两种常用的并发模型:CSP和Actor
概述
现如今的机器大都是多核的CPU架构,为了充分利用计算机的资源,我们要了解一些并发编程的思想。
大家应该都了解传统的并发编程模式,多线程编程。
传统的多线程编程实际上是使用的ShreadMemory的方式来推动程序的前进。
为什么说new一个thread的方式是共享内存呢?
有并发的地方就有竞争,传统多线程的并发模式使用locks(锁),condition variable(条件变量)等同步原语来强制规定了进程的推进顺序,而这些同步原语本质上都是使用了在各个线程都可见的锁来实现,有一种全局变量的味道。(少数由硬件指令直接支持的除外,例如atomic_int。
那么除了直接控制thread,使用shared memory之外我们还有什么别的并发模型吗?
答案是有的~
今天我要分享的CSP和Actor模型都是基于消息传递的。(Message Passing)
CSP
CSP的是Communicating Sequential Processes (CSP)的缩写,翻译成中文是顺序通信进程,不过这个名字比较拗口,下文将用CSP来代替。
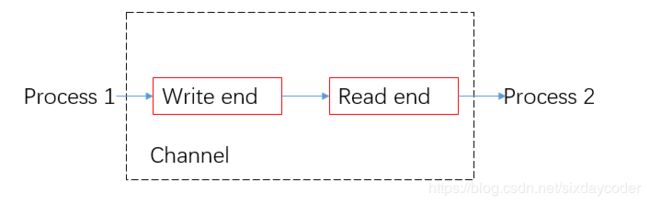
CSP的核心思想是多个线程之间通过Channel来通信(对应到golang中的chan结构),有点像是管道的概念。(Pipe)
Actor
Actor模式有一点类似面向对象模型,世界上所有的东西都被命名为Actor。
单个Actor会拥有一些状态,比如为名字是cat的Actor可能被描述为:
name : cat
age : 3
type : British shorthair
color : white
....
到此为止好像和对象object没有什么不同,但是Actor不会给外界提供任何的行为接口.
比如cat.Move()这是很自然的面向对象的写法,在Actor是不被允许的。
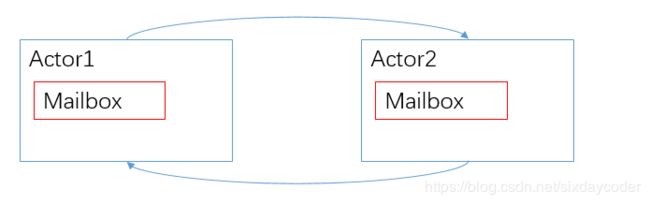
每一个Actor的属性绝不对外暴露,想和外界进行通信必须发送message,所以每个Actor自身都有一个邮箱。
无论是CSP还是Actor模型,他们都完完全全贯彻了一句至理名言:
Don't communicate by sharing memory; share memory by communicating. (R. Pike)
