详解python中的正则表达式
文章目录
- Python正则表达式
- 正则表达式元字符
- .(点)
- [](方括号)
- ^(插入符)
- $(dollar符)
- \(反斜杠)
- |(竖线)
- 其他
- 正则特性
- 重复
- *(星号)
- +(加号)
- ?(问号)
- {}(花括号)
- 贪婪匹配与非贪婪匹配
- 正则中的组选择
- ()(括号)
- 做一个练习
- 使用正则表达式切割字符串
Python正则表达式
- 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
- re 模块使 Python 语言拥有全部的正则表达式功能。
- compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
- re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。
正则表达式元字符
.(点)
- 点是匹配除换行符以外的任何单个字符
例子:
content = '''
苹果,是绿色的
橙子,是橙色的
草莓,是红色的
乌鸦,是黑色的
'''
import re
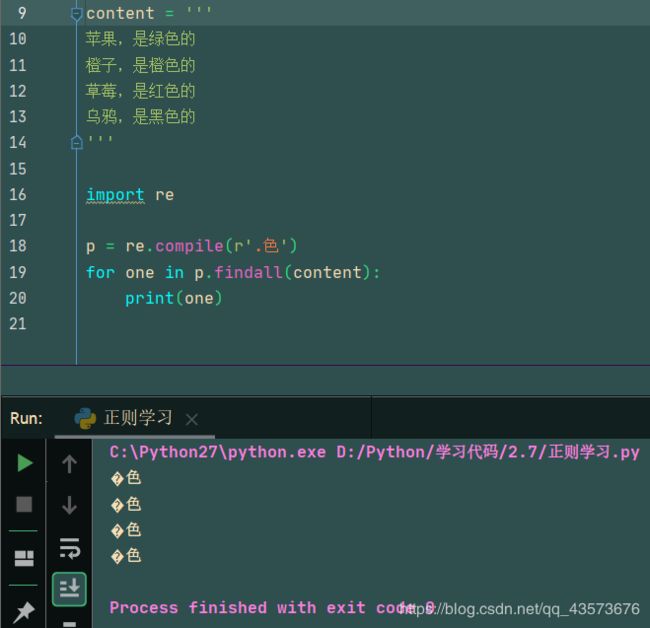
p = re.compile(r'.色')
for one in p.findall(content):
print(one)
图形化正则:
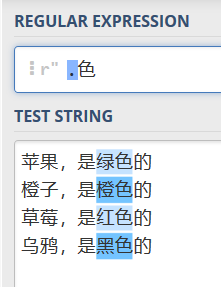
运行结果(我这里字符编码出了些问题…):
[](方括号)
- 常用来指定一个字符集,例如:[abc]或[a-z]
- 元字符在字符集中不起作用,例如:[asd$]
- 补集匹配不在区间范围内的字符,例如:[^5]
写了这些理论,不如来一个例子体会一下这个[]元字符是什么效果:
content = '''
苹果,是绿色的
橙子,是橙色的
草莓,是红色的
乌鸦,是黑色的
'''
import re
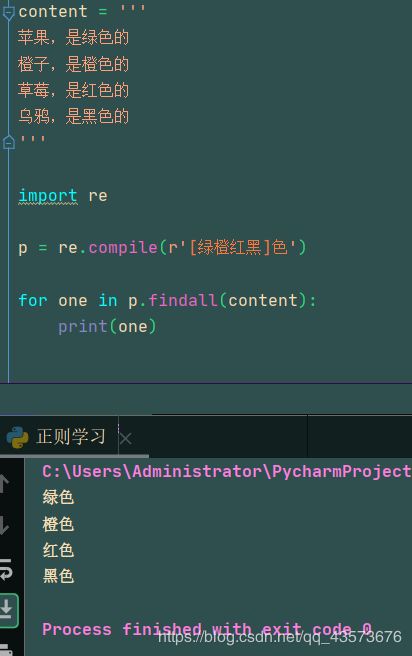
p = re.compile(r'[绿橙红黑]色')
for one in p.findall(content):
print(one)
图形化正则:
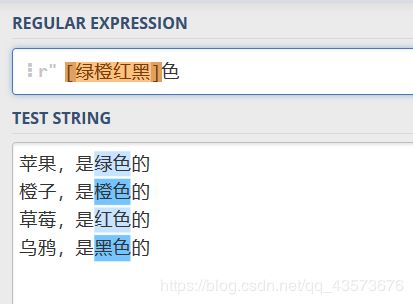
