ElasticSearch架构原理
ElasticSearch
本文主要介绍了ElasticSearch的架构原理,存储模型,近实时搜索原理和常用插件es-head和es-sql的简单安装。
1 架构及原理
1.1 概述
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎Apache Lucene™ 基础上的搜索引擎,它不仅包括了全文搜索功能,还可以进行以下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索
- 实时分析的分布式搜索引擎
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
Elasticsearch 可以布置成集群模式,它也是采用主从架构。master对外读写。建立索引的请求都先经过master,然后才会把集群索引信息同步到slave。
只有建立索引和类型需要经过 Master,数据的写入有一个简单的 Routing 规则,可以 Route 到集群中的任意节点,所以数据写入压力是分散在整个集群的。
Elasticsearch的数据结构
ES使用的是倒排索引。
- 正排索引:文档id到单词的关联关系
- 倒排索引:单词到文档id的关联关系
倒排索引(Inverted Index)是实现“单词-文档id矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。
倒排索引示例:
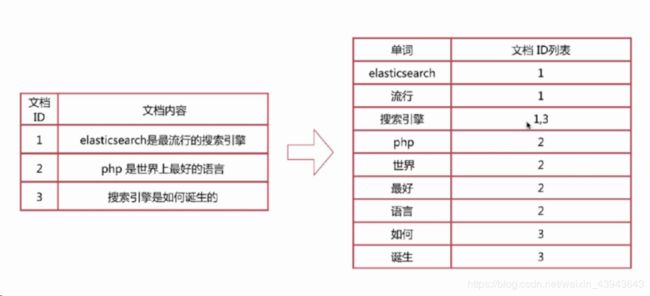
Elasticsearch索引的精髓
一切设计都是为了提高搜索的性能
Elasticsearch的索引思路
将磁盘里的东西尽量搬进内存,减少磁盘随机读取次数(同时也利用磁盘顺序读特性),结合各种奇技淫巧的压缩算法,用及其苛刻的态度使用内存。
1.2 存储结构
Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档。
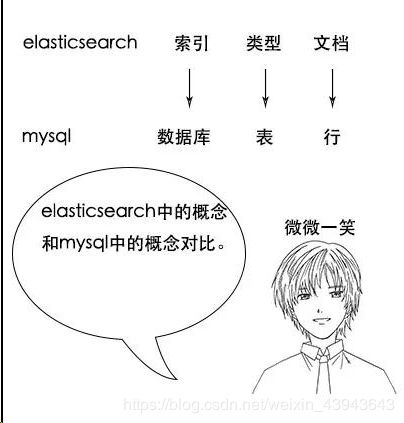
索引 Index
ES将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合。
它是个逻辑命名空间,类似于数据库概念中的数据库。
类型 Type
类型是索引内部的逻辑分区(category/partition),然而其意义完全取决于用户需求。因此,一个索引内部可定义一个或多个类型(type)。
类似于数据库概念中的一张表。
文档 Document
文档是索引和搜索的原子单位,它是包含了一个或多个域(Field)的容器,基于JSON格式进行表示。文档由一个或多个域组成,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”。
