VRRP协议详解
1.产生背景及应用环境
1.1为什么要用VRRP
VRRP(Virtual Router Redundancy Protocol)------虚拟路由器冗余协议,其最新技术标准是RFC3768。
为什么要用VRRP呢,主要是为了实现数据链路层互通设备的冗余备份功能,我们来看图一:
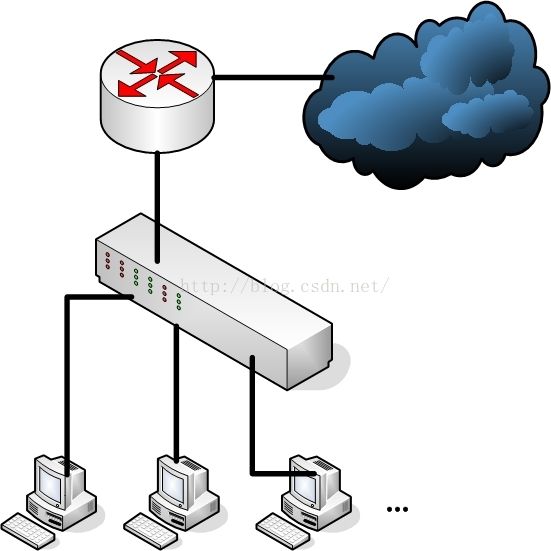
图一(常规网络架构)
通过上图可以看到,常规的局域网一般都是多个终端接到交换机上,然后通过单独的出口路由器连接到Internet,这时候问题来了,如果这个出口路由器坏掉了,那么整个上行的流量就会全部断掉,这就是传说中的单点故障。
所以说我们要避免出现这种情况,本着冗余备份的思想,我们对上面的网络进行物理改造,如下图:

图二(消除了单点故障的常规网络架构)
现在,这个网络一共有两个Internet出口,这样任何一个出口路由器出现故障都不会导致终端用户的上行流量断掉。
另外一个问题出现了,我们怎么让终端PC知道局域网中有两个出口路由器,并在其中一个出现故障后自动选择另外一个呢?可采用的方案包括让终端PC运行动态路由协议,比如RIP、OSPF,或者ICMP router Discovery client(DISC),或者指定一条静态缺省路由。
但是这三种实现方法都有其劣势及不可行之处,我们来具体分析一下。首先对于在每一个终端PC上运行动态路由协议来讲,几乎是不可能的,这其中牵涉到网管的技术能力和日常维护、安全性问题、以及某些终端平台不支持动态路由协议,比如我们常用的XP、Windows7都不支持,而windows Server系列OS支持。
假定我们在终端PC上部署了动态路由协议,那么每一个终端用户都会遇到下面这种情况:
10086:尊敬的用户您好,申报RIP故障请按1,申报OSPF故障请按2,申报ISIS故障请按3……….
用户:( ⊙ o ⊙ )啊!我家是OSPF,按2。
10086:您好,您申报的故障是OSPF,请进一步选择,OSPF邻居无法建立请按1,OSPF密钥不对请按2,链路状态数据库异常请按3,路由表错误请按4…………..
用户:( ⊙ o ⊙ )啊!……………然后吐血身亡………….