CSP :Goroutine
golang中的goroutine我们可以理解为是一个thread,但是它非常精简,调度的开销也非常小。
goroutine之间的通信使用名为chan的数据结构,对应CSP模型中的channel。
goroutine的使用很简单,仅需要关键词go即可启动一个goroutine,不同的goroutine之间使用channel进行通讯,这都是很基本的用法,就不背语法书了。
关于goroutine,还是想多聊一聊golang是如何调度goroutine的。
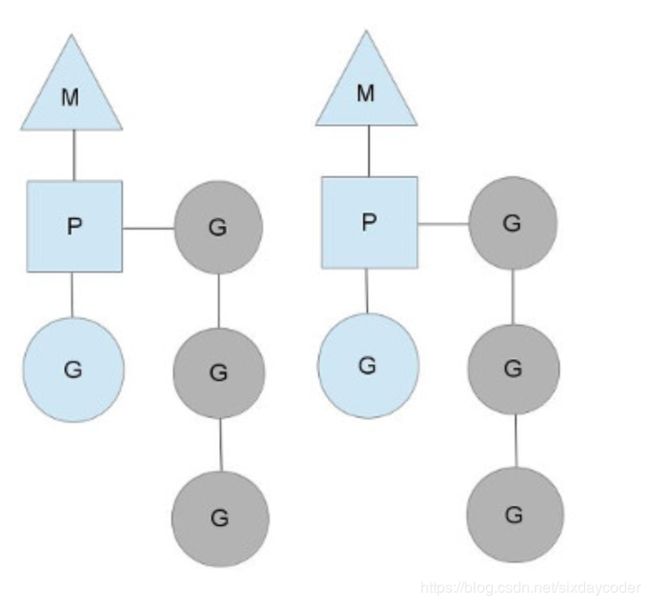
Go的调度器内部有三个重要的结构:M,P,S。
M:代表真正的内核OS线程,真正干活的人
G:代表一个goroutine,它有自己的栈,指令集信息(要执行的指令)和其他信息(正在等待的channel等等),调度的单位。
P:代表调度的上下文,可以把它看做一个局部的调度器,使go代码在某个M上跑

当go运行起来的时候,大致是下图的样子:
简单解释一下:
图中的两个M表示当前go运行的机器上有两个线程可以让我们使用。
P是goland的调度上下文,它必须运行在某个M上,实际上就类似:
new Thread(P.run())
P上挂着好几个goroutine :
蓝色的G表示当前P正在调度的goroutine,此时相当于把蓝色的G扔到了M上。
灰色的G表示正在等待P调度的goroutine,轮到他们的时候就会被扔到M上。(如何公平的调度灰色的G?)
目前来看,P好像是多余的,我直接想办法把G扔到M上就好了,为何还要有一个P这样的中间层的。
当然P很有必要,如果某个线程M被阻塞了,那么P可以被扔到其他的线程上,去合理的调度它挂着的G。
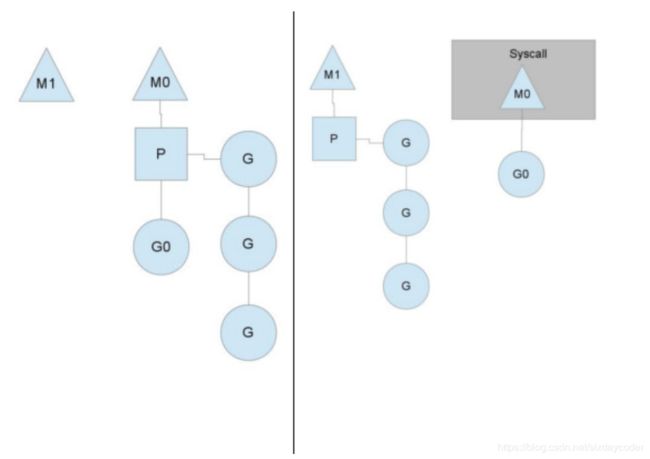
这个图表示的就是M0被阻塞了,转而把P挂到了M1上。
可以看到M0此时有一个G0在运行,这是啥意思…
我们在具体一点吧:
G0
n = read(fd, buf, size)
print(n)
G0之前在P上挂着,开心的在M0上运行(蓝色的G0),此时G0调用了系统调用read,显然G0被阻塞了。
golang为了充分利用cpu资源,不让那些被排队的goroutine浪费时间,P挂到了M1上。
那么问题来了,如果read完了,系统调用结束,那么该打印n了,可是这时候没有P了,怎么办?
