scrapy爬虫和Django后台结合(爬取酷我音乐)
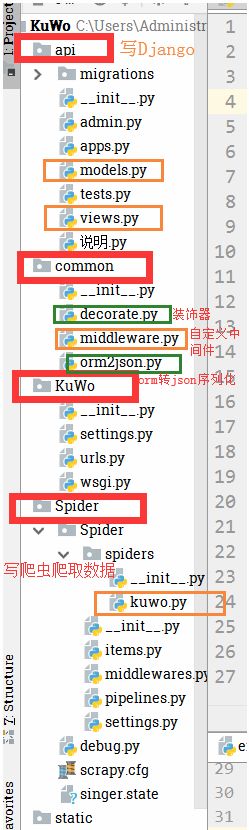
代码结构:
Spider/spider/kuwo.py爬虫代码:
# -*- coding: utf-8 -*-
import scrapy
import demjson
import re
import os
from ..items import MusicItem, SingerItem
from bloomfilter import Bloomfilter #布隆过滤
class KuwoSpider(scrapy.Spider):
name = 'kuwo'
allowed_domains = ['kuwo.cn']
start_urls = [
'http://artistlistinfo.kuwo.cn/mb.slist?stype=artistlist&category=0&order=dict&pn=0&rn=100&encoding=utf8&prefix='
]
def __init__(self, name=None, **kwargs):
super(KuwoSpider, self).__init__(name=name, kwargs=kwargs)
if not os.path.exists("singer.state"):
self.bloom = Bloomfilter(10000000)
else:
# 存储状态文件后缀随便写
self.bloom = Bloomfilter("singer.state")
def start_requests(self):
for x in [chr(code) for code in range(97, 123)]:
url = self.start_urls[0] + x
yield scrapy.Request(
url=url,
callback=self.parse,
dont_filter=True,
meta={'prefix': x}
)
def parse(self, response):
meta = response.meta
json_obj = demjson.decode(response.text)
total = json_obj.get("total", "0")
total = int(total) if total.isdigit() else 0
rn = json_obj.get("rn", "100")
rn = int(rn) if rn.isdigit() else 100
total_page = total//rn if total % rn == 0 else total//rn+1
# 处理数据并存储
artistlist = json_obj.get('artistlist', [])
for artist in artistlist:
pic = artist.get('pic')
if not self.bloom.test(pic):
item = SingerItem()
item['singer_id'] = artist.get("id")
url = "http://search.kuwo.cn/r.s?stype=artist2music&artistid={}&pn=0&rn=100&sortby=0&show_copyright_off=1&alflac=1&pcmp4=1&encoding=utf8&vipver=MUSIC_8.7.7.0_PQ&plat=pc&devid=51016591&thost=search.kuwo.cn".format(item['singer_id'])
yield scrapy.Request(
url=url,
callback=self.parse_music,
dont_filter=True,
)
item['singer_name'] = artist.get("name")
item['singer_music_num'] = artist.get("music_num")
item['singer_listen'] = artist.get("listen")
item['singer_like'] = artist.get("like")
item['singer_pic'] = pic
# pic_list = pic.split("/")[:-1]
# pic_path = "../imgs/" + "/".join(pic_list)
# # if not os.path.exists(pic_path):
# # os.makedirs(pic_path)
# os.makedirs(pic_path, exist_ok=True)
item['singer_aartist'] = artist.get("AARTIST")
item['singer_isstar'] = artist.get("isstar")
item['singer_prefix'] = response.meta.get("prefix")
yield item
self.bloom.add(pic)
# 数据的持久化
self.bloom.save("singer.state")
else:
print("数据已经存在")
pattern = re.compile(r"pn=(\d+)")
pn = pattern.findall(response.url)
pn = pn[0] if pn else 0
pn = int(pn)
pn += 1
pattern = re.compile(r"pn=\d+")
url = pattern.sub("pn={}".format(pn), response.url)
print("---------------", url)
if pn < total_page:
yield scrapy.Request(
url=url,
callback=self.parse,
dont_filter=True,
meta=meta
)
def parse_music(self, response):
json_obj = demjson.decode(response.text)
for music in json_obj.get('musiclist', []):
item = MusicItem()
item['music_musicrid'] = music.get("musicrid")
item['music_name'] = music.get("name")
item['music_artist'] = music.get("artist")
item['music_releasedate'] = music.get("releasedate")
item['music_artistid'] = music.get("artistid")
item['music_alnumind'] = music.get("albumid")
item['music_album'] = music.get("album")
yield itemitems.py 代码
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
from scrapy_djangoitem import DjangoItem
from api.models import Singer, Music
class SingerItem(DjangoItem):
django_model = Singer
class MusicItem(DjangoItem):
django_model = Music
Spider/spider/pipelines.py代码(保存爬取的数据)