运行结果:
它还可以这样玩:
content = '''
小李,156888z7894,21
小张,18866716789,23
小王,13512342233,26
小崔,y3552342133,18
小刘,g3510348233,35
小唐,a3211232243,42
'''
import re
p = re.compile(r'[a-z]\d{10}')
for one in p.findall(content):
print(one)
图形化正则:
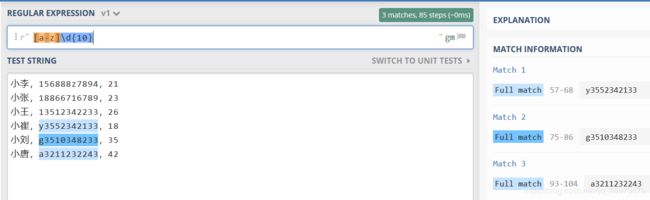 运行结果:
运行结果:

如果在方括号中使用 ^ , 表示 非 方括号里面的字符集合,例如:
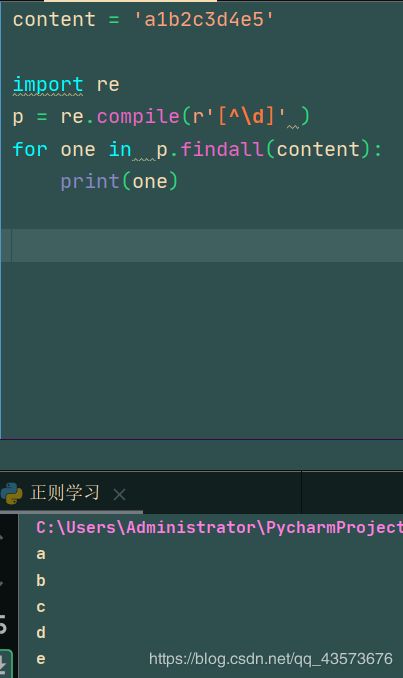
content = 'a1b2c3d4e5'
import re
p = re.compile(r'[^\d]' )
for one in p.findall(content):
print(one)
图形化正则:

运行结果:
^(插入符)
- 匹配行首,除非设置MULTILINE标志,他只是匹配字符串的开始。
- 在MULTILINE模式里,它也可以匹配每个字符串中的换行
正则表达式可以设定 单行模式 和 多行模式
如果是 多行模式 ,表示匹配 文本每行 的开头位置。
如果是 单行模式 ,表示匹配 整个文本 的开头位置。
比如,下面的文本中,每行最前面的数字表示水果的编号,最后的数字表示价格
001-苹果价格-60,
002-橙子价格-70,
003-香蕉价格-80,
例子:
content = '''
001-苹果价格-60,
002-橙子价格-70,
003-香蕉价格-80,
'''
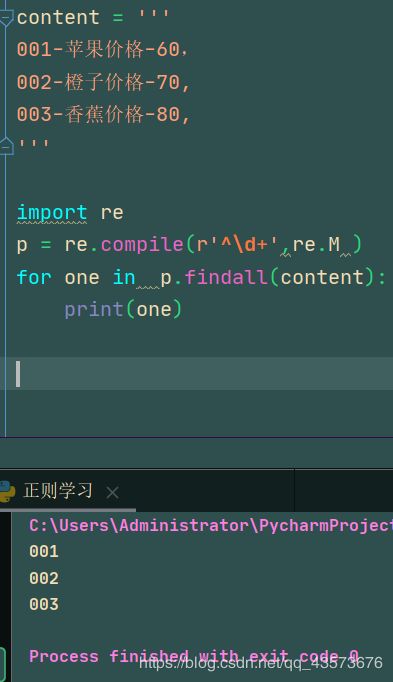
import re
p = re.compile(r'^\d+',re.M )
for one in p.findall(content):
print(one)
图形化正则:
运行结果可以看到,^只匹配行首的所有数字,这里的re.M是指定当前为多行模式:
$(dollar符)
- 效果同^,之不过它匹配的是行尾的字符集
- 匹配行尾,要么是一个字符串的行尾,要么是换行符后面的任何位置。