所以说,N多现实问题和困难导致在终端PC上部署动态路由协议具有不可行性。
那么对于在终端PC上部署DISC等邻居或路由器发现协议呢?也存在种种问题,例如在网络内存在大量主机,每一台都需要运行DISC,除了增加主机的处理负担外,也会导致协议收敛缓慢,从而不能及时发现不可用邻居路由器,产生路由黑洞,这是不可接受的。
现在只剩下在终端PC上配置静态缺省路由了(其具体表现形式一般是设置网关),这是几乎每一个IP平台都支持的配置功能,即使是一部IP电话机,根据这个思路,我们在终端上配置多个默认网关即可实现路由备份了,但是存在以下两个问题:
1. 对于下行设备是PC来讲,配置了多个默认网关之后,其中一个会作为活动默认
网关,其它的作为备份默认网关,其按照下列过程执行流量转发和失效网关检测:
当TCP/IP在通过活动默认网关向某个目标IP地址进行TCP通信时,如果失败的尝试次数达到TcpMaxDataRetransmissions注册表值(默认为5)的一半(即3次)还没有收到响应,TCP/IP将到达该目标IP地址的通信改为使用列表中的下一默认网关,这一步是通过更改该远程IP地址的路由缓存项(Route Cache Entry,RCE)来实现的,从而使用列表中的下一个默认网关来作为下一跳地址。其中RCE是路由表中的一个条目,用于存储目的地的下一跳IP地址。当超过25%的TCP连接转向下一默认网关时,TCP/IP将活动默认网关修改为这些连接当前使用的默认网关。
如果此时原始默认网关从故障中回复,TCP/IP将继续使用当前的活动默认网关,而不会转移到原始默认网关,除非重启计算机。如果当前的活动默认网关也出现故障,那么TCP/IP就会继续尝试使用列表中的下一个默认网关,在尝试完整个列表后将返回到列表的开始,又从第一个默认网关开始进行尝试。
死网关检测仅监视TCP流量,如果其他类型的流量连接失败,不会切换默认网关。另外TCP是端到端的协议,因此即使当前默认网关完全正常,本地计算机的TCP通信失败也可能会导致切换默认网关。
当不同网络接口所连接的网络之间没有连接性时(如一个网络接口连接到Internet,而一个网络接口连接到内部网络),如果在多个网络接口上同时配置默认网关,在活动默认网关出现故障导致切换默认网关时,就可能会引起连接性故障。比如活动默认网关为Internet连接,当它出现问题时,此时默认网关切换为内部连接,此时,本地计算机将无法再访问位于Internet连接上的主机。对于这种情况,微软建议使用 route add 来添加对应目的网络的匹配路由,而不是设置多个默认网关,这其实就是最长匹配原则,精确路由优先于缺省路由。
2.对于下行设备是路由器的情况,其不会切换默认路由,只会按照配置好的缺省
路由优先级进行流量转发,从而导致路由黑洞。
结合上面两个原因,在网络出口路由器的下行设备上配置缺省路由的方法也不可行。
综上所述,要想消除单点故障,又同时实现下行设备在故障发生时的流量无障碍
转发,以上的三个方法均不可行,所以人们开发出了一种全新的协议:VRRP,这
种协议无需下行设备与出口路由器进行交互性操作,却完全实现了网络出口的冗
余备份,下一节,我们就来详细讨论下VRRP的基本原理及实现过程。
2.VRRP基本原理及实现过程
2.1基本概念
VRRP路由器:运行VRRP协议一个或多个实例的路由器
虚拟路由器:由一个Master路由器和多个Backup路由器组成。其中,无论Master路由器还是Backup路由器都是一台VRRP路由器,下行设备将虚拟路由器当做默认网关。
VRID:虚拟路由器标识,在同一个VRRP组内的路由器必须有相同的VRID,其实VRID就相当于一个公司的名称,每个员工介绍自己时都要包含公司名称,表明自己是公司的一员,同样的道理,VRID表明了这个路由器属于这个VRRP组。
Master路由器:虚拟路由器中承担流量转发任务的路由器
Backup路由器:当一个虚拟路由器中的Master路由器出现故障时,能够代替Master路由器工作的路由器
虚拟IP地址:虚拟路由器的IP地址,一个虚拟路由器可以拥有一个或多个虚拟IP地址。
IP地址拥有者:接口IP和虚拟路由器IP地址相同的路由器就叫做IP地址拥有者。
主IP地址:从物理接口设置的IP地址中选择,一个选择规则是总是选用第一个IP地址,VRRP通告报文总是用主IP地址作为该报文IP包头的源IP。
虚拟MAC地址:组成方式是00-00-5E-00-01-{VRID},前三个字节00-00-5E是IANA组织分配的,接下来的两个字节00-01是为VRRP协议指定的,最后的VRID是虚拟路由器标识,取值范围[1,255]
2.2报文组成
下面我们来看VRRP报文的具体组成:

图三(VRRP报文格式,取自RFC3768)
具体字段含义:
Version:VRRP协议版本号,RFC3768定义了版本2.
