Elasticsearch 原理-小白入门篇
Elasticsearch 原理-小白入门篇
- 一个问题:请说出带“前”字的诗句
- 为什么我没办法立刻找出带“前”字的诗句?
- 什么是倒排索引?
- 倒排索引优化
- 实用搜索系统倒排索引基本结构
- 搜索引擎原理
- Elasticsearch 简介
- 基本概念
- 专有名词
- 实践例子
- RESTFUL API
- 索引一个文档
- 获取 / 搜索一个文档
- 文档是否存在
- 更新文档
- 创建文档
- 删除文档
- 版本控制
- 分布式原理
- ES使用领域
- 总结
一个问题:请说出带“前”字的诗句
如果是我,我的反应:想不出来
但如果是叫我背《静夜思》,我立马就能背出:床前明月光
这句诗就有前字
为什么我没办法立刻找出带“前”字的诗句?
-
因为我们人的脑袋一般是正向的索引:
key value 静夜思 床前明月光
疑是地上霜
举头望明月
低头思故乡 -
所以我们的脑内索引,没办法根据
key知道value,因为诗名不含前,当让你说出带“前”字的诗句,由于没有索引,你只能遍历脑海中所有诗词,当你的脑海中诗词量大的时候,就很难在短时间内得到结果了 -
那么到这里就很简单了,既然
key不含前,那么我们就创建这样的索引,让它包含前,于是引出倒排索引
什么是倒排索引?
- 倒排索引最简单的概念是,通过对文本分词,然后一个个词作为索引,指向文本本身,结构如下表:
| key | value |
|---|---|
| 床 | 床前明月光 |
| 前 | 床前明月光 |
| 明 | 床前明月光 |
| 月 | 床前明月光 |
| 光 | 床前明月光 |
- 这样的索引结构的确可以解决,上面的问题,但是,每一个词都要建立索引,且值完全相同,就会造成索引爆炸增长,并且一篇文章,有很多无用词:
的,而等停顿词,如果为这些停顿词也创建倒排索引,就会造成很多无用的查询,查一个的字,得到大量主题不一样的文章。
倒排索引优化
- 倒排索引可以通过压缩,去除停顿词等优化手段进行优化。
| key | value |
|---|---|
| 前 | 静夜思 望庐山瀑布 |
| 月 | 静夜思 月下独酌 |
- 上面的结构就是优化的一个简单版本,首先通过分词,将关键词提取出来,然后每个词作为索引,将对应的诗名作为值,从而构建倒排索引
实用搜索系统倒排索引基本结构
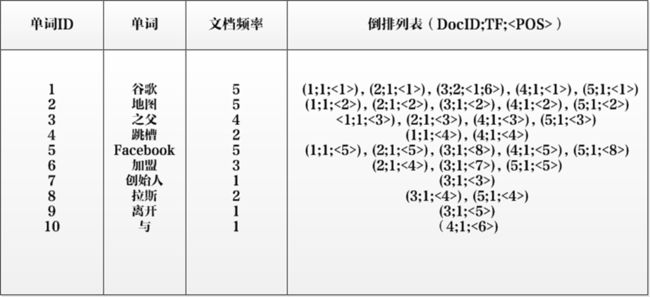
单词ID:记录每个单词的单词编号;
单词:对应的单词;
文档频率:代表文档集合中有多少个文档包含某个单词
倒排列表:包含单词ID及其他必要信息
DocId:单词出现的文档id
TF:单词在某个文档中出现的次数
POS:单词在文档中出现的位置
以单词“加盟”为例,其单词编号为6,文档频率为3,代表整个文档集合中有三个文档包含这个单词,对应的倒排列表为{(2;1;<4>),(3;1;<7>),(5;1;<5>)},含义是在文档2,3,5出现过这个单词,在每个文档的出现过1次,单词“加盟”在第一个文档的POS是4,即文档的第四个单词是“加盟”,其他的类似。
搜索引擎原理
我们平时生活中的搜索引擎就是基于倒排索引的,但是肯定比我们上面的倒排索引更复杂,一般倒排索引的构建要经历以下三个过程:
1. 爬取网页数据
2. 进行内容的分词
3. 建立倒排索引
Elasticsearch 简介
基本概念
专有名词
- 索引
- 索引不是我们通常理解的索引,不是上面所说的
key,如果要类比的话,就像是Mysql的数据库
- 索引不是我们通常理解的索引,不是上面所说的
- 类型
- 类型对应的就是
Mysql对应的表
- 类型对应的就是
- 文档
- 文档就是
Mysql中的一行记录
- 文档就是
Elasticsearch |
索引 | 类型 | 文档 |
|---|---|---|---|
mysql |
数据库 | 表 | 行 |
实践例子
比如一首诗,有诗题、作者、朝代、字数、诗内容等字段,那么首先,我们可以建立一个名叫 Poems 的索引,然后创建一个名叫 Poem 的类型,类型是通过 Mapping 来定义每个字段的类型。
比如诗题、作者、朝代都是 Keyword 类型,诗内容是 Text 类型,而字数是 Integer 类型,最后就是把数据组织成 Json 格式存放进去了。
# 索引 poems
# 类型 poem
{
"properties": {
"title": {
"type": "keyword"
},
"author": {
"type": "keyword"
},
"dynasty": {
"type": "keyword"
},
"words": {
"type": "Integer"
},
"content": {
"type": "text"
}
}
}
# 文档 doc
{
"title": "静夜思",
"author": "李白",
"dynasty": "唐",
"words": 20,
"content": "床前明月光, 疑是地上霜。 举头望明月, 低头思故乡。"
}
keyword类型不分词,直接根据字符串创建反向索引,text类型经过分词,分词后的内容在建立反向索引