例子:
content = '''
001-苹果价格-60
002-橙子价格-70
003-香蕉价格-80
'''
import re
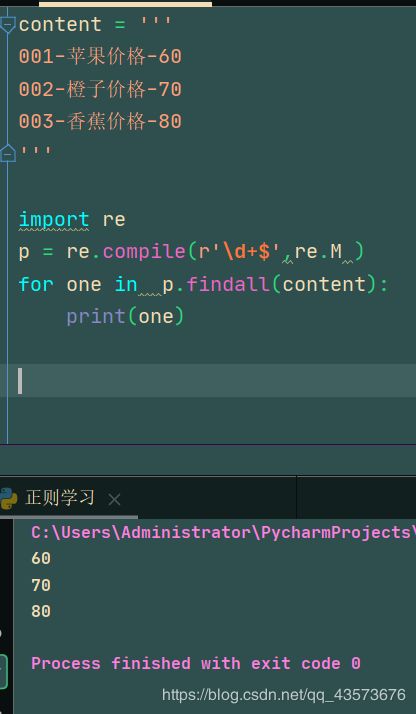
p = re.compile(r'\d+$',re.M )
for one in p.findall(content):
print(one)
图形化正则:
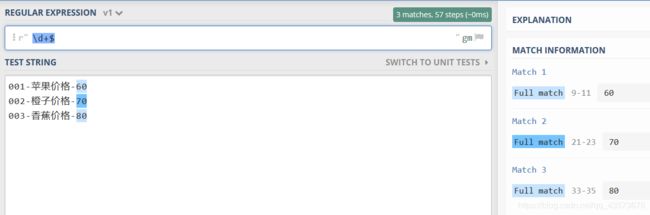
运行结果可以看到,它把所有的价格都打印出来了:
\(反斜杠)
- 把元字符转换为普通符号的时候用\来转移
简单点说,就跟输出字符串前加一个r,取消字符串里的转义效果是一样的,上一个例子就明白了:
import re # 导入re包
a = 'tp,top$,toop,top' # 定义一个字符串a
c = r'top\$' # 这里加了\
print re.findall(c,a) # 用规则c去匹配字符a并输出
运行结果:

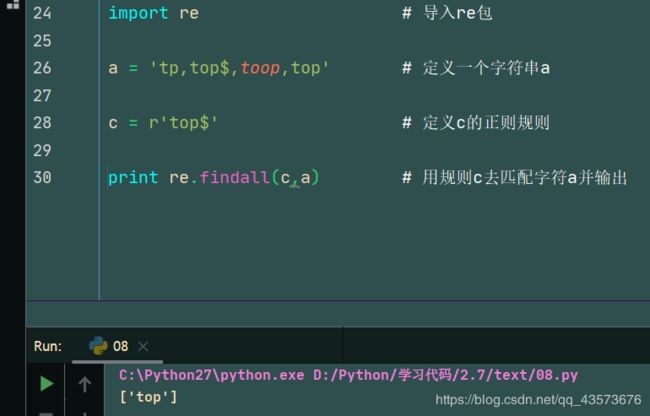
再来一个没加 \ 的
import re # 导入re包
a = 'tp,top$,toop,top' # 定义一个字符串a
c = r'top$' # 定义c的正则规则
print re.findall(c,a) # 用规则c去匹配字符a并输出
对比一下,就知道这个 \ 是干吗用的了:
|(竖线)
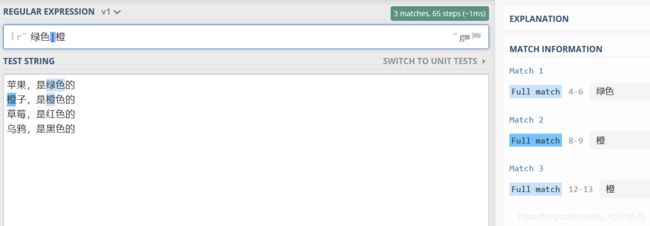
- 竖线表示 匹配 其中之一 。
特别要注意的是, 竖线在正则表达式的优先级是最低的, 这就意味着,竖线隔开的部分是一个整体
比如 绿色|橙 表示 要匹配是 绿色 或者 橙 ,
而不是 绿色 或者 绿橙
例如:
其他
\d:匹配数字,效果同[0-9]
\d 表示匹配任意一个数字,这里可以不写[],直接使用\d
[^\d] 表示匹配所有的非数字字符,效果同[^0-9]
例子:
import re
content = '123,456,789'
p = re.compile(r'\d')
for one in p.findall(content):
print(one)
运行结果:

\D:匹配非数字字符,效果同[^0-9]
例子:
import re # 导入re包
