deepLabV3+ 阅读笔记
原文 :Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
Abstract: 结合spp模块和encode-decode结构的优点提出的新的语义分割结构deepLabV3+。除此之外,作者还对ASPP模块和decode模块应用了Xception结构和分离卷积,应用这两个结构后的整个模型变得faster和stronger。deepLavV3+在PASCAL VOC 2012和Cityscapes 两个数据集上取得了state-of-art。
1. Introduction
空间金字塔池化模块(spatial pyramid pooling,SPP)通过在不同尺度上对特征图做池化操作可以提取更丰富的语义信息。encode-decode结构可以使物体边界的分割结果更精细。
一方面deepLabV3 通过应用几个并行的具有不同比率的空洞卷积提取不同尺度上的语义信息,这种类似PSPNet的结构本称为 Astrous Spatial Pyramid Pooling 模块(ASPP),ASPP与PSPNet不同的是PSPNet是在不同的grid scale 上 执行Pooling操作。
 另一方面在encode-decode 结构中由于encode过程没有使用空洞卷积所以计算的更快,同时decode过程可以比较好的逐步恢复物体的边界信息。作者把ASPP模块融合基于deepLabV3的encode模块中由此提出了deepLabV3+结构。除此之外作者还对ASPP模块和decode模块应用了空洞分离卷积操作。最终,deepLabV3+在PACAL VOC2012和Cityscapes两个数据集上取得state-of-art。
另一方面在encode-decode 结构中由于encode过程没有使用空洞卷积所以计算的更快,同时decode过程可以比较好的逐步恢复物体的边界信息。作者把ASPP模块融合基于deepLabV3的encode模块中由此提出了deepLabV3+结构。除此之外作者还对ASPP模块和decode模块应用了空洞分离卷积操作。最终,deepLabV3+在PACAL VOC2012和Cityscapes两个数据集上取得state-of-art。
insumary
- 基于deepLabV3 提出了新的encode-decode的语义分割结构,和一个简单但有效的decode模块。
- 通过设置空洞卷积可以调整encode模块输出的特征图大小以调节精度和运行时间之间的平衡,这是其它encode-decode结构没有的有点。
- 为语义分割任务调整了Xception模块同时对于ASPP和decode模块应用深度分离卷积结构,使得整个网络faster and stronger。
2. Related Work
- Spatial pyramid pooling:Pspnet、 DeepLab、ASPP
Pyramid Scene Parsing Network提出了PSPNet网络,其中最重要的就是PSP模块,作为SPP家族的一员这个模块主要用于获取多尺度information,模块结构如下图所示。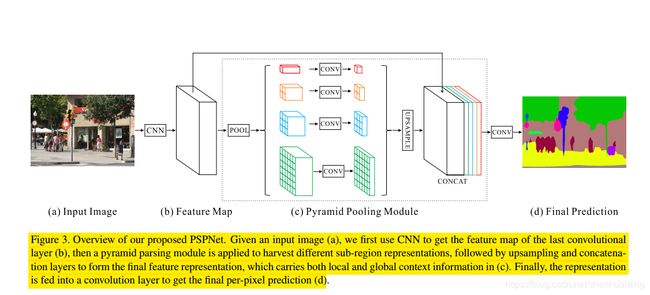 上图中的(a)为输入的图像,(b)深度网络提取的特征图,(c)则为psp模块。c图可以看出,psp模块从4个尺度并行的对Feature Map进行了pooling,其中第一个尺度为global_avg_pooling所以输出的结果为分辨率为1x1。第二个尺度上把featureMap划分为4个区域然后对这4个区域avg_pooling所以输出结果的分辨率为2x2。第三、第四个尺度上,avg_pooling的结果分辨率分别为3x3和6x6。每个尺度上得到结果用卷积核大小为1x1的卷积减少通道数,每个尺度上的通道数为输入特征图通道数的1/4。然后对降维后的结果分别上采样,从而使每个尺度上输出结果的分辨率与输入特征图分辨率相同,最后把每个尺度上结果和输入的特征图并联得到psp模块的输出。这里贴上一段pytorch实现的一段代码更有助于理解psp模块:
上图中的(a)为输入的图像,(b)深度网络提取的特征图,(c)则为psp模块。c图可以看出,psp模块从4个尺度并行的对Feature Map进行了pooling,其中第一个尺度为global_avg_pooling所以输出的结果为分辨率为1x1。第二个尺度上把featureMap划分为4个区域然后对这4个区域avg_pooling所以输出结果的分辨率为2x2。第三、第四个尺度上,avg_pooling的结果分辨率分别为3x3和6x6。每个尺度上得到结果用卷积核大小为1x1的卷积减少通道数,每个尺度上的通道数为输入特征图通道数的1/4。然后对降维后的结果分别上采样,从而使每个尺度上输出结果的分辨率与输入特征图分辨率相同,最后把每个尺度上结果和输入的特征图并联得到psp模块的输出。这里贴上一段pytorch实现的一段代码更有助于理解psp模块:
class PSPModule(nn.Module):
"""
Reference:
Zhao, Hengshuang, et al. *"Pyramid scene parsing network."*
"""
def __init__(self, features, out_features=512, sizes=(1, 2, 3, 6)):
super(PSPModule, self).__init__()
self.stages = []
self.stages = nn.ModuleList([self._make_stage(features, out_features, size) for size in sizes])
self.bottleneck = nn.Sequential(
nn.Conv2d(features+len(sizes)*out_features, out_features, kernel_size=3, padding=1, dilation=1, bias=False),
nn.BatchNorm2d(out_features),
nn.LeakyReLU(),
nn.Dropout2d(0.1)
)
def _make_stage(self, features, out_features, size):
“”“
psp模块中的并行支路通过本函数实现,AdaptiveAvgPool2d对特征图实现分区pooling,其输出结果的大小为(size,size)然后通过nn.Conv2d降维。
”“”
prior = nn.AdaptiveAvgPool2d(output_size=(size, size))
conv = nn.Conv2d(features, out_features, kernel_size=1, bias=False)
bn = nn.BatchNorm2d(out_features)
act= nn.LeakyReLU()
return nn.Sequential(prior, conv, bn,act)
def forward(self, feats):
h, w = feats.size(2), feats.size(3)
#h,w为psp模块输入的特征图的大小。
#下面这两行代码对4路并行pooling的后上采样的结果和输入特征图进行cat操作。
priors = [F.interpolate(input=stage(feats), size=(h, w), mode='bilinear', align_corners=True) for stage in self.stages] + [feats]
bottle = self.bottleneck(torch.cat(priors, 1))
return bottle
- Encoder-decoder:
- Depthwise separable convolution:参考另一篇笔记Xception阅读笔记
- 下图为文章中提出的基于DeepLabV3的DeepLabV3+的语义分割模型结构图。

3.Methods
本节对于空洞卷积、深度分离卷积、和modified Xception模块进行简介。
3.1 使用空洞卷积的encode-decode模型