golang会维护一个全局队列,把G0放到一个全局队列了,然后M0就去sleep了。
所有的P会周期性的检查全局队列里的G,否则这些G就都饿死了。
由此可见,P是很有必要的。
还有很神奇的一点,P可以“偷“任务。
考虑一种情况:
P1身上的G不巧都是和网络IO有关,运行的非常缓慢。
P2身上的G都是一些比较快的运算函数,他很快就完成了,那么他就会尝试从P1那里偷一些G来运行。
channel的结构
type hchan struct {
qcount uint // 缓存当前包含数据个数
dataqsiz uint // 缓存容量
buf unsafe.Pointer // 缓存指针,缓存是一个循环数组,数据大小为dataqsiz
elemsize uint16 //
closed uint32 // channel开关状态
elemtype *_type // 数据类型
sendx uint // send index
recvx uint // receive index
recvq waitq // list of recv waiters(阻塞的接受goroutine队列)
sendq waitq // list of send waiters(阻塞的发送goroutine队列)
lock mutex
}
// 阻塞goroutine队列
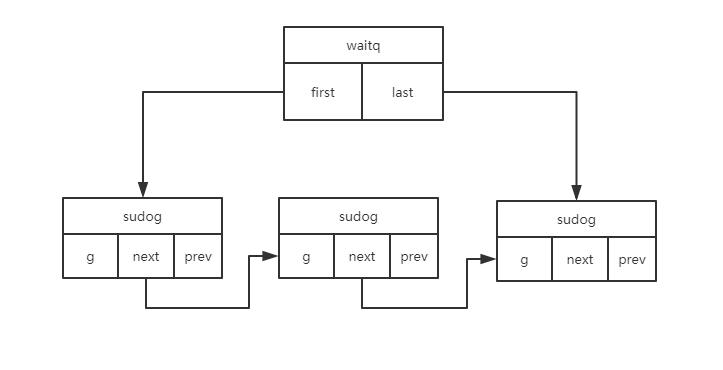
type waitq struct {
first *sudog
last *sudog
}
// goroutine的封装(公用数据结构)
type sudog struct {
g *g
selectdone *uint32 // CAS to 1 to win select race (may point to stack)
next *sudog
prev *sudog
elem unsafe.Pointer // 发送goroutine为发送变量地址,接收goroutine反之
......
}
这里可能有点抽象,上一个图更直观一点:
ch := make(chan int , 10 ) ,对应的runtime中的实现是:
func makechan(t *chantype, size int64) *hchan
该函数的主要作用就是从堆上分配内存,当然和c的malloc的有些不同,可以大略看一下:
var c *hchan
switch {
case size == 0 || elem.size == 0:
// Queue or element size is zero.
c = (*hchan)(mallocgc(hchanSize, nil, true))
// Race detector uses this location for synchronization.
c.buf = unsafe.Pointer(c)
}
注意使用的是mallocgc,go会在合适的时候gc掉这块内存
channel的读写
var val int = 666
ch := make(chan int , 10)
ch <- val
这是我们在go中向channel写入数据的结构的方法,对应到:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool
参数c就是实际对应的chan
参数ep是变量val的地址
0.各种参数的有效性的校验
1.获取channel上的锁,如果是已经关闭的channel,会释放锁否则继续逻辑:
lock(&c.lock)
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
2.获取channel的recv队列,dequeue出的sg就是上文中的sudog,向等待的这个channel的goroutine会发送刚才的val(在这里就是ep)
if sg := c.recvq.dequeue(); sg != nil {
// Found a waiting receiver. We pass the value we want to send
// directly to the receiver, bypassing the channel buffer (if any).
send(c, sg, ep, func() { unlock(&c.lock) }, 3) // 发送val给sg(goroutine),sg在等待c
return true
}
- 如果没有等待该channel的goroutine,看一下channel的剩余缓存是不是够大,如果可以,把数据放进去
if c.qcount < c.dataqsiz { //缓存中的数据个数 < 缓存的容量
// Space is available in the channel buffer. Enqueue the element to send.
qp := chanbuf(c, c.sendx)
if raceenabled {
raceacquire(qp)
racerelease(qp)
}
typedmemmove(c.elemtype, qp, ep)//把数据放进去
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
unlock(&c.lock)
return true
}
4.缓存不够大,channel没有办法在塞数据了, 自身会因此阻塞,此时调度器会执行别的goroutine
在让出线程之前,会new一个goroutine出来,把多的数据放到这个goroutine上,加入到等待队列。
// Block on the channel. Some receiver will complete our operation for us.