a = 'tpt 123 456 789' # 定义一个字符串a
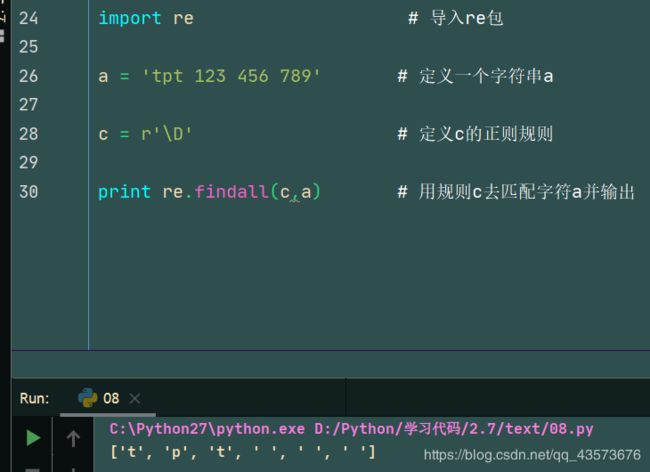
c = r'\D' # 定义c的正则规则
print re.findall(c,a) # 用规则c去匹配字符a并输出
运行结果:
\w:匹配数字、字母和下划线,效果同[0-9a-zA-Z]
例子:
import re # 导入re包
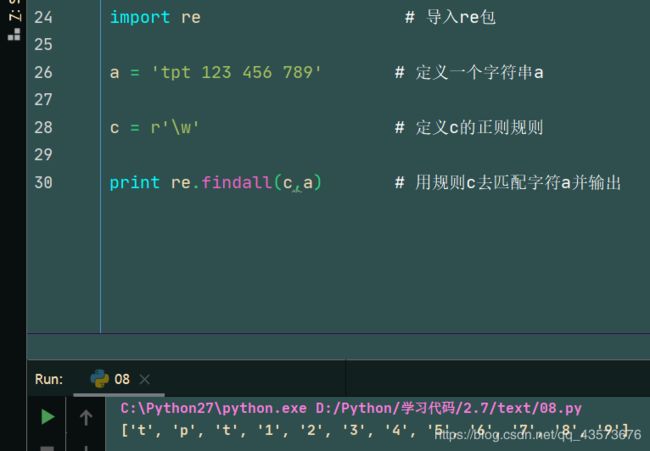
a = 'tpt 123 456 789' # 定义一个字符串a
c = r'\w' # 定义c的正则规则
print re.findall(c,a) # 用规则c去匹配字符a并输出
运行结果:
\W:匹配非数字、字母和下划线,效果同[^0-9a-zA-Z]
例子:
import re # 导入re包
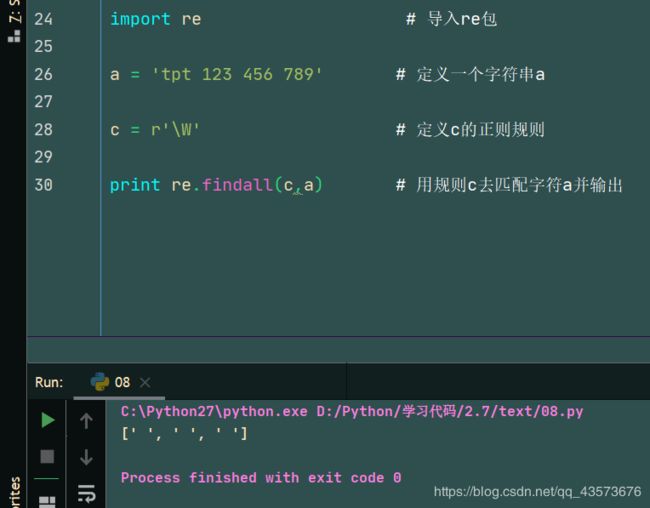
a = 'tpt 123 456 789' # 定义一个字符串a
c = r'\W' # 定义c的正则规则
print re.findall(c,a) # 用规则c去匹配字符a并输出
运行结果:
\s:匹配任意的空白符(空格、换行、回车、换页、制表符),效果同[ \f\n\r\t]
例子:
import re # 导入re包
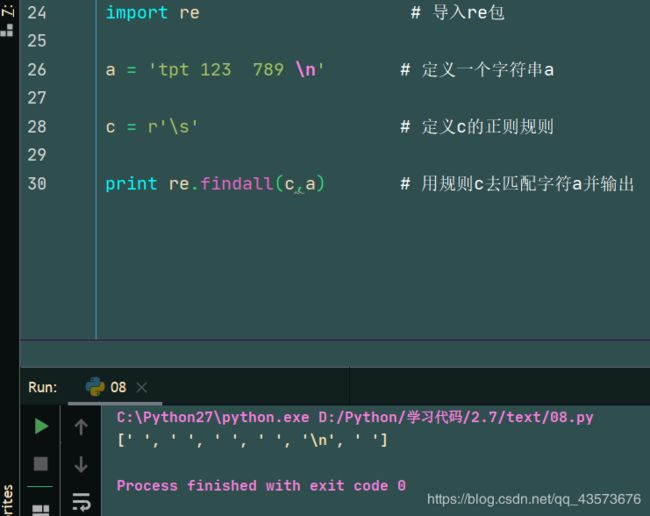
a = 'tpt 123 789 \n' # 定义一个字符串a
c = r'\s' # 定义c的正则规则
print re.findall(c,a) # 用规则c去匹配字符a并输出
运行结果:
\S:匹配任意的非空白符(空格、换行、回车、换页、制表符),效果同[^ \f\n\r\t]
例子:
import re # 导入re包
a = 'tpt 123 789 \n' # 定义一个字符串a
c = r'\S' # 定义c的正则规则
print re.findall(c,a) # 用规则c去匹配字符a并输出
运行结果:

正则特性
重复
例子:
import re # 导入re包
a = 'tpt 010-88888888 abc 123' # 定义一个字符串a
c = r'\d{3}-\d{8}' # 重复匹配三次数字-重复匹配八次数字