- 空洞卷积: 空洞卷积可以明确的设定深度卷积网络的特征图大小,同时也可以通过设定卷积核感受视野大小通过卷积操作提取多尺度信息。下图(a)为常规的卷积操作,9个红点代表卷积核的9个权重。图(b)为 atrous rate 等于2的空洞卷积,同样有9个权重,但是这个卷积核的感受视野变大了,在卷积运算时只与红点所在位置的输入进行运算,而绿色部分输入被忽略。图(c)为atrous rate等于4的空洞卷积。。

-
深度分离卷积
深度分离卷积把标准卷积分解为深度卷积和点对点卷积(卷积核大小为1x1的标准卷积),这样的结构可以极大减少计算复杂度和模型参数量。对于标准的卷积操作来说,当输入的特征图为(C,W,H)=(3,6,6),output_channels=8时,那将有8个不同的卷积核,这8个卷积核中每一个卷积核将与输入的3个通道中的每一个通道进行卷积运算,卷积运算的3个结果求和取均值则得到了这其中一个卷积核的运算结果,剩下的卷积核依次如此计算,最终得到8通道的结果,这就是标准卷积操作的结果。而深度分离卷积在做同样的卷积操作时,分为 深度卷积 和 逐点卷积,(1)深度卷积 使用C个卷积核即卷积核的个数与输入的通道数相等,然后这个3个卷积核一对一的对输入的特征图进行卷积。如下图(a)空洞深度卷积如图(c)(2)使用通道数为8的点对点卷积(卷积核大小为1的标准卷积)对第一步输出的C个结果进行卷积,这样就可以得到通道数为8的结果。深度分离卷积可以参考 Separable Convolution

-
使用DeepLabV3当做encode DeepLabv3 采用了使用了空洞卷积的深度卷积神经网络可以以任意分辨率提取特征。 此处的stride表示为输入图像空间分辨率与最终输出分辨率的比率(输出分辨率为在全局池化或完全连接的层之前网络输出的特征)。对于分类任务来说,最终输出的特征图的分辨率一般为输入分辨率的1/32,因此可以认为stride=32。对于语义分割的任务,可以通过去除最后一个(或两个)块中的stride并相应地应用空洞卷积输出stride = 16(或8)来进行更密集的特征提取。此外,DeepLabv3增强了ASPP模块,该模块通过应用具有不同比率的空洞卷积和图像级特征来获取多尺度的卷积特征。在本文提出的encode-decode结构中,使用deepLabV3模型中logit运算之前的最后一层特征图作为本结构中的encode模块的输出,输出的通道数为256。
-
提出的decode结构 来自DeepLabV3的encoder输出特征图通常为输入的1/16。在Rethinking the Inception Architecture for Computer Vision一文中,这些encoder输出的特征被双线性上采样16倍,这可以被认为是一个简单的decode模块。但是这种简单的decoede模块不能很好的恢复物体的边缘信息。因此文中提出了一个同样简单但非常有效的decode模块如下图。
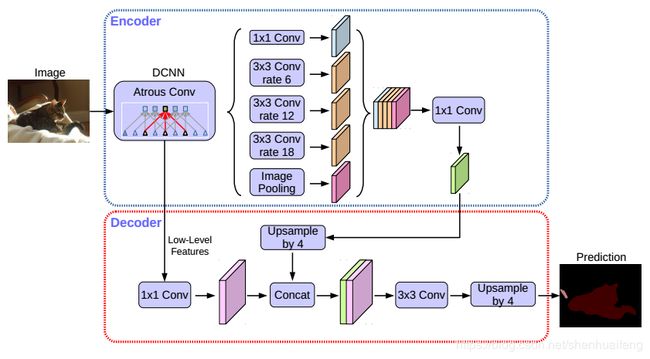
encoder输出的特征首先进行双线性4倍上采样,然后与来自网络主干的具有相同空间分辨率的低级特征连接在一起。在连接之前来自encoder低级特征首先经过卷积核大小为1x1的卷积层降低通道数。降低通道数的原因在于,低级特征图的通道数通常很多,这可能导致网络训练时偏向低级特征,从而使得网络难以训练。在连接之后,应用几个3×3的卷积来细化特征,然后进行另一个简单的双线性4倍上采样。在试验中证明,encoder输入空间分辨率与输出空间的比值为16时网络可以在速度和准去度之间取得一个比较好的平衡结果。当输入的空间分辨率与输出分辨率比为8时,网络的性能略有提升,但计算复杂度更高。 -
Modified Aligned Xception
Xception模块具有非常快的的计算速度,同时修改过的Aligned Xception在目标检测上也具有非常好的表现,因此作者基于AlignedXception结构做了一些改进并将其应用于语义分割模型。(1)深层次的Xception层与[31]相同,但因为实现快速计算和内存效率没有修改入口流网络结构。(2)所有最大池操作都被深度可分的卷积替换,这使网络能够应用一个可分离卷积来提取任意分辨率的特征图。(3)在每次3×3深度卷积后添加额外batchnormalization和ReLU激活,类似于MobileNet设计。如下图:

实验结果
略。