版权声明:本文为作者原创文章,可以随意转载,但必须在明确位置标明出处!!!
上一章讲了DB-API接口协议约定,个人觉得很有必要了解DB-API协议,因为之前我还不知道python的数据库适配器是遵循这个协议约定的时候总是到网上去找对应的数据库接口,然而你们懂的,基本上都是说的怎么去连接数据库,怎么去操作数据库,并没有讲到这些接口文档的定义,对于那些大牛来说不屑于讲,对于哪些刚入门的初学者又不知道,所以我个人觉得很有必要了解DB-API协议约定的。
本章将通过sqlite3,和mysql两个数据库俩说明DP-API协议约定带给我的接口一致性是多么的棒。sqlite3自Python2.5就已经被纳入到Python的标准库中了,所以不需要我们额外的安装它就可以直接使用,对于mysql数据库的适配器我们需要安装一个PyMySQL库,这里我们是用的Python3.6版本的MySQLdb不支持Python3.x的版本。
哪些数据库提供了Python接口
现在我们准备开始学习数据库操作知识了,有些同学就会问Python都有哪些数据库系统的接口或者说Python支持哪些平台呢,答案是:“几乎所有的数据库,几乎所有的平台”。
sqlite3模块
首先我们先从sqlite3模块讲起,因为它现在已经是Python的标准库了,从上一章我们知道根据DB-API协议约定,所有的数据库适配器都必须实现connect函数接口以返回一个Connection对象,所以这里也不例外,首先我们要去操作数据库是第一步就是要先去连接数据库。
import sqlite3
conn = sqlite3.connect('qiubai.db')
连接一个数据库就是这么简单,执行上面的代码后会在当前文件中生成一个qiubai.db文件,当下次在执行时会去检查当前目录下是否存在qiubai.db文件,若存在就不会再去创建,反之创建。当然如果你想在内存中生成一个db文件像下面这么做就可以
import sqlite3
conn = sqlite3.connect(':memory:')
数据库连接获取到了,第二步就是拿到游标了,上一章也提过游标是操作数据库的基础,游标的获取如下:
import sqlite3
conn = sqlite3.connect('qiubai.db')
_cursor = conn.cursor()
游标获得了就是操作数据库了,执行数据库操作使用execute*,获取查询结果fetch*这些都是DB-API协议约定的,所以以后遇到Python的其它数据库适配器直接这么用就是了;剩下的就是数据库的增、删、改、查了
创建表
import sqlite3
conn = sqlite3.connect('sqlite.db')
create_table = '''CREATE TABLE IF NOT EXISTS QIUBAI
(USERID TEXT NOT NULL,
USERNAME TEXT NOT NULL,
FUNNY_NUM INT NOT NULL,
CONTENT TEXT,
URL TEXT);
'''
_cursor = self.conn.cursor()
_cursor.execute(create_table)
conn.commit()
插入数据
import sqlite3
sql = 'INSERT INTO QIUBAI(USERID, USERNAME, FUNNY_NUM, CONTENT, URL) VALUES(‘userid’, 'username', 100, 'content', 'url')'
conn = sqlite3.connect('sqlite.db')
_cursor = self.conn.cursor()
_cursor.executemany(sql, infos)
self.conn.commit()
self._cursor.close()
删除数据
import sqlite3
sql ='''DELETE QIUBAI WHERE userid = 'userid''''
conn = sqlite3.connect('sqlite.db')
_cursor = self.conn.cursor()
_cursor.execute(sql)
self.conn.commit()
self._cursor.close()
查询数据
import sqlite3
sql ='''SELECT * FROM QIUBAI WHERE '''
conn = sqlite3.connect('sqlite.db')
_cursor = self.conn.cursor()
_cursor.execute(sql)
print(_cursor.fetchall())
self.conn.commit()
self._cursor.close()
修改数据
import sqlite3
sql ='''UPDATE QIUBAI set userid = '123456' where userid='1' '''