print re.findall(c,a) # 用规则c去匹配字符a并输出
运行结果:

*(星号)
- 星号的作用就是指定前一个字符可以被匹配0次或更多次,匹配引擎会试着重复(贪婪匹配,尽可能多的去匹配)
例子:
content = '''
苹果,是绿色色色色色的
橙子,是橙色的
草莓,是红色的
乌鸦,是黑色的
'''
import re
p = re.compile(r'绿色*')
for one in p.findall(content):
print(one)
图形化正则:
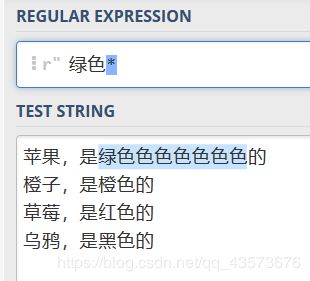
运行结果:
+(加号)
- 加号表示匹配至少一次或多次,也是贪婪匹配(尽可能多的去匹配)
这里的加号,一定要跟星号对比起来,搞清楚两者的区别,星号是可以出现0次的,但加号至少要出现一次,这就是两者的区别,这样说很模糊,我上两个例子大家体会一下
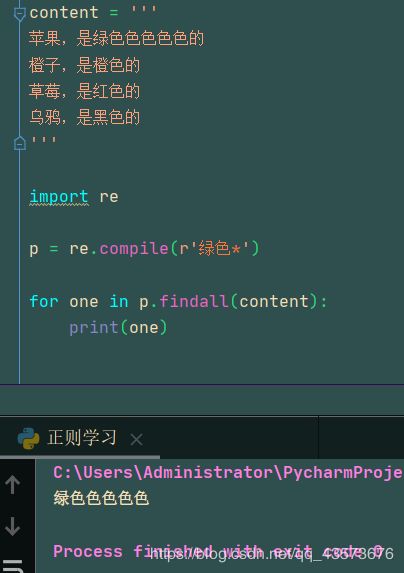
星号例子:
content = '''
苹果,是绿色色色色色色色的
橙子,是橙色的
草莓,是红色的
乌鸦,是绿色的
猴子,是绿
'''
import re
p = re.compile(r'绿色*')
for one in p.findall(content):
print(one)
运行结果:
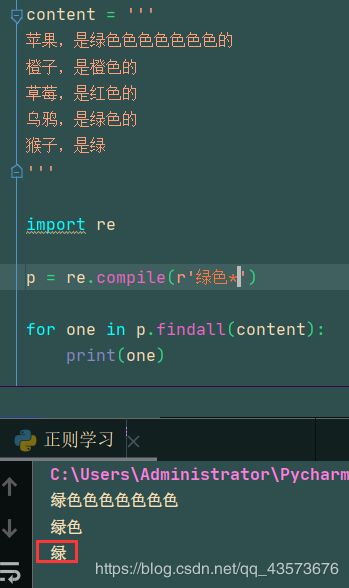
加号例子(代码就不贴了):
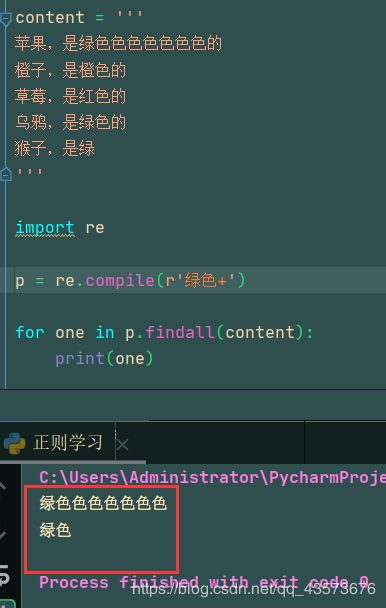
因为星号包括0次,所以绿后面即使没有字符,也可以被输出,但是加号至少包含一次,所以单个绿就不会被输出,因为它后面是0个色,要求是至少一个色,我们可以借助两者的图形化正则来对比,就很容易明白他们的区别了:
加号:

星号:
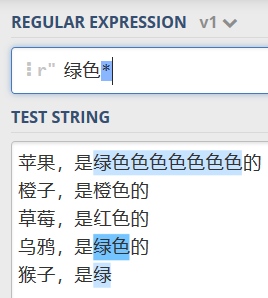
?(问号)
- 问号就是最小匹配它前面的字符,匹配一次或零次
例子:
content = '''
苹果,是绿色色色色色色色的
橙子,是橙色的
草莓,是红色的
乌鸦,是绿色的
猴子,是绿
'''
import re
p = re.compile(r'是.色?')
for one in p.findall(content):
print(one)
图形化正则:

因为它允许匹配零次,所以最后一句即使后面没有色,是绿也会被输出,看一下运行结果:
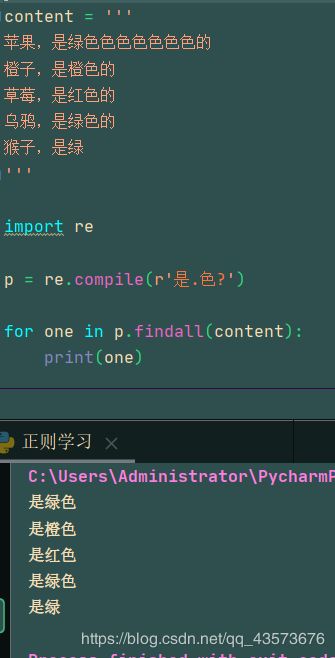
{}(花括号)
正则的一个特性是你可以匹配任意长度字符集,另一个就是你可以指定表达式的一部分重复次数
这里提到的这个{},作用是指定重复次数,用它搭配\d来实现一个过滤手机号码的脚本:
content = '''
小李,15688887894,21
小张,18866716789,23
小王,13512342233,26
小崔,13552342133,18
小刘,13510348233,35
小唐,13211232243,42
'''
import re
p = re.compile(r'\d{11}')
for one in p.findall(content):
print(one)
图形化正则:

运行结果:

贪婪匹配与非贪婪匹配
假如我们现在定义了一个字符集,要把下面的标签全部都取出来
content = '要这种效果:
['', ''</span><span class="token punctuation">,</span> <span class="token string">' ', '']
思路大概已经有了,就是匹配尖括号里的内容即可:
content = '但是这样输出的结果是这样的:
['这就不符合题意了,这也就是所谓的“贪婪匹配”,就是尽可能多的去匹配,两个尖括号中间的,那么我就取整个字符集好了,刚好就是两个尖括号组成的,所以我们想要符合题意,就要对星号进行限制,就是给它加一个问号
content = '这样运行后就符合题意了,可以看一下加问号与不加问号的图形化正则:
加问号:
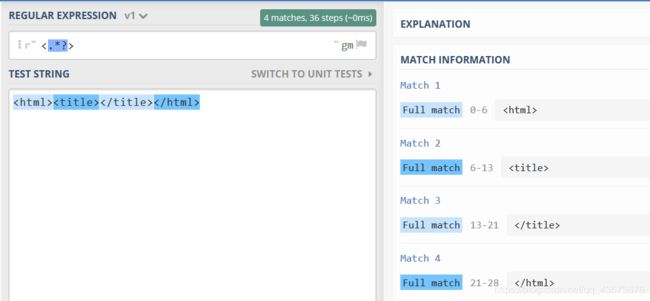
不加:
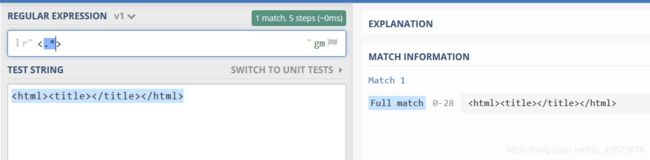 所以在日后的编程中要注意星号与加号,如果想要尽可能少,就加问号,反之不加。
所以在日后的编程中要注意星号与加号,如果想要尽可能少,就加问号,反之不加。
正则中的组选择
()(括号)
-
括号称之为 正则表达式的 组选择。
-
组 就是把 正则表达式 匹配的内容 里面 其中的某些部分 标记为某个组。
-
我们可以在 正则表达式中 标记 多个 组