Type:该字段指明了VRRP报文的类型,RFC3768只定义了一种VRRP报文,那就是
VRRP通告报文,所以该字段总是置为1,若收到的VRRP通告报文拥有非1的类型
值,那么会被丢弃。
Virtual Rtr ID:也就是我们上面介绍过的VRID,一个VRID唯一地标识了一个虚拟
路由器,取值范围是[1,255],所以一台路由器的接口可以同时运行最多255个VRRP
实例,此字段没有缺省值,必须人为设定。
Priority:优先级,在一个虚拟路由器中用来选取Master路由器和Backup路由器,值越大表明优先级越高,此字段共有8个bit,取值范围[1,254],若没有人为指定,缺省值是100。其中,VRRP协议会将IP地址拥有者路由器的该字段永远设置为255,若人为指定为其它值,也不会影响VRRP协议的默认行为,即IP地址拥有者路由器的该字段总是255。另外,此字段设置为0会出现在下面这种情形中,当Master路由器出现故障后,它会立刻发送一个Priority置0的VRRP通告报文,当Backup路由器收到此通告报文后,会等待Skew time时间,然后将自己切换为Master路由器,其中Skew time=(256-Backup路由器的优先级)/256,单位为秒,例如若Backup路由器的优先级为100,那么Skew time=156/256=0.609秒,对于主路由器来说,Skew time并没有实际意义,虽然cisco的路由器也会计算并显示出来。
Count IP Addrs:VRRP通告报文中包含的IP地址数量,这个字段其实就是为一个VRRP虚拟路由器所分配的IP地址的数量,我们来看一个cisco的实际例子:
配置如下:
interface Ethernet1/0
ip address 192.168.10.102 255.255.255.0
duplex half
vrrp 1 ip 192.168.10.52
vrrp 1 ip 192.168.10.51 secondary
vrrp 1 ip 192.168.10.53 secondary
end
我们来看一下上面的配置在封装成VRRP通告报文的时候,是如何进行的,如下
图:

图四(VRRP报文的抓包分析)
大家可以看到,VRRP通告报文中的Count IP Addrs字段的值为3,这是因为我们配置了3个虚拟IP地址,另外,下面的IP Address字段也按照我们配置虚拟IP的顺序进行了封装。
Auth Type:认证类型字段,是一个8位的无符号整数,一个虚拟路由器只能使用一种认证类型,如果Backup路由器收到的通告报文中认证类型字段是未知的或和本地配置的不匹配,那么它将丢弃该数据包。
值得注意的是,在RFC2338中为VRRP定义了3种认证类型:无认证、明文认证、MD5认证,但是在后续的实践中发现,这些手段无法提供行之有效的安全性,并且还会导致多个Master路由器的问题,所以在最新的VRRP标准:RFC3768中已经去掉了所有的认证类型。
目前认证类型字段的定义如下:
0 – 无认证,此时下面的Authentication Data字段将会被置为全0,接收到的路由器也会忽略此字段。
1 – 保留,是为了向前一个版本的RFC2338提供兼容性
2 – 保留,是为了向前一个版本的RFC2338提供兼容性
Adver Int::此字段规定了Mater路由器向外发送VRRP通告报文的时间间隔,以秒为单位,取值范围是[1,255],若没有人工配置,缺省为1秒。
Checksum:整个VRRP报文的校验和,计算过程中,将Checksum字段置为0,计算完成后将结果填入此字段。若希望进一步了解Checksum的计算,可以查看RFC1071(CKSM)。
IP Address:此字段存放3个VRRP虚拟路由器的虚拟IP地址,配置了几个就封装几个,在上面的cisco实例中我们配置了三个,那么VRRP通告报文就会封装3个。
Authentication Data:RFC3768中规定,此字段只是为了向RFC2338兼容,在实际的封装时,全置为0.,接收方也会忽略此字段。
2.3协议状态机
对一个VRRP虚拟路由器来讲,,参与它的每一台VRRP路由器,都只有3种VRRP状态:Initialize,Master,Backup,在讲述这三种状态时会碰到一些新的概念,我们会在第一次遇到时做详细解释。
2.3.1初始状态(Initialize)
这是配置好VRRP后,VRRP等待一个开始事件时的状态,当本地VRRP进程切换到此状态后,会依次执行下列操作:
2.3.1.1如果本地优先级为255,也就是说自己是IP拥有者路由器,那么接下来它会:
1.发送VRRP通告报文