RESTFUL API
索引一个文档
# 指定 doc_id,用 PUT
PUT /website/blog/123
{
"title": "My first blog entry",
"text": "Just trying this out...",
"date": "2014/01/01"
}
# 不指定 doc_id,让 es 自动生成,必须用 POST 方法
POST /website/blog/
{
"title": "My first blog entry",
"text": "Just trying this out...",
"date": "2014/01/01"
}
获取 / 搜索一个文档
GET /website/blog/123?pretty
{
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 1,
"found" : true,
"_source" : {
"title": "My first blog entry",
"text": "Just trying this out...",
"date": "2014/01/01"
}
}
# 检索文档的一部分
GET /website/blog/123?_source=title,text
{
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 1,
"exists" : true,
"_source" : {
"title": "My first blog entry" ,
"text": "Just trying this out..."
}
}
文档是否存在
curl -I -XHEAD http://localhost:9200/website/blog/123
HTTP/1.1 200 OK
Content-Type: text/plain; charset=UTF-8
Content-Length: 0
更新文档
文档在Elasticsearch中是不可变的——我们不能修改他们。如果需要更新已存在的文档,我们可以使用《索引文档》章节提到的index API 重建索引(reindex) 或者替换掉它。
PUT /website/blog/123
{
"title": "My first blog entry",
"text": "I am starting to get the hang of this...",
"date": "2014/01/02"
}
RESPONSE
{
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 2,
"created": false <1>
}
<1> created标识为false因为同索引、同类型下已经存在同ID的文档。
在响应中,我们可以看到Elasticsearch把_version增加了。
在内部,Elasticsearch已经标记旧文档为删除并添加了一个完整的新文档。旧版本文档不会立即消失,但你也不能去访问它。Elasticsearch会在你继续索引更多数据时清理被删除的文档。过程如下:
- 从旧文档中检索
JSON - 修改它
- 删除旧文档
- 索引新文档
创建文档
创建文档,可以参考上面的索引一个文档
但如何确认一个文档是创建新的,还是覆盖一个已存在的?
请记住_index、_type、_id三者唯一确定一个文档。所以要想保证文档是新加入的,最简单的方式是使用POST方法让Elasticsearch自动生成唯一_id:
POST /website/blog/
{ ... }
然而,如果想使用自定义的_id,我们必须告诉Elasticsearch应该在_index、_type、_id三者都不同时才接受请求。为了做到这点有两种方法,它们其实做的是同一件事情。你可以选择适合自己的方式:
第一种方法使用op_type查询参数:
PUT /website/blog/123?op_type=create
{ ... }
或者第二种方法是在URL后加/_create做为端点:
PUT /website/blog/123/_create
{ ... }
如果请求成功的创建了一个新文档,Elasticsearch将返回正常的元数据且响应状态码是201 Created。
另一方面,如果包含相同的_index、_type和_id的文档已经存在,Elasticsearch将返回409 Conflict响应状态码
删除文档
删除文档的语法模式与之前基本一致,只不过要使用DELETE方法:
DELETE /website/blog/123
版本控制
一天,老板决定做一个促销。瞬间,我们每秒就销售了几个商品。想象两个同时运行的web进程,两者同时处理一件商品的订单:
web_1让stock_count失效是因为web_2没有察觉到stock_count的拷贝已经过期(译者注:web_1取数据,减一后更新了stock_count。可惜在web_1更新stock_count前它就拿到了数据,这个数据已经是过期的了,当web_2再回来更新stock_count时这个数字就是错的。这样就会造成看似卖了一件东西,其实是卖了两件,这个应该属于幻读。)。结果是我们认为自己确实还有更多的商品,最终顾客会因为销售给他们没有的东西而失望。