为什么要有组的概念呢?因为我们往往需要提取已经匹配的 内容里面的 某些部分的信息。 前面,我们有个例子,从下面的文本中,选择每行逗号前面的字符串,也包括逗号本身 。苹果,苹果是绿色的 橙子,橙子是橙色的 香蕉,香蕉是黄色的
代码可以这样写:
content = '''
苹果,苹果是绿色的
橙子,橙子是橙色的
香蕉,香蕉是黄色的
'''
import re
p = re.compile(r'.*,')
for one in p.findall(content):
print(one)
但是运行后输出的结果带着逗号,我们又不希望逗号出现,所以我们在这里使用()把前面的规则括起来,表示我们只取括号内的信息:
content = '''
苹果,苹果是绿色的
橙子,橙子是橙色的
香蕉,香蕉是黄色的
'''
import re
p = re.compile(r'(.*),')
for one in p.findall(content):
print(one)
图形化正则:

运行结果:

那么这是一组的,如果我们要提取多组呢?比如我们现在从网上抓取了一组数据,要求只输出姓名+电话号码
张三,手机号13388881234
李四,手机号15612348821
王五,手机号17456136666
那么代码可以这样写:
content = '''
张三,手机号13388881234
李四,手机号15612348821
王五,手机号17456136666
'''
import re
p = re.compile(r'(^.+),手机号(\d{11})',re.M)
for one in p.findall(content):
print(one)
图形化正则:
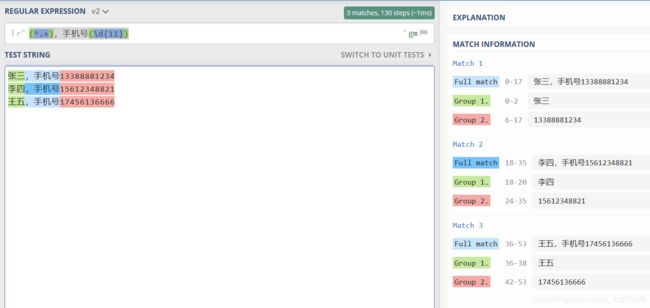
运行结果:
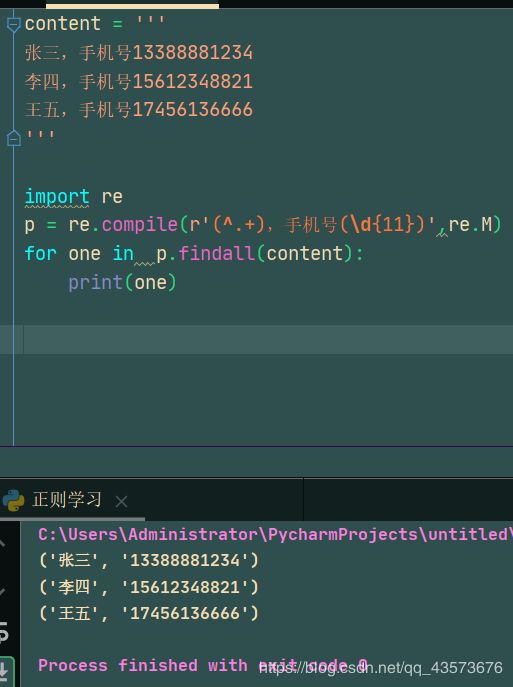
做一个练习
现在我们从网上抓取了一则招聘信息,要求只输出薪资数字:
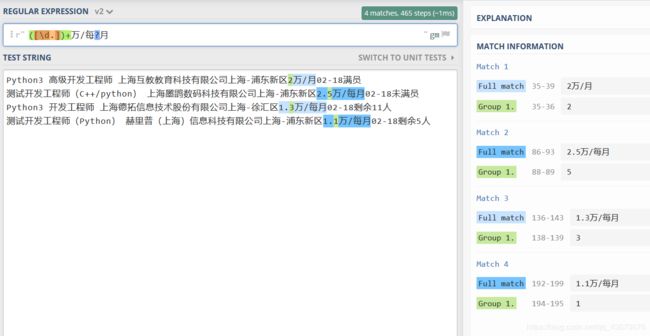
Python3 高级开发工程师 上海互教教育科技有限公司上海-浦东新区2万/月02-18满员
测试开发工程师(C++/python) 上海墨鹍数码科技有限公司上海-浦东新区2.5万/每月02-18未满员
Python3 开发工程师 上海德拓信息技术股份有限公司上海-徐汇区1.3万/每月02-18剩余11人