conn = sqlite3.connect('sqlite.db')
_cursor = self.conn.cursor()
_cursor.execute(sql)
print(_cursor.fetchall())
self.conn.commit()
self._cursor.close()
简单的增删查改就上面这里,当然像其它关联查询、左连接、右连接、join等操作本章不做介绍,感兴趣的同学可以去了解一下。这里需要值得注意的是游标用完以后一定要记得关闭,也就是释放掉游标资源,不要问我为什么,这些都是写血泪教训,如果长期不本关闭游标数据库会抛出maximum open cursors exceeded。异常。
PyMySQL模块
该模块是第三方模块,所以我们必须要先安装它,安装它很简单直接在ubuntu终端执行下面的命令回车就可以了
sudo pip install PyMySQL
若安装没有问题可以执行下面的命令查看PySQLdb都提供了哪些方法属性
import pymysql
dir(pymysql)
执行后的结果如下:

从结果中我们可以看到PyMySQL模块是遵循了DB-API协议约定的,apilevel,threadsafety等属性都有。既然模块是遵循DP-API协议的那么第一步任然是链接数据,第二步是获取游标,第三步才是操作数据库,所以这里不在把pymysql模块的增、删、改、查再说一遍了,跟上面的sqlite使用是一样的,这里是给出创建表的语句,因为sqlite数据库的数据类型定义与mysql数据库的数据定义是不一样的。
create_table = '''CREATE TABLE IF NOT EXISTS QIUBAI
(ID INT(11) NOT NULL AUTO_INCREMENT,
USERID VARCHAR(20) NOT NULL,
USERNAME VARCHAR(20) NOT NULL,
FUNNY_NUM INT NOT NULL,
CONTENT VARCHAR(1024),
URL VARCHAR(256),
PRIMARY KEY (ID))ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin
AUTO_INCREMENT=1;
'''
客户端概念
这里需要着重提一点的是客户端的概念,PyMySQL模块只是客户端模块,这个模块提供的是和mysql数据库服务之间的交互。并不是mysql数据库,这点概念大家一定要切记、切记。所以如果操作数据库那么还得安装一个mysql数据库服务。MySQL可以到官网下载https://dev.mysql.com/doc/, sqlite数据库则不需要,sqlite设计之处就要让它成为程序的一部分,它是一个轻量级的数据库系统,像安卓系统上基本都使用自带的sqlite数据库,让它成为应用的一部分。
实战
讲了这么多该是自己动手时间的时候了,实战的内容是把我们从糗百爬到的数据分别写入到sqlite数据库和mysql数据库里,我们的程序又新增了两个文件分别是SqliteImpl.py、MySQLImpl.py;从文件名上我们就可以看出两个文件分别是处理sqlite、mysql数据库的。所以大家在对文件命名的时候一定要想一个有意义的名字,一定要养成一个好习惯,我个人有些强迫症,有时候想一个变量名都要想很久。下面给出两个文件的代码实现,看不清的可以到我的git上去fork https://github.com/Gavinxyj/Python/tree/master/python_study/Scrapy/modules欢迎大家fork、star
# SqliteImpl.py
import sqlite3
class SqliteImpl(object):
"""docstring for SqliteImpl"""
def __init__(self):
super(SqliteImpl, self).__init__()
try:
self.conn = sqlite3.connect('sqlite.db')
create_table = '''CREATE TABLE IF NOT EXISTS QIUBAI
(USERID TEXT NOT NULL,
USERNAME TEXT NOT NULL,
FUNNY_NUM INT NOT NULL,
CONTENT TEXT,
URL TEXT);
'''
self._cursor = self.conn.cursor()
self._cursor.execute(create_table)
self.conn.commit()
except Exception as e:
raise e
def insert_record(self, infos):
try:
sql = 'INSERT INTO QIUBAI(USERID, USERNAME, FUNNY_NUM, CONTENT, URL) VALUES(?, ?, ?, ?, ?)'
#for info in infos:
self._cursor.executemany(sql, infos)
self.conn.commit()
self._cursor.close()
except Exception as e:
self.conn.rollback()
raise e
def delete_record(self):
pass
def dump(self):
try:
sql = 'SELECT * FROM QIUBAI'
self._cursor.execute(sql)
self._cursor.close()
ret = _cursor.fetchall()
print(len(ret))
except Exception as e:
raise e
def update_record(self):
pass
# MySQLImpl.py
import pymysql
class MySQLImpl(object):
"""docstring for MySQLImpl"""
def __init__(self):
super(MySQLImpl, self).__init__()
self.conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='root', db='test', charset='utf8')
try:
create_table = '''CREATE TABLE IF NOT EXISTS QIUBAI
(ID INT(11) NOT NULL AUTO_INCREMENT,
USERID VARCHAR(20) NOT NULL,
USERNAME VARCHAR(20) NOT NULL,
FUNNY_NUM INT NOT NULL,
CONTENT VARCHAR(1024),
URL VARCHAR(256),
PRIMARY KEY (ID))ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin
AUTO_INCREMENT=1;
'''
self._cursor = self.conn.cursor()
self._cursor.execute(create_table)
self.conn.commit()
except Exception as e:
raise e
def insert_record(self, infos):
try:
sql = 'INSERT INTO QIUBAI(USERID, USERNAME, FUNNY_NUM, CONTENT, URL) VALUES(%s, %s, %s, %s, %s)'
self._cursor = self.conn.cursor()
# for info in infos:
self._cursor.executemany(sql, infos)
self.conn.commit()
self._cursor.close()
except Exception as e:
# self.conn.rollback()
raise e
def delete_record(self):
pass
def dump(self):
try:
self._cursor = self.conn.cursor()
sql = 'SELECT * FROM QIUBAI'
self._cursor.execute(sql)
self._cursor.close()
ret = self._cursor.fetchall()
print(len(ret))
except Exception as e:
raise e
def update_record(self):
pass
从代码中可以看到增、删、改、查的使用都是一样的,程序执行后的结果如下(sqlite的可视化工具可以使用sqlitestudio,mysql可视化工具可以使用SQLyog,可以自行到网上去下,当然你也可以私信我)
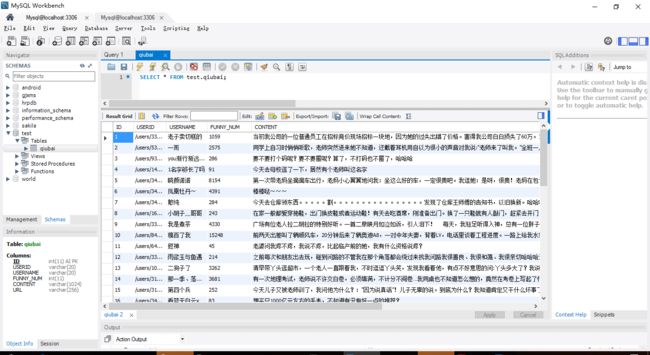
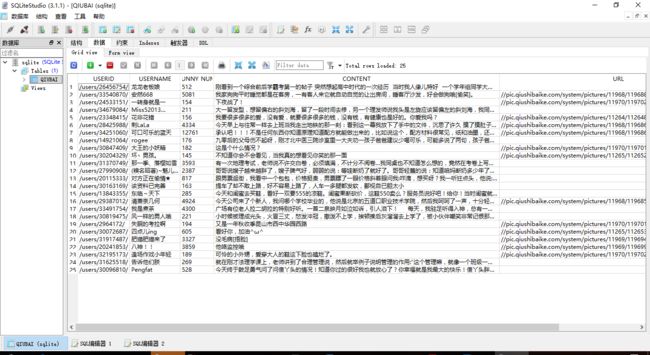
okay,到这里本章就结束了,还是老生长谈,一定要动手啊。下一章将会讲到对象关系映射(Object Relational Mapping,简称ORM)编程。