每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。
它是具体事实数据的体现,类似于数据库概念中的一条记录。
SHARD 分片
- index包含多个shard,每个shard都是一个最小工作单元,承载部分数据
- 每个shard都是一个lucene实例,有完整的建立索引和处理请求的能力。
- 增减节点时,shard会自动在nodes之间负载均衡
- shard分为primary shard和replica shard,每个document只存在于某一个primary shard以及其对应的replica shard中
- replica shard是primary shard的副本,负责容错,以及承担读请求负载提高搜索性能。
- primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改,primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard
- primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上
SEGMENT
elasticsearch中每个shard每隔1秒都会refresh一次,每次refresh都会生成一个新的segment,一个segment对应着硬盘或者缓存(内存充当文件系统的)的一个文件,占用一个文件描述符。
translog
事务日志,在每一次对 Elasticsearch 进行操作时均进行了日志记录。作为临时文件存储在硬盘上。理想中应该是任何一次写入都刷入磁盘,但是性能考虑不可能。实际上是每几秒中调用一次fsync刷到磁盘来提高吞吐量。这当然带来了丢失数据的可能。
1.3 数据写入过程
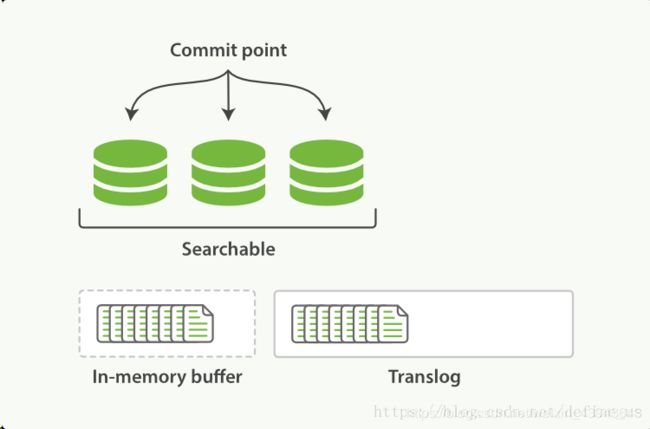
-
第一步,新文档被写入内存,操作被写入translog
-
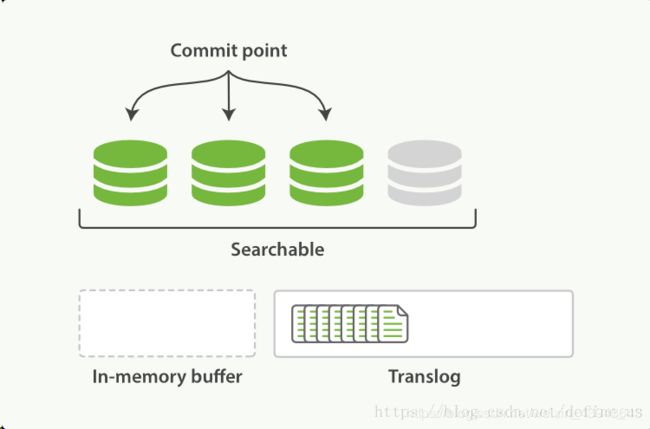
第二步,refresh操作
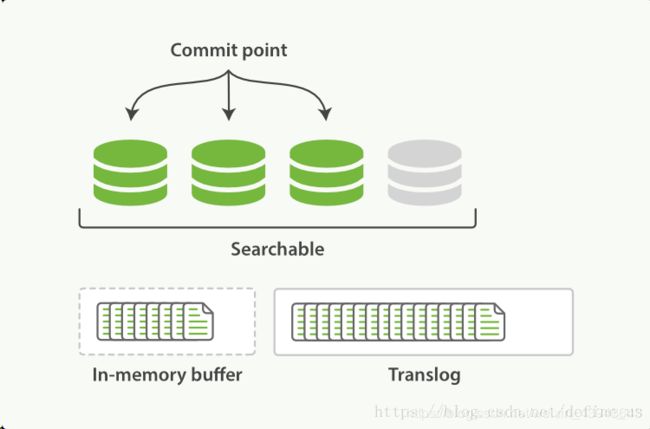
ES中默认每1秒中进行一次refresh。
refresh操作会清空buffer中的数据(translog数据不变),在这1秒时间内写入内存的新文档都会被写入一个文件系统缓存(filesystem cache)中,并构成一个分段(segment)新建segment并式segment可以被检索的到,但是尚未写入硬盘。
ES检索数据会同时检索buffer和segment,这样保证数据每一次都能拿到最新的数据
-
第三步,不断累积数据,重复数据写到buffer和translog,每隔一秒将生成一个新的segment,而translog文件将越来越大。
-
第四步,一定时间后,执行flush操作。清空buffer,translog,所有segment处于commit状态。