变化越是频繁,或读取和更新间的时间越长,越容易丢失我们的更改。
在数据库中,有两种通用的方法确保在并发更新时修改不丢失:
悲观并发控制
这在关系型数据库中被广泛的使用,假设冲突的更改经常发生,为了解决冲突我们把访问区块化。典型的例子是在读一行数据前锁定这行,然后确保只有加锁的那个线程可以修改这行数据。
乐观并发控制
被Elasticsearch使用,假设冲突不经常发生,也不区块化访问,然而,如果在读写过程中数据发生了变化,更新操作将失败。这时候由程序决定在失败后如何解决冲突。实际情况中,可以重新尝试更新,刷新数据(重新读取)或者直接反馈给用户。
ES利用版本号管理并发
每个 doc的数据都会带上版本号,多个请求同时更新同一个doc,只有先到达的请求能更新成功,并将版本号加一,后续到达请求,请求的version不等于当前版本号的请求就被 REJECT 掉
使用外部系统版本号管理并发
一种常见的结构是使用一些其他的数据库做为主数据库,然后使用Elasticsearch搜索数据,这意味着所有主数据库发生变化,就要将其拷贝到Elasticsearch中。如果有多个进程负责这些数据的同步,就会遇到上面提到的并发问题。
如果主数据库有版本字段——或一些类似于timestamp等可以用于版本控制的字段——是你就可以在Elasticsearch的查询字符串后面添加version_type=external来使用这些版本号。版本号必须是整数,大于零小于9.2e+18——Java中的正的long。
外部版本号与之前说的内部版本号在处理的时候有些不同。它不再检查_version是否与请求中指定的一致,而是检查是否小于指定的版本。如果请求成功,外部版本号就会被存储到_version中。
外部版本号不仅在索引和删除请求中指定,也可以在**创建(create)**新文档中指定。
例如,创建一个包含外部版本号5的新博客,我们可以这样做:
PUT /website/blog/2?version=5&version_type=external
{
"title": "My first external blog entry",
"text": "Starting to get the hang of this..."
}
RESPONSE
{
"_index": "website",
"_type": "blog",
"_id": "2",
"_version": 5,
"created": true
}
如果你重新运行这个请求,就会返回一个像之前一样的冲突错误,因为指定的外部版本号不大于当前在Elasticsearch中的版本。
分布式原理

建立一个索引,这个索引可以拆分成多个 shard,每个 shard 存储部分数据。
拆分多个 shard 是有好处的:
-
一是支持横向扩展,比如你数据量是 3T,3 个 shard,每个 shard 就 1T 的数据,若现在数据量增加到 4T,怎么扩展,很简单,重新建一个有 4 个 shard 的索引,将数据导进去;
-
二是提高性能,数据分布在多个 shard,即多台服务器上,所有的操作,都会在多台机器上并行分布式执行,提高了吞吐量和性能。
接着就是这个 shard 的数据实际是有多个备份,就是说每个 shard 都有一个 primary shard,负责写入数据,但是还有几个 replica shard。primary shard 写入数据之后,会将数据同步到其他几个 replica shard 上去。
ES使用领域
ELK日志分析系统
- 这套
ELK如雷灌耳,我公司也正在用,舒服得很,通过将日志的内容丢给ELK,就能在几秒内返回我们需要的日志内容,哪怕日志量再多,这就是倒排索引的威力,真香~~~

APP或WEB网站内部搜索引擎
Es作为内部搜索引擎算是很常见的引用了,电商的查询商品,知识搜索引擎等等
Es 结合其他数据库(mysql,mongo,hbase)
Es作为查询,主数据库做写入和事务处理,这样构成一个业务系统,这是现在业界很经常用的一种方案。- 因为
Es查询速度很快,并且支持相关性查询等高级搜索,而mysql等关系型数据库,是很难做到反向搜索这样的操作的,所以这个方案就能兼顾Es的搜索速度,也能用到Mysql的多版本并发控制,事务等特性。 - 不过该方案很贵,因为
Es很吃内存和磁盘,索引增长速度很快,不差钱的公司可能玩得起吧。。。
总结
- 反向索引又叫倒排索引,是根据文章内容中的关键字建立索引。
- 搜索引擎原理就是建立反向索引。
Elasticsearch在Lucene的基础上进行封装,实现了分布式搜索引擎。Elasticsearch中的索引、类型和文档的概念比较重要,类似于MySQL中的数据库、表和行。Elasticsearch也是 Master-slave 架构,也实现了数据的分片和备份。Elasticsearch一个典型应用就是 ELK 日志分析系统。
引用
知乎 ES 图解
ES 权威指南中文版
advanced-java