CPL: Robust Classification with Convolutional Prototype Learning(softmax的替代品,泛化性能更佳)
一言以蔽之,CVPR2018,分类softmax的替代品,或许不能明显提点,但泛化性能更佳。
其实16个月前就尝试过了,近期正好又需要用到,故而来整理下。
原作者只给出了python2的代码,并且未给出特定格式的数据集,修改了训练入口及兼容了python3。
详细实现及代码见:https://github.com/zmdsjtu/Convolutional-Prototype-Learning
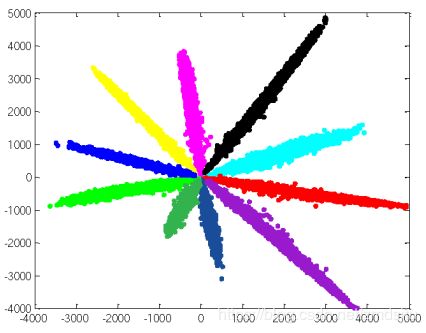