-
第五步 segment合并写入磁盘,一旦合并,旧的segment和translog将被删除。


segment合并极为消耗资源,所以一般情况下ES会对段合并消耗的资源加以限制。
1.3 为什么这么快
-
内部使用Lucene的倒排索引
-
数据进行压缩
-
组合查询时的优化
Posting list
Elasticsearch分别为每个索引的每个field都建立了一个倒排索引,称为Posting List。Posting list就是一个int的数组,存储了所有符合某个term的文档id。
Term Dictionary
Elasticsearch为了能快速找到某个term,将所有的term排个序,二分法查找term,logN的查找效率,就像通过字典查找一样,这就是Term Dictionary。
Term Index
直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树:
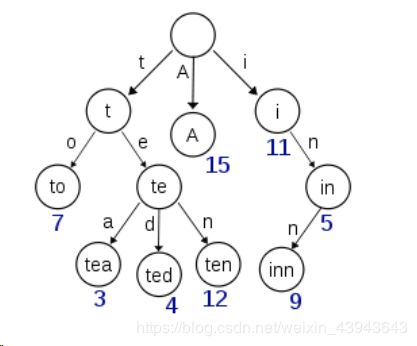
这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。
所以term index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系,再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。
压缩
压缩term index
FST(Finite State Transducers)
FSTs are finite-state machines that map a term (byte sequence) to an arbitrary output.
压缩 Posting List
Frame Of Reference
增量编码压缩,将大数变小数,按字节存储
2 ElasticSearch 6.5 安装
a 下载安装包
在官网选择版本下载。
b 解压
unzip elasticsearch-6.5.0.zip
c 修改配置文件
需要修改的主要几项:
vim /opt/Apps/es6.5/config
/elasticsearch.yml
##集群名称
cluster.name: daas
#主机地址,这里写本机ip
network.host: daas6
#默认的9200被占用,换一个端口
http.port: 9205
#节点名称
node.name: daas1
#设置主节点
node.master:true
#数据存放目录
path.data:/var/es
# 增加新的参数,这样head插件可以访问es。设置参数的时候:后面要有空格
http.cors.enabled: true
http.cors.allow-origin: "*"
es启动需要其他配置
vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 131072
d 创建es用户,并把es文件夹设给es用户
useradd es -g es -p es
chown -R es:es es6.5
e 启动
在es的bin下,使用es用户执行:
./elasticsearch&
访问daas6:9200验证。

es-head插件安装
a 下载head及其依赖环境安装包
#下载解压head安装包
wget https://github.com/mobz/elasticsearch-head/archive/master.zip
#安装NodeJS并配置环境变量
yum install -y nodejs
#安装npm
npm install -g cnpm --registry=https://registry.npm.taobao.org
#安装grunt
npm install -g grunt
npm install -g grunt-cli --registry=https://registry.npm.taobao.org --no-proxy
b 进入head目录
npm install
c 开启远程访问
vi /opt/Apps/elasticsearch-head-master/Gruntfile.js
#找到connect,新增hostname:“0.0.0.0”。

d 启动grunt
在head目录下:
grunt server
即可在daas6:9205。
安装es-sql
在github上下载插件安装包并解压。
./bin/elasticsearch-plugin install https://github.com/NLPchina/elasticsearch-sql/releases/download/6.5.0.0/elasticsearch-sql-6.5.0.0.zip
在elasticsearch 5.x / 6.x上,使用elasticsearch sql site chrome扩展(确保在elasticsearch.yml上启用cors)。或者,下载并解压缩site-server
root用户执行:
cd site-server
npm install express --save
node node-server.js
在http://daas6:8080/访问,如下图。

简单sql查询示例(更多语法请见github):
Query :
SELECT * FROM bank WHERE age >30 AND gender = 'm'
Aggregation :
select COUNT(*),SUM(age),MIN(age) as m, MAX(age),AVG(age)
FROM bank GROUP BY gender ORDER BY SUM(age), m DESC
Delete DELETE FROM bank WHERE age >30 AND gender = 'm'