测试开发工程师(Python) 赫里普(上海)信息科技有限公司上海-浦东新区1.1万/每月02-18剩余5人
那么表达式可以这么写:
([\d.]+)万/每?月
[\d.]+ 表示 匹配 数字或者点的多次出现 这就可以匹配像: 3 33 33.33 这样的 数字
万/每?月 是后面紧接着的,如果没有这个,就会匹配到别的数字, 比如 Python3 里面的3。
其中 每?月 这部分表示匹配 每月 每 这个字可以出现 0次或者1次。
所以代码这么写:
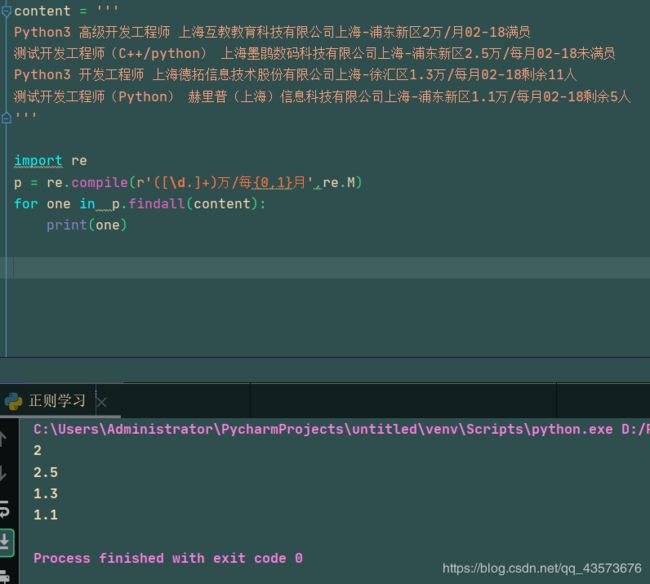
content = '''
Python3 高级开发工程师 上海互教教育科技有限公司上海-浦东新区2万/月02-18满员
测试开发工程师(C++/python) 上海墨鹍数码科技有限公司上海-浦东新区2.5万/每月02-18未满员
Python3 开发工程师 上海德拓信息技术股份有限公司上海-徐汇区1.3万/每月02-18剩余11人
测试开发工程师(Python) 赫里普(上海)信息科技有限公司上海-浦东新区1.1万/每月02-18剩余5人
'''
import re
p = re.compile(r'([\d.]+)万/每{0,1}月',re.M)
for one in p.findall(content):
print(one)
图形化正则:
运行结果:
使用正则表达式切割字符串
- 字符串对象的split()方法只适用于简单的字符串分割,有时你需要更加灵活的字符串切割。
比如,我们需要从下面字符串中提取武将的名字:
names = '关羽; 张飞, 赵云,马超, 黄忠 李逵'
我们发现这些名字之间, 有的是分号隔开,有的是逗号隔开,有的是空格隔开, 而且分割符号周围还有不定数量的空格
这时,可以使用正则表达式里面的 split 方法:
import re
names = '关羽; 张飞, 赵云,马超: 黄忠 李逵'
namelist = re.split(r'[;,:\s]\s*',names)
print(namelist)
\s表示空格,它后面为什么加*而不加+呢?是因为 可以匹配0到任意次,而+至少匹配一次,题中的“赵云,马超”中间没有空格,所以\s就出现了0次,为了能够分别正确输出他们,所以采用\s,即使没有出现空格,也要给我匹配上。
运行结果:
