pytorch+yolov3(1)
参考:https://blog.paperspace.com/how-to-implement-a-yolo-object-detector-in-pytorch/
如何在PyTorch中从头开始实现YOLO(v3)对象检测器:第1部分
图片来源:Karol Majek。在这里查看他的YOLO v3实时检测视频
对象检测是一个从深度学习的最新发展中受益匪浅的领域。近年来人们开发了许多用于物体检测的算法,其中一些算法包括YOLO,SSD,Mask RCNN和RetinaNet。
在过去的几个月里,我一直致力于改善研究实验室的物体检测。从这次经历中获得的最大收获之一就是意识到学习对象检测的最佳方法是从头开始自己实现算法。这正是我们在本教程中要做的。
我们将使用PyTorch实现基于YOLO v3的对象检测器,YOLO v3是一种更快的对象检测算法。
本教程的代码旨在在Python 3.5和PyTorch 0.4上运行。它可以在这个Github回购中找到它的全部内容。
本教程分为5个部分:
-
第1部分(本章):了解YOLO的工作原理
-
第2部分:创建网络体系结构的层
-
第3部分:实现网络的正向传递
-
第4部分:对象分数阈值和非最大抑制
-
第5部分:设计输入和输出管道
先决条件
-
您应该了解卷积神经网络的工作原理。这还包括残差块,跳过连接和上采样的知识。
-
什么是对象检测,边界框回归,IoU和非最大抑制。
-
基本的PyTorch用法。您应该能够轻松创建简单的神经网络。
我已经在帖子的末尾提供了链接,以防你在任何方面都不知所措。
什么是YOLO?
YOLO代表你只看一次。它是一个物体探测器,它使用深度卷积神经网络学习的特征来探测物体。在我们弄清楚代码之前,我们必须了解YOLO的工作原理。
完全卷积神经网络
YOLO仅使用卷积层,使其成为完全卷积网络(FCN)。它有75个卷积层,具有跳过连接和上采样层。不使用任何形式的池,并且使用具有步幅2的卷积层来对特征图进行下采样。这有助于防止丢失通常归因于池的低级功能。
作为FCN,YOLO对输入图像的大小不变。然而,在实践中,我们可能希望坚持不变的输入大小,因为在我们实现算法时只会出现各种问题。
这些问题中最重要的一点是,如果我们想要批量处理我们的图像(批量生成的图像可以由GPU并行处理,从而提高速度),我们需要拥有固定高度和宽度的所有图像。这需要将多个图像连接成一个大批量(将许多PyTorch张量连接成一个)
网络通过称为网络步幅的因素对图像进行下采样。例如,如果网络的步幅为32,那么大小为416 x 416的输入图像将产生大小为13 x 13的输出。通常,网络中任何层的步幅等于输出的大小。该图层小于网络的输入图像。
解释输出
通常,(对于所有对象检测器的情况),由卷积层学习的特征被传递到分类器/回归器上,该分类器/回归器进行检测预测(边界框的坐标,类标签等)。
在YOLO中,通过使用使用1×1卷积的卷积层来完成预测。
现在,首先要注意的是我们的输出是一个特征映射。由于我们使用了1 x 1个卷积,因此预测贴图的大小正好是之前的特征贴图的大小。在YOLO v3(及其后代)中,您解释此预测图的方式是每个单元格可以预测固定数量的边界框。
虽然在特征图中描述单元的技术上正确的术语将是神经元,但将其称为单元格使其在我们的上下文中更直观。
在深度方面,我们在特征图中有(B x(5 + C))个条目。B表示每个小区可以预测的边界框的数量。根据该论文,这些B边界框中的每一个可以专门检测某种对象。每个边界框都有5 + C属性,用于描述每个边界框的中心坐标,尺寸,对象度分数和C类置信度。YOLO v3为每个单元预测3个边界框。
如果对象的中心落在该单元格的感知区域中,您希望要素图的每个单元格通过其中一个边界框预测对象。(感受野区域是细胞可见的输入图像区域。有关进一步说明,请参阅卷积神经网络上的链接)。
这与YOLO的训练方式有关,其中只有一个边界框负责检测任何给定的对象。首先,我们必须确定这个边界框属于哪个单元格。
为此,我们将输入图像划分为尺寸等于最终要素图的网格。
让我们考虑下面的一个例子,其中输入图像是416×416,网络的步幅是32.如前所述,特征图的尺寸将是13×13。然后我们将输入图像分成13×13细胞。

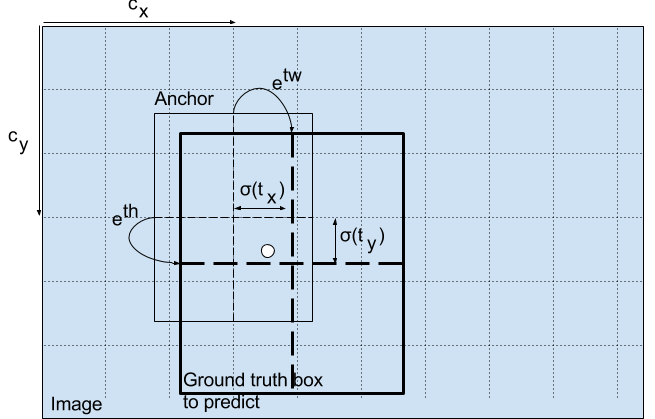
然后,选择包含对象的地面实况框的中心的单元(在输入图像上)作为负责预测对象的单元。在图像中,它是标记为红色的单元格,其中包含地面实况框的中心(标记为黄色)。
现在,红色单元格是网格中第7行的第7个单元格。我们现在将特征图上的第7行中的第7个单元(特征图上的相应单元)指定为负责检测狗的第7个单元。
现在,这个单元格可以预测三个边界框。哪一个将被分配给狗的地面真相标签?为了理解这一点,我们必须围绕锚的概念进行梳理。
请注意,我们在这里讨论的单元格是预测要素图上的单元格。我们将输入图像划分为网格,以确定预测特征图的哪个单元负责预测
锚箱
预测边界框的宽度和高度可能是有意义的,但实际上,这会导致训练期间不稳定的梯度。相反,大多数现代物体探测器预测对数空间变换,或简单地偏移到预定义的称为锚点的默认边界框。
然后,将这些变换应用于锚箱以获得预测。YOLO v3有三个锚点,可以预测每个单元格的三个边界框。
回到我们之前的问题,负责检测狗的边界框将是其锚具有最高IoU和地面实况框的那个。
做出预测
以下公式描述了如何转换网络输出以获取边界框预测。
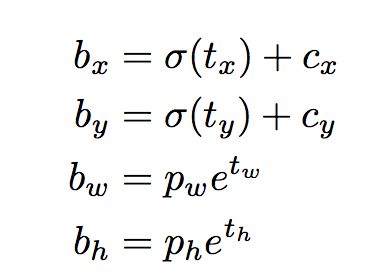
bx,by,bw,bh是我们预测的x,y中心坐标,宽度和高度。tx,ty,tw,th是网络输出的内容。cx和cy是网格的左上角坐标。pw和ph是盒子的锚尺寸。
中心坐标
请注意,我们通过sigmoid函数运行中心坐标预测。这会强制输出值介于0和1之间。为什么会出现这种情况?忍受我。
通常,YOLO不会预测边界框中心的绝对坐标。它可以预测偏移量:
-
相对于预测对象的网格单元格的左上角。
-
由特征图中的单元尺寸标准化,即1。
例如,考虑我们的狗图像的情况。如果对中心的预测是(0.4,0.7),那么这意味着中心位于13 x 13特征图上的(6.4,6.7)。(由于红细胞的左上角坐标是(6,6))。
但等等,如果预测的x,y坐标大于1,会发生什么,比如说(1.2,0.7)。这意味着中心位于(7.2,6.7)。请注意,中心现在位于我们的红细胞右侧的细胞中,或者位于第7行的第8个细胞中。这打破了YOLO背后的理论,因为如果我们假设红色框负责预测狗,那么狗的中心必须位于红色单元格中,而不是位于旁边的单元格中。
因此,为了解决这个问题,输出通过sigmoid函数传递,该函数将输出压缩在0到1的范围内,有效地将中心保持在预测的网格中。
边界框的尺寸
通过对输出应用对数空间变换然后乘以锚来预测边界框的尺寸。
如何转换检测器输出以给出最终预测。图片来源。http://christopher5106.github.io/
