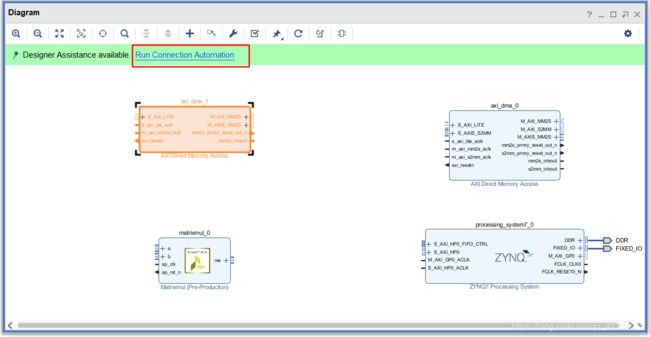
- 之后进行手动连线,下图中标黄的部分

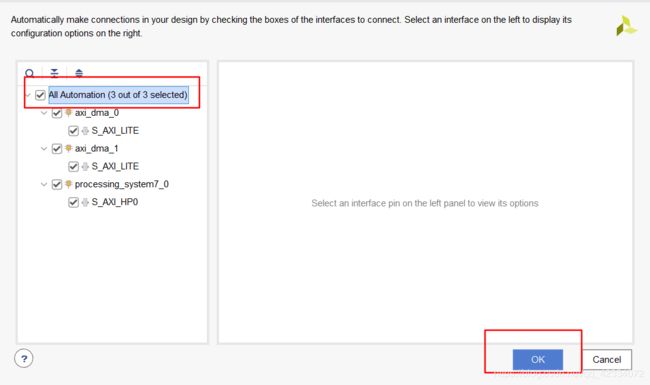
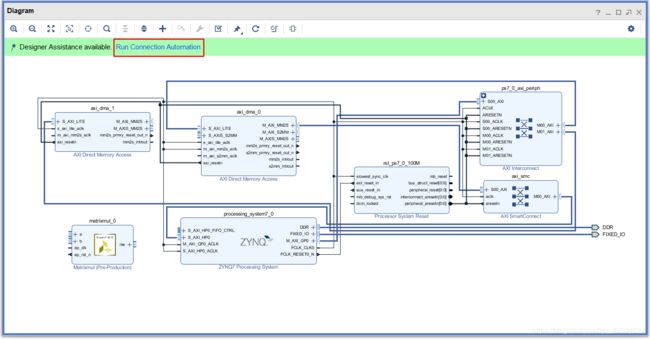
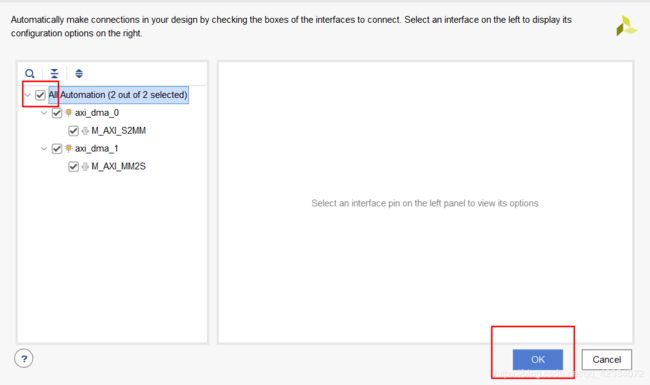
- 然后继续自动完成连线
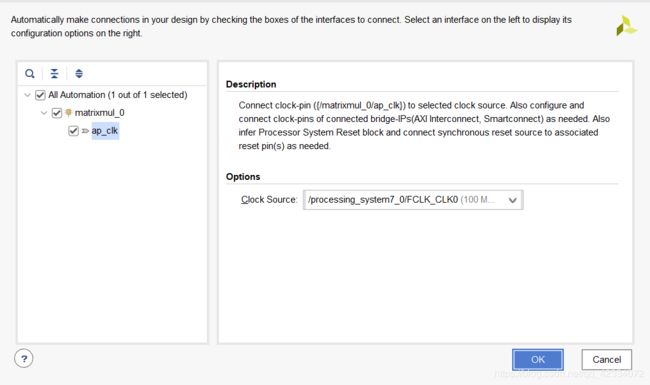
- 最终的Block如下图所示
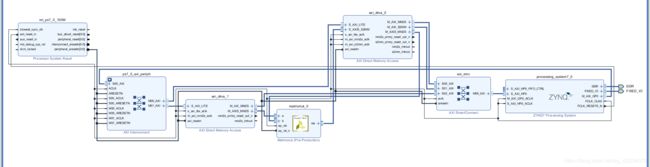
- 进行验证

- 此处出现警告信息,可以不管,主要是流数据的Last信号缺失。

- 之后生成顶层调用文件,右击顶层模块,点击Create HDL Wrapper…


- 之后生成BIT文件 PROGRAM AND DEBUG->Generate Bitstream


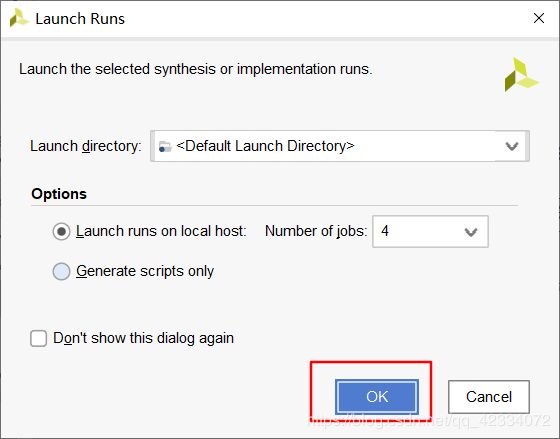
- Bitstream生成后弹出弹窗,点击cancel。然后点击File->Export->Export Hardware

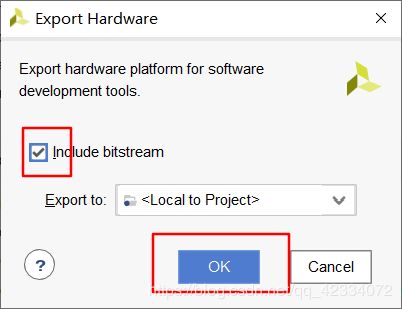
- 然后点击File->Export->Export Bitstream File,输出路径选择项目根目录。

- 在下图所示的路径中,找到.hwh文件,拷贝到文件的根目录。
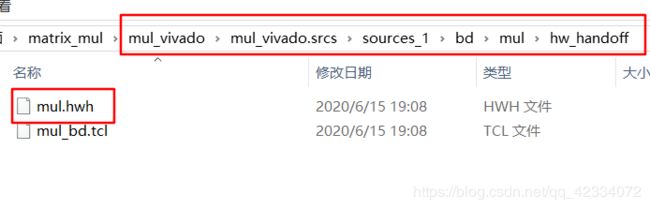
- 将bit文件、tcl文件和hwh文件重命名成一个名字,如下所示。

至此完成了Vivado相关的工作。
3、Jupyter Notebook进行矩阵乘法加速IP的调用
PYNQ-Z2板的详细配置过程见文章顶的相关链接,此处默认大家能正常启动板子。
- 在Jupyter Notebook上新建文件夹,进行文件的上传。点击Upload上传之前生成的bit文件、tcl文件和hwh文件。
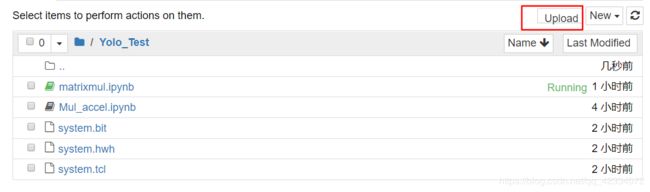

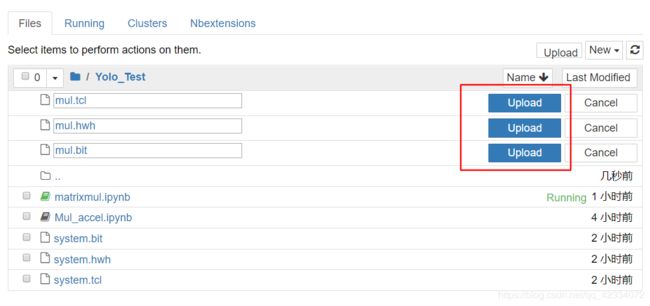
- 进行新建python文件操作

- python调用IP相关代码
import pynq.lib.dma
import numpy as np
mmol = pynq.Overlay("./mul.bit")
dma0 = mmol.axi_dma_0
dma1 = mmol.axi_dma_1
from pynq import Xlnk
xlnk = Xlnk()
a = xlnk.cma_array(shape=(32,32), dtype=np.int)
b = xlnk.cma_array(shape=(32,32), dtype=np.int)
res = xlnk.cma_array(shape=(32,32), dtype=np.int)
for i in range(32):
for j in range(32):
a[i][j] = 8;
b[i][j] = 8;
dma0.sendchannel.transfer(a)
dma1.sendchannel.transfer(b)
dma0.recvchannel.transfer(res)
print(res)
- 点击run查看结果
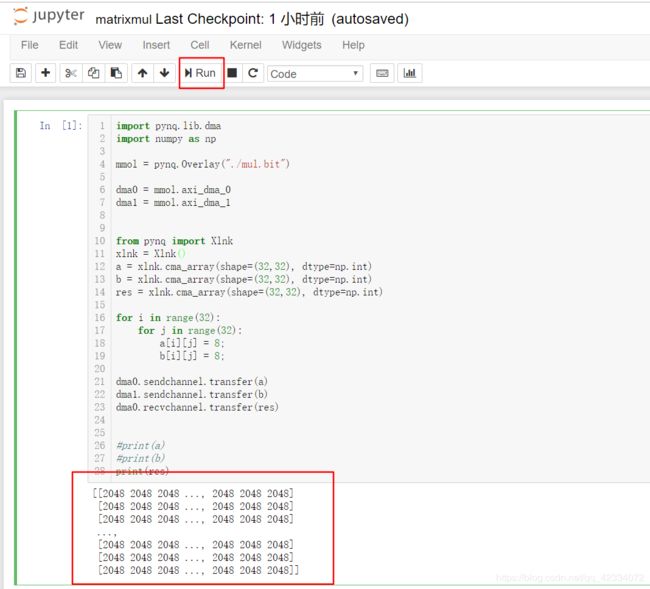
传入的a,b矩阵为32*32的矩阵,元素均为8。结果显示乘法IP核调用正常。
项目工程下载链接
[2020.6.18更新,解决Block Design中TLAST管脚警告的问题]
改变数据类型
mul.c:
#include "mul.h"
void matrixmul(
mat_a_t a[SIZE],
mat_b_t b[SIZE],
result_t res[SIZE])
{
int tempA[MAT_A_ROWS][MAT_A_COLS];
int tempB[MAT_B_ROWS][MAT_B_COLS];
int tempAB[MAT_A_ROWS][MAT_B_COLS];
for (int ia = 0; ia<MAT_A_ROWS ;ia++){
for(int ja = 0; ja< MAT_A_COLS; ja++){
tempA[ia][ja] = a[ia*MAT_A_ROWS+ja].data;
}
}
for (int ib = 0; ib<MAT_B_ROWS ;ib++){
for(int jb = 0; jb< MAT_B_COLS; jb++){
tempB[ib][jb] = b[ib*MAT_A_ROWS+jb].data;
}
}
/* for each row and column of AB */
row: for(int i = 0; i < MAT_A_ROWS; ++i) {
col: for(int j = 0; j < MAT_B_COLS; ++j) {
/* compute (AB)i,j */
int ABij = 0;
product: for(int k = 0; k < MAT_A_COLS; ++k) {
ABij += tempA[i][k] * tempB[k][j];
}
tempAB[i][j] = ABij;
}
}
for (int iab = 0; iab<MAT_A_ROWS ;iab++){
for(int jab = 0; jab< MAT_B_COLS; jab++){
res[iab*MAT_A_ROWS+jab]=push_stream<int>(tempAB[iab][jab],iab==(MAT_A_ROWS-1)&&jab==(MAT_B_COLS-1));
}
}
}
mul.h:
#ifndef __MATRIXMUL_H__
#define __MATRIXMUL_H__
#include 使用ap_axis数据类型,其中含有last信号,需对最后一次输出的信号的last信号赋1。或者自己定义数据类型的结构体,含last信号即可。这时进行Block Design的验证时不会再报TLAST信号丢失的Warning。