2.广播免费ARP请求报文,内部封装是虚拟MAC和虚拟IP的对应,有几个虚拟IP地址,那么就发送几个免费ARP请求报文。
3.启动一个Adver_Timer计时器,初始值为Advertisement_Interval(缺省是1秒),当该计时器超时后,会发送下一个VRRP通告报文
4.本地VRRP进程将自己切换为Master路由器
2.3.1.2如果,本地优先级不是255,,那么接下来它会:
1.设置Master_Down_Timer计时器等于Master_Down_Interval,也就是主路由器死亡时
间间隔,如果此计时器超时,那么Backup路由器就会宣布主路由器死亡。
其中Master_Down_Interval =(3*Advertisement_Interval)+ Skew_time举例来说,一个VRRP实例(也就是一个VRRP虚拟器)的优先级是100,报文发送
间隔是1秒,那么Master_Down_Interval = 3*1s +(256-100)/256s = 3.609秒。
2.本地VRRP进程将自己切换为Backup路由器
2.3.2备份路由器状态(Backup)
2.3.2.1
备份路由器是为了监控Master路由器的状态,如果一个VRRP路由器处于此状态,那么它会:
1. 不响应对虚拟IP地址的ARP请求报文
2. 丢弃帧头目的MAC地址是虚拟MAC的帧
3. 丢弃IP头中目的IP地址是虚拟IP的IP包
2.3.2.2
如果此时该VRRP路由器收到了一个shutdown事件,那么它会:
1. 取消Master_Down_Timer
2. 转换为初始状态(Initialize state)
2.3.2.3
如果Master_Down_Timer超时,那么该VRRP路由器会执行:
1.发送一个VRRP通告报文,
2.广播免费ARP请求报文,内部封装是虚拟MAC和虚拟IP的对应,有几个虚拟IP
地址,那么就发送几个免费ARP请求报文。
3.设置Adver_Timer计时器为Advertisement_Interval(缺省为1秒)
4.切换到Master状态
2.3.2.4
如果该Backup状态的VRRP路由器收到了一个VRRP通告报文;
当该VRRP通告报文的优先级字段为0时,那么路由器会将当前的
Master_Down_Timer 设置为Skew_Time;
如果优先级不为0,并且大于或等于本地优先级,那么本地路由器会重置Master_Down_Timer计时器并保持Backup状态;
如果优先级不为0,并且小于本地优先级,如果开启了抢占模式(Preempt mode),
那么该Backup路由器等待指定的抢占延迟时间后将自己切换为Master路由器;并执
行Master路由器的所有动作;例如:vrrp 1 preempt delay minimum 10,表示等待10秒
后切换自己为Master;
如果优先级不为0,并且小于本地优先级,如果没有开启抢占模式(Preemptmode),那么本地路由器保持Backup状态。
2.3.3 Master路由器(Master state)
处于Master状态的路由器会执行目的MAC为虚拟MAC数据帧的转发,这里要清楚的是对于下行设备的arp表里,该虚拟MAC是和虚拟IP地址相对应的。
2.3.3.1
当路由器处于Master状态时,会进行下面的动作:
1. 响应对虚拟IP地址的ARP请求
2. 转发目的MAC地址是虚拟MAC的数据帧
3. 拒绝目的IP地址是虚拟IP的数据包,除非它是IP地址拥有者(也就是优先级是
255的那个路由器)。
2.3.3.2
如果处于Master状态的VRRP进程收到了一个shutdown事件,那么它会:
1. 取消Adver_Timer计时器
2. 发送一个优先级字段置零的VRRP通告报文
3. 切换为初始状态(Intialize state)
2.3.3.3
如果Adver_Timer计时器超时,那么:
1. 发送一个VRRP通告报文
2. 重置Adver_Timer计时器
2.3.3.4
如果收到了一个VRRP报文且其优先级为0,那么:
1. 发送一个VRRP通告报文
2. 重置Adver_Timer计时器
2.3.3.5
如果收到了一个VRRP报文且其优先级高于本地优先级,或者收到的VRRP报文优先级等于本地优先级但是主IP地址高于本地的主IP地址,那么:
1. 取消Adver_Timer计时器
2. 设置Master_Down_Timer计时器为Master_Down_Interval
3. 切换为Backup状态
2.4 VRRP通告报文的发送与接收处理流程
2.4.1当收到一个VRRP通告报文时,执行以下操作:
1. 检查IP包头的TTL是否为255
2. 检查VRRP报文的version字段是否为2
3. 检查VRRP报文的完整性,即是否包含RFC所定义的各字段
4. 检查checksum字段
5. 检查VRID字段是否和本地配置的VRID一致
6. 确保本地路由器不是IP地址拥有者,即优先级不是255(如果自己是IP地址拥有者,那么自己永远都是Master路由器,所以丢弃任何收到的VRRP通告报文)
7. 检查认证类型和认证数据字段,确保和本地一致
如果上面的七项检查有一项不通过,那么就会丢弃该报文,如果配置了网管程序,就会自动记录log并报告错误。
如果以上检查通过,那么可能会检查VRRP通告报文中的Count IP Addrs字段和IP地址字段,确保核本地一致,如果检查结果不一致并且该报文不是由IP地址拥有者产生的,那么丢弃该报文。注意:这里用了可能,所以各厂家在实现VRRP时,可能会检查也可能不会检查该字段,Cisco就不会检查。
如果以上检查均通过,那么接下来会查看Advertisement_Interval是否和本地一致,若不一致,会丢弃该报文。如果配置了网管程序,就会自动记录log并报告错误。
2.4.2 发送一个VRRP报文的时候,需要执行下列动作:
1.将当前手动或默认的VRRP配置封装进报文的相关字段
2.计算VRRP校验和,将结果放入checksum字段
3.设置帧的源MAC地址为虚拟MAC地址(这样就确保了下联交换机可以建立正确的MAC表,即实际端口和虚拟MAC的对应关系,这个对应关系会因为Master路由器的切换而发生变化,所以这个处理对于上行数据帧的正确转发至关重要)
4.设置IP包头的源IP地址为该物理接口的主IP地址
5.设置IP头中的protocol字段为0x70,也就是十进制的112,表示上层封住协议是VRRP
6.将封装好的VRRP通告报文发送出去,目标IP为组播地址224.0.0.18,目的MAC地址为组播MAC:01:00:5e:00:00:12
好了,以上就是关于VRRP全部的协议实现细节,下面我们来看一下VRRP的应用需求。
3.VRRP的两种应用需求:
3.1我们来看一个具体冗余备份的图例:

图五(VRRP为下行设备提供冗余备份功能)
上图的实例中我们定义了一个虚拟路由器,标识为1(即VRID=1);其虚拟IP设置为IP A,是Router1的接口IP,所以Router1就是一个IP地址拥有者,系统会将其优先级设置为255,并作为VRID1的Master路由器,而Router2的优先级默认为100,Router2的VRRP实例VRID1将自己设置为Backup路由器;下行的各主机将网关设置为VRID1虚拟路由器的虚拟IP,即IP A。
通过以上设置,即可消除出口路由器的单点故障,假如此时Router1挂掉,那么Router2的VRRP进程经过 Master_Down_Interval = (3*Advertisement_Interval)+ Skew_time,时间之后,就会宣布Master挂掉,将自己设置为Master路由器,并广播免费ARP请求报文,这样下行交换机就能更新虚拟MAC到与Router2接口的对应表项,从而实现不间断转发用户的流量。
但是,实际情况中我们很少这么设置VRRP,因为始终是一台路由器在承担所有流量,不符合物尽其用的原则。
3.2我们来看一个冗余备份和负担均衡相结合的图例:

图六(VRRP同时实现冗余备份和负载均衡)
上图中的VRID1的设置和图五一样;VRID2的设置将Router2作为Master路由器,Router1作为Backup路由器,然后将一半下行主机的网关设置为VRID1的虚拟IP,即IP A,将另一半主机的网关设置为VRID2的虚拟IP,即IP B。
这样,在两台设备都正常运行的情况下,终端流量一半走Router1,一半走Router2,实现了负载均衡;而当其中一台路由器挂掉时,依靠VRRP的功能,会将另一台路由器设置为Master路由器,继续流量转发,从而实现了冗余备份功能,此时,这台路由器会同时作为VRID1和VRID2的Master路由器。
4.实例研究
实际组网中,绝大多数情况都是双交换机或双路由器上行,所以图六的VRRP实现具有普遍意义,下面,我们就来看看VRRP在各厂家设备上的配置实现(都以图六作为试验拓扑):
4.1在Cisco路由器上的实现
下面两图是Router1和Router2的VRRP配置及状态:
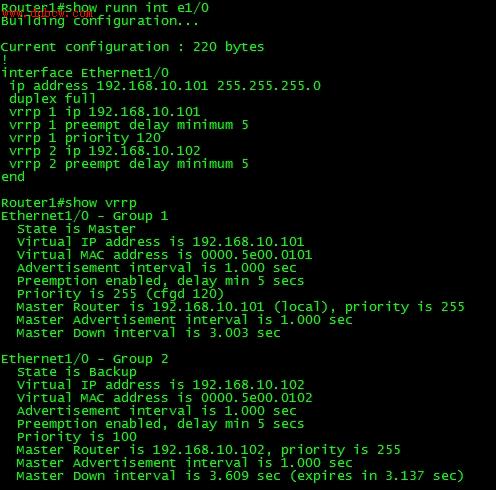

通过VRRP的运行状态,我们可以知道:
1. 即使为IP地址拥有者配置了优先级,系统也会使用255
2. 若不指定优先级,系统缺省认为是100.