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class SpiderPipeline(object):
def process_item(self, item, spider):
return item
from scrapy.pipelines.images import ImagesPipeline, FilesPipeline
from scrapy.http import Request
from urllib.parse import urljoin
from .items import SingerItem, MusicItem
class MyImagesPipeline(FilesPipeline):
def get_media_requests(self, item, info):
if 'singer_pic' in dict(item):
pic = item['singer_pic']
pic = urljoin("http://img1.sycdn.kuwo.cn/star/starheads/", pic)
return [Request(pic, meta={
'path': item['singer_pic']
})]
else:
music_id = item['music_musicrid']
music_src ="http://antiserver.kuwo.cn/anti.s?rid=MUSIC_{}&format=aac|mp3&type=convert_url&response=url".format(music_id)
return [
Request(music_src, meta={
'path': item['music_musicrid'] + '.acc'
})
]
def file_path(self, request, response=None, info=None):
path = request.meta.get('path')
if '/' in path:
return "../imgs/" + path
else:
return "../musics/" + path
def item_completed(self, results, item, info):
print('=====', results)
if 'singer_pic' in dict(item):
pass
else:
status, value = results[0] if results else (0, {'path': '没有路径'})
item['music_src'] = value.get('path').replace("../", "")
item['music_lrc_src'] = ""
item.save()
return itemsettings.py代码:
ITEM_PIPELINES = {
'Spider.pipelines.SpiderPipeline': 300,
'Spider.pipelines.MyImagesPipeline': 300,
}
FILES_URLS_FIELD = "singer_pic"
FILES_STORE = "../imgs/"common/orm2json.py 代码:
对数据进行json序列化
from django.db.models.query import QuerySet
import datetime
def object_to_json(model, ignore=None):
if ignore is None:
ignore = []
if type(model) in [QuerySet, list]:
json = []
for element in model:
json.append(_django_single_object_to_json(element, ignore))
return json
else:
return _django_single_object_to_json(model, ignore)
def _django_single_object_to_json(element, ignore=None):
return dict([(attr, getattr(element, attr)) for attr in [f.name for f in element._meta.fields]])api/models.py代码:
from django.db import models
class Singer(models.Model):
singer_id = models.IntegerField()
singer_name = models.CharField(max_length=200)
singer_music_num = models.IntegerField()
singer_listen = models.IntegerField()
singer_like = models.IntegerField()
singer_pic = models.CharField(max_length=200)
singer_aartist = models.CharField(max_length=200)
singer_isstar = models.IntegerField()
singer_prefix = models.CharField(max_length=200, default='')
singer_ishot = models.BooleanField(default=False)
class Music(models.Model):
music_musicrid = models.IntegerField()
music_name = models.CharField(max_length=200)
music_artist = models.CharField(max_length=200)
music_releasedate = models.CharField(max_length=200)
music_artistid = models.IntegerField()
music_album = models.CharField(max_length=200)
music_alnumind = models.IntegerField()
# 本地地址,不是远程地址
music_src = models.CharField(max_length=200)
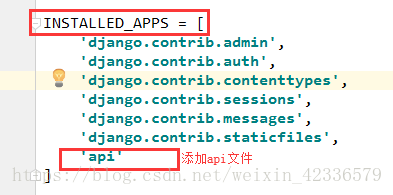
music_lrc_src = models.CharField(max_length=200)在KuWO写Django的配置文件settings.py 中需要做一下配置:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
# 数据库名称
'NAME': 'kuwodb',
'USER': 'root',
'PASSWORD': '123456',
'POST': '12.0.0.1',
'PORT': 3306
}
}
# redis数据库配置
CACHES = {
'default': {
'BACKEND': 'django_redis.cache.RedisCache',
'LOCATION': 'redis://127.0.0.1:6379',
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
},
},
}
common/middleware.py 中自定义中间件的配置
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
# 这是自定义的中间件,至少要放在SessionMiddleware之后
'common.middleware.MyCustomMiddleware',
# 用于过滤UserAgent的中间件
'common.middleware.BadUserAgentMiddleware',
# 用于过滤哪些ip可以访问系统的中间件
'common.middleware.GoodIpMiddlleware',
# # 判定cookie中是否有指定字段
# 'common.middleware.BadCookieMiddleware',
# 限定ip访问次数的中间件
'common.middleware.SlowSpeedMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]common/middleware.py代码:
设置安全问题
import re
from django.conf import settings
from django.http import HttpResponsePermanentRedirect, HttpResponseBadRequest, HttpResponseForbidden, HttpResponseNotFound
from django.utils.deprecation import MiddlewareMixin
import time
import demjson
class MyCustomMiddleware(MiddlewareMixin):
def process_request(self, request):
print('有人来访问后台了')
def process_response(self, request, response):
return response
class BadUserAgentMiddleware(MyCustomMiddleware):
def process_request(self, request):
user_agent = request.META.get('HTTP_USER_AGENT', '')
print(user_agent)
if not user_agent:
return HttpResponseBadRequest(content='你是一个爬虫吧?')
if 'python' in user_agent or 'requests' in user_agent or 'scrapy' in user_agent:
return HttpResponseBadRequest(content='你是一个框架写的爬虫吧')
class GoodIpMiddlleware(MiddlewareMixin):
def process_ruquest(self, request):
ip = request.META.get('REMOVE_ADDR')
if ip in ['127.0.0.1', 'localhost']:
return HttpResponseForbidden(content='你的ip禁止访问该系统!!!')
class BadCookieMiddleware(MiddlewareMixin):
def process_request(self, request):
cookies = request.COOKIES
if 'my_name' not in cookies:
return HttpResponseBadRequest(content='不是一个好cookie')
VISIT_TOTAL_TIME = 60
VISIT_PER_SECOND = 10
AllOW = {}
class SlowSpeedMiddleware(MiddlewareMixin):
ip = '1.1.1.1'
def process_request(self, request):
ctime = time.time()
ip = self.ip
if ip not in AllOW:
AllOW[ip] = [ctime, ]
else:
time_list = AllOW[ip]
while True:
last_time = time_list[-1] if time_list else None
if not last_time:
break
if ctime - VISIT_TOTAL_TIME > last_time:
time_list.pop()
else:
break
if len(AllOW[ip]) > VISIT_PER_SECOND:
error_msg = {
'msg': '访问频率太快啦!限制你的{}!{}秒后再试!!!'.format(ip, self.wait())
}
return HttpResponseNotFound(content=demjson.encode(error_msg), content_type='application/json')
AllOW[ip].insert(0, ctime)
def wait(self):
ip = self.ip
ctime = time.time()
first_in_time = AllOW[ip][-1]
wt = VISIT_TOTAL_TIME - (ctime - first_in_time)
return int(wt)然后在Terminal中运行命令进行数据迁移,建立数据表,在此之前要先把数据库建好
python manage.py makemigrations
python manage.py migrate
STATICFILES_DIRS = [
os.path.join(BASE_DIR, "static"),
os.path.join(BASE_DIR, "imgs"),
]
CACHES = {
'default': {
'BACKEND': 'django_redis.cache.RedisCache',
'LOCATION': 'redis://127.0.0.1:6379',
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
},
},
}
api/views.py 代码:
从数据库查询数据,若数据库中没有则从网页上请求,然后缓存到redis中(程序运行时要开启redis服务)
from django.shortcuts import render
from django.http import JsonResponse
from common.decorate import api_json
from .models import Singer, Music
from common.orm2json import object_to_json
from django.db import connection
from django.core.cache import cache
PAGE_SIZE = 10
def index(request):
dict1 = {
'msg': 'hello world'
}
return JsonResponse(dict1)
def get_singers(request):
msg = '查询成功'
status = 5
# 网页需要给的参数:分页page 每页大小size 名字首字母cname
page = request.GET.get('page', '1')
page = int(page) if page.isdigit() and '-' not in page and page != '0' else 1
size = request.GET.get('size', str(PAGE_SIZE))
size = int(size) if size.isdigit() and '-' not in size and size != '0' else PAGE_SIZE
cname = request.GET.get('cname', 'hot')
cname = cname.lower()
if cname != 'hot':
cname = cname[0] if cname and cname in get_cnames(request) else 'a'
key = "singer_{}".format(cname)
if cache.has_key(key):
print('从缓存中读取', key)
singers = cache.get(key)
else:
singers = Singer.objects.filter(singer_prefix=cname)
cache.set(key, singers, 60)
else:
# 返回hot的数据
key = "singer_{}".format(cname)
singers = get_hot(request)
cache.set(key, singers, 60)
singer_total = len(singers)
if size > PAGE_SIZE:
status = False
msg = '页码超过指定范围'
size = PAGE_SIZE
singers = singers[(page-1)*size: page*size]
current_page = page
total_page = singer_total // size if singer_total % size == 0 else singer_total // size + 1
page_size = size
# orm -> dict
pages = []
if page > total_page:
msg = '超过总页数'
status = False
singers = object_to_json(singers)
return_dict = {
'msg': msg,
'status': status,
'singer_total': singer_total,
'current_page': current_page,
'total_page': total_page,
'page_size': page_size,
'cname': cname,
'pages': pages,
'singers': singers,
}
return return_dict
# 后台需要返回的:total current_page total_page size cname singers
def get_hot(request):
rows = Singer.objects.order_by('singer_listen').reverse()
return rows
def get_cnames(request):
cursor = connection.cursor()
cursor.execute("select singer_prefix from api_singer group by singer_prefix")
rows = cursor.fetchall()
return rows
def get_music_by_singer_id(request):
msg = '查询成功'
status = 5
singer_id = request.GET.get('singer_id')
singer_id = int(singer_id) if singer_id and singer_id.isdigit() and '-' not in singer_id else 0
page = request.GET.get('page', '1')
page = int(page) if page.isdigit() and '-' not in page and page != '0' else 1
size = request.GET.get('size', str(PAGE_SIZE))
size = int(size) if size.isdigit() and '-' not in size and size != '0' else PAGE_SIZE
key = "music_{}".format(singer_id)
if cache.has_key(key):
print('从缓存中读取', key)
musics = cache.get(key)
else:
musics = Music.objects.filter(music_artistid=singer_id)
cache.set(key, musics, 60)
musics = object_to_json(musics)
music_total = len(musics)
if size > PAGE_SIZE:
status = False
msg = '页码超过指定范围'
size = PAGE_SIZE
musics = musics[(page-1)*size: page*size]
current_page = page
total_page = music_total // size if music_total % size == 0 else music_total // size + 1
page_size = size
# orm -> dict
pages = []
if page > total_page:
msg = '超过总页数'
status = False
return_dict = {
'msg': msg,
'status': status,
'music_total': music_total,
'current_page': current_page,
'total_page': total_page,
'page_size': page_size,
'pages': pages,
'musics': musics,
}
return return_dict
def get_music_src_by_music_id(request):
pass
def get_lrc_src_by_music_id(request):
pass
@api_json
def singers(request):
return get_singers(request)
@api_json
def musics(request):
return get_music_by_singer_id(request)common/decorate.py代码:
from django.http import JsonResponse
from functools import wraps
def api_json(func):
@wraps(func)
def _func(*args, **kwargs):
json_obj = func(*args, **kwargs)
return JsonResponse(json_obj)
# return json_obj
return _func
# 测试代码运行,在被导入其他文件中时下面代码不会起作用
if __name__ == '__main__':
@api_json
def hello():
return {'name': 'zhangsan'}
print(hello())在路由中配置路径:(KuWo/urls.py)
from django.contrib import admin
from django.urls import path
from api import views as api_views
urlpatterns = [
path('admin/', admin.site.urls),
path('', api_views.index),
path('singers/', api_views.singers),
path('musics/', api_views.musics),
]