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
打包数据,发送等待队列
mysg.elem = ep
mysg.waitlink = nil
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.waiting = mysg
gp.param = nil
c.sendq.enqueue(mysg) //把goroutine加入到sendq
goparkunlock(&c.lock, "chan send", traceEvGoBlockSend, 3)
这样可能太抽象了,我们举个最简单的生产者消费者例子:
//生产者
func main(){
//1.
ch := make(chan Data, 4)
//2.
for _, task := range {
ch <- task
}
//3.
for i := 0; i< 10; i++ {
go consumer(ch)
}
}
// 消费者
func consumer(ch chan Data){
for {
//收取任务并处理
data := <- ch
process(data)
}
}
main的goroutine是生产者,以G1代替
consuemr的goroutine是消费者,以G2代替
1.初始化chan数据,创建hchan结构体。
hchan.buf指向一个大小为4的数组,并且hchan.sendx、hchan.recvx置0,hchan.dataqsiz置4。
2.发送数据
G1向channel发送数据,把要发送的数据拷贝到buf里,hchan.sendx++。(该过程需要加锁)
3.接受数据
G2从channel接受数据,将接受的数据拷贝到buf里,hchan.recvx++。(该过程需要加锁)
4.特殊情况
G1向chan发数据,chan的buf满了,会怎么样?
此时,runtime把G1和要发的数据打包成sudog,状态设置为等待,加到chan的sendq阻塞队列中,然后执行goparkunlock()把当前线程让出。
G2从chan中取出一条数据的时候,chan的buf有空了,然后从chan的sendq取出G1来执行。
Actor
Actor模型在web后端应用的不是很广泛,只有一些比较小众的语言天然支持这种编程范式(erlang),但是在游戏后端算是非常常用的编程范式。
Actor模型写起来比较舒服,因为你无需担心多线程的问题,只要是Actor自身的状态是不会被外界直接改变,都是通过handlemsg的方式来改变。
大部分语言都不原生支持Actor模型,这里以C系的语言为例,给大家分享如何来实现Actor模型。
0.ActorBase -> Actor的基类
每一个线程中有一个Actor,充分利用CPU资源。
ActorBase
{
id -> Actor的Id,用于区分不同的Actor
status -> Actor的状态
properties -> Actor的各种属性
mailbox -> Actor的邮箱 (线程安全)
recvmsg(msg) -> 接受消息的接口
run()
{
while(msg = get_from_mailbox())
{
handlemsg(msg)
}
}
}
1.GlobalActorController -> 全局的Actor调度器
GlobalActorController
{
list actor_list -> 全部actor的容器
threadpool -> 根据某种调度策略,遍历actors,调用actor.run()
sendmsg(send_actor_id, recv_actor_id, msg) -> 发送消息
broadcastmsg(send_actor_id, recv_actor_id_list, msg) -> 广播消息
}
这个代码部分可能有些抽象,让我们举个例子:
游戏中常见的商城功能,我们定义一个
ShopMallActor : extend from ActorBase
商城Actor管理了所有在商城中出售的商品,它维护一个出售的物品的list
list shop_item_list
然后所有的玩家都在某个具体的场景中,我们定义一个
SceneActor : extend from ActorBase
场景Actor管理了所有在这个场景中的玩家,它维护一个玩家的list
list player_in_scene_list;
显然商城actor和场景actor没有任何关系,把他们看做是两个不同的actor添加到我们的GlobalActorController的actor_list中,扔到线程池中。
那么如果玩家想从商城里买东西应该是怎样的呢:
1.player.sendmsg(ShopActorId, buy_msg)
2.场景actor就会把这个buy_msg交付给GlobalActorController, 调用sendmsg(SceneActorId, ShopActorId, buy_msg)转发给ShopMallActor
3.商城Actor在自己的run方法里取出msg,发现了buy_msg,去handle(buy_msg), 在条件检测完毕后,发回msg给SceneActor
SceneActor通过某种策略找到到底哪个玩家发送的这个buy_msg(比如发buy_msg的时候在msg中带着player的uid),将物品发还给玩家