3. 缺省通告时间是1秒
4.2在Redback路由器上的实现
下面就是两个VRRP实例在Redback路由器上的配置:
context vrrp
interface downlink
ip address 192.168.10.201/24
vrrp 1 owner-----------------------这表明这个VRRP实例的IP是路由器的接口IP
virtual-address 192.168.10.201—必须是真实interface的IP,否则系统报错
advertise-interval millisecond 100----VRRP通告报文的发送间隔,这里为100毫秒
authentication redback-md5 vrrp-auth—采用MD5方式认证
vrrp 2 backup---------------------这表明这个VRRP实例的IP地址一定不是interface接口
的IP,但是和interface接口IP一定在同一个网段内。
virtual-address 192.168.10.202
advertise-interval millisecond 100-----VRRP通告报文的发送间隔,这里为100毫秒
priority 120----------------------------本地VRRP优先级为120
init-wait 1------------------------------VRRP实例2启动后,等待接收VRRP通告报文的时间
track interface uplink vrrp decrement 100---VRRP实例监控上行链路的状态,若为down,则将本地VRRP优先级降低100
authentication simple vrrp-authentication----VRRP实例2采用明文认证
!
interface uplink----------------------上行端口,连接骨干网
ip address 10.1.1.1/30
!
key-chain vrrp-auth key-id 1----------VRRP1采用MD5方式认证
key-string encrypted DC2C32F335F4113A949FEF2997659B974A70687575316125
!
下面我们来看看两个VRRP实例的状态:
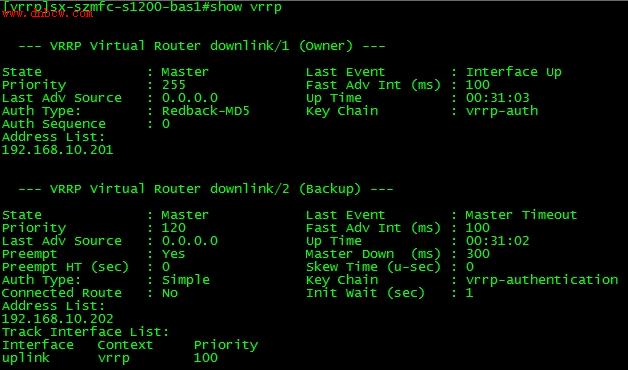
Redback路由器上VRRP实现特性:
1. 将VRRP的owner角色与backup角色从配置层次上区分开,这样做的好处就是非常清晰。而其他厂家没有关键字来区分这两种角色,只是依靠virtual-address是否和本地接口IP地址相同来判断本地VRRP实例是owner角色还是backup角色。
2. 若配置VRRP实例为owner角色,那么virtual-address必须是interface的IP地址,否则系统报错,并且此时不能配置priority,因为系统为owner角色永远分配255的优先级;反之若配置VRRP实例为backup角色,那么virtual-address绝对不能是interface的IP地址,否则系统报错,并且此时不能配置priority为255,因为255是系统为owner保留的优先级。
3. 只有backup状态的VRRP实例才能够配置preempt,因为master无需抢占。
4. Track:这是个非常有用的特性,它是用来快速检测上行链路的连通性并作出反应的命令。我们来假设这样一种情况,此时本地路由器作为VRRP实例2的master角色,假如路由器的上行接口uplink挂掉了,那么本地的所有上行流量都将被丢弃,对下行设备来讲形成了路由黑洞,这是不可接受的。所以,依靠这个track特性来监控指定链路,当检测到指定链路down掉后,立刻将本地VRRP实例的优先级降低100.,从而让其他路由器抢占master角色。
我们把uplink认为down掉,来看看路由器的反应:
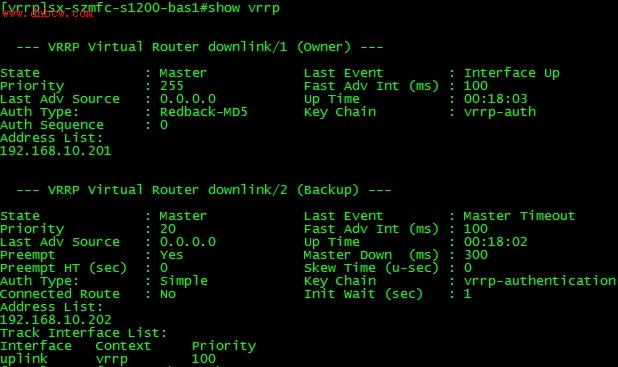
大家应该可以看到,当VRRP实例2,检测到uplink不通之后,将VRRP2的优先级降低100,120-100=20,所以我们在上图中看到VRRP2的优先级为20。
5.对show vrrp的显示结果做一下简单说明,Last Adv Source是指VRRP通告报文的发送者的IP,所以此处总是置为0,并且VRRP报文中也不包含此字段,只不过是Redback方便网管的一个处理方式。
6. Last Event:是指VRRP导致发生状态转化的事件,可能是配置了虚拟地址、端口UP,主路由器超时,被别人抢占了Master角色等等,可以作为网管的一个辅助判断手段。
4.2在Juniper路由器上的实现
Juniper路由器上VRRP的实现和cisco差不多,下面来看看具体配置:
mm# show interfaces ge-0/0/0 ----------在当前接口的unit10子接口上起了两个VRRP实例
unit 10 {
family inet {
address 192.168.10.201/24 {-----------------------物理接口IP地址
vrrp-group 1 {----------------------------------VRID = 1
virtual-address 192.168.10.201;--------虚拟IP地址为物理接口IP
priority 120;-------------------------------虽然配置了120,但是系统会改为255
fast-interval 100;--------------------------快速发布VRRP通告报文
preempt {
hold-time 0;----------- ----实时抢占,因为这里是owner,所以无意义
}
accept-data;----------------接受目的IP是虚拟IP的报文
track {------------------------监测上行端口
interface em1.0 {
bandwidth-threshold 100m priority-cost 100;--监测上行端口带宽
}
interface em2.0 {----------------监测上行端口UP、down状态
priority-cost 100;
}
}当监测到em1的带宽不满100M或em2挂掉后,将本地优先级降低100
}
vrrp-group 2 {
virtual-address 192.168.10.202;
priority 100;
fast-interval 100;
preempt {
hold-time 0;-------------------当发现Master挂掉后,执行实时抢占,而不是等待Master-down-interval
}
}
}
}
}
看一下VRRP运行状态:

5.VRRP的安全性
当前各厂家对VRRP的实现主要是依据RFC2338,采用sample、MD5、无认证,这三种方式,但最新的RFC3768已经取消了所有安全选项,这主要是因为在具体实施中遇到的问题,说白了就是上面的三种方式都无法提供实际的安全性,下面我们来具体分析一下:
这和VRRP的实现原理有关,虽然Master的VRRP通告报文经过MD5方式加密,但是攻击者可以截获、复制并发送同样的加密报文,从而导致出现多个Master,使下行交换机无法正确上传流量;另外一种情况,即使攻击者不复制发送VRRP通告报文,它也可以通过复制发送免费ARP报文,或者响应下行设备的ARP请求报文,从而误导下行交换机的流量选择,同样造成了路由黑洞。
基于以上情况,RFC4768取消了这些在其位不谋其政的安全选项,只是为了向RFC2338兼容,仍然保留了这些安全字段。
6.一个典型的VRRP故障分析
前期有同事从事IMS项目,其中需要在Juniper路由器上设置VRRP,基本拓扑如下:
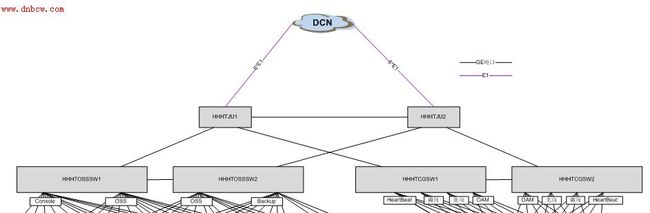
图(IMS项目当中的VRRP部署拓扑)
两台Juniper路由器各连接两台交换机,然后两台路由器之间做VRRP备份组。遇到的问题是,所有配置完成以后,两台路由器的VRRP实例均显示自己是Master,如下图:

图(Router-1的VRRP状态)
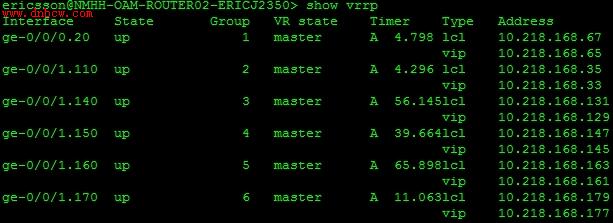
图(Router-2的VRRP状态)
通过上面两个图可以看到,对于VRID分别为1、2、3、4、5、6这六个VRRP备份组来说,两台路由器均认为自己是Master,而正常情况是:对于每一个VRRP备份组,都会有一台路由器是Master路由器,其它路由器全部是Backup路由器。
通过比对IMS项目的CND设计,排除了配置错误的可能性,来看一下VRRP的统计信息:
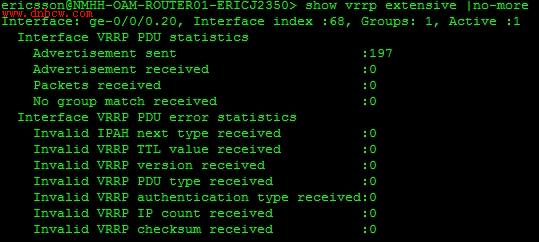
图(Router-1的VRRP统计信息)
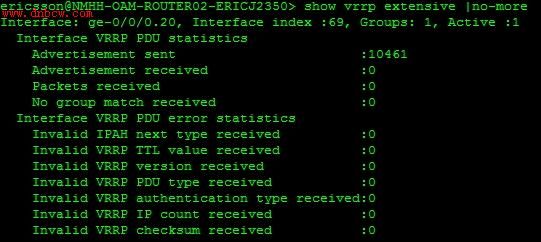
图(Router-2的VRRP统计信息)
很明显可以看到各个VRRP备份组只有VRRP通告报文的发送,而完全没有接受,这是不正常的,而上面的故障现象就是没有收到VRRP通告报文所导致的。
两台Juniper路由器J2350的每一个VRRP进程都没有收到任何一个Advertisement数据包,所以均不知网络中其它VRRP路由器的优先级,所以始终认为自己是master。
注:当一个VRRP进程启动以后,会自动将自己切换为backup状态,如果经过3个Advertisement interval,这里是3*100s=300s,没有收到更高优先级的Advertisement数据包,则将自己切换为master状态。
将关注投向了具体拓扑,这个拓扑和常规实现有所差异,两台路由器不是连接到同一台交换机上,而是分别连接到两台交换机,靠交换机之间的链路来交换VRRP通告报文,以及上行流量的冗余备份,所以断定VRRP通告报文被阻断了。
综上所述:
1.查看各端口及链路是否正常
2.需要查看下行的互联交换机之间是否能够正常通信(即J2350与下行交换机的接口是否与两台交换机互联接口处于同一个VLAN之中)。
3.查看是否是下行交换机的安全策略阻止了VRRP通告报文的转发
经过实际判断,最终确认是下行交换机的安全策略阻止了VRRP通告报文的转发,添加如下策略后,两台路由器的VRRP状态恢复正常:set security zone security-zone trust interfaces ge-0/0/0.10 host-inbound-traffic protocols vrrp
至此,故障解决。