结果预测bw和bh由图像的高度和宽度标准化。(培训标签以这种方式选择)。因此,如果包含狗的框的预测bx和by是(0.3,0.8),那么13 x 13特征图上的实际宽度和高度是(13 x 0.3,13 x 0.8)。
对象分数
对象分数表示对象包含在边界框内的概率。对于红色和相邻的网格,它应该接近1,而对于角落处的网格,几乎为0。
对象性得分也通过sigmoid传递,因为它被解释为概率。
阶级信心
类置信度表示检测到的对象属于特定类(狗,猫,香蕉,汽车等)的概率。在v3之前,YOLO习惯了softmax的课堂成绩。
但是,该设计选择已在v3中删除,作者选择使用sigmoid。原因是Softmaxing类得分假设类是互斥的。简单来说,如果一个对象属于一个类,那么它就保证它不属于另一个类。这对于我们将以检测器为基础的COCO数据库来说是正确的。
但是,当我们有像女人和人一样的课程时,这种假设可能不会成立。这就是作者避免使用Softmax激活的原因。
跨越不同尺度的预测。
YOLO v3通过3种不同的尺度进行预测。检测层用于在三种不同尺寸的特征图上进行检测,分别具有步幅32,16,8。这意味着,输入为416 x 416,我们在13 x 13,26 x 26和52 x 52的刻度上进行检测。
网络对输入图像进行下采样,直到第一检测层为止,其中使用具有步幅32的层的特征图进行检测。此外,将层上采样2倍并且与具有相同特征图的先前层的特征图连接。大小。现在在具有步幅16的层处进行另一检测。重复相同的上采样过程,并且在步幅8的层处进行最终检测。
在每个尺度上,每个单元格使用3个锚点预测3个边界框,使得使用的锚点总数为9.(不同尺度的锚点不同)

作者报告说,这有助于YOLO v3更好地检测小物体,这是YOLO早期版本的常见抱怨。上采样可以帮助网络学习细粒度的特征,这些特征有助于检测小物体。
输出处理
对于尺寸为416×416的图像,YOLO预测((52×52)+(26×26)+ 13×13))×3 = 10647个边界框。然而,在我们的图像的情况下,只有一个对象,一只狗。我们如何将检测从10647减少到1?
通过对象置信度进行阈值处理
首先,我们根据对象得分过滤盒子。通常,忽略具有低于阈值的分数的框。
非最大抑制
NMS旨在解决同一图像的多次检测问题。例如,红色网格单元的所有3个边界框可以检测到框,或者相邻的单元可以检测相同的对象。

如果您不了解NMS,我已经提供了一个链接到网站解释相同的内容。
我们的实施
YOLO只能检测属于用于训练网络的数据集中存在的类的对象。我们将使用官方重量文件作为我们的探测器。这些权重是通过在COCO数据集上训练网络获得的,因此我们可以检测80个对象类别。
这是第一部分。这篇文章详细解释了YOLO算法,使您能够实现检测器。但是,如果您想深入了解YOLO如何工作,如何训练以及如何与其他探测器相比,您可以阅读原始论文,我在下面提供的链接。
就是这部分。在下一部分中,我们实现了将检测器组合在一起所需的各种层。
进一步阅读
-
YOLO V1:你只看一次:统一的实时物体检测
-
YOLO V2:YOLO9000:更好,更快,更强
-
YOLO V3:增量改进
-
卷积神经网络
-
边界框回归(附录C)
-
期票
-
非最大限度的抑制
-
PyTorch官方教程
Ayoosh Kathuria目前是印度国防研究与发展组织的实习生,他正致力于改善粒状视频中的物体检测。当他不工作时,他正在睡觉或者在他的吉他上玩粉红色弗洛伊德。您可以在LinkedIn上与他联系,或者查看他在GitHub上做的更多内容
保持最新!将所有最新且最好的帖子直接发送到您的收件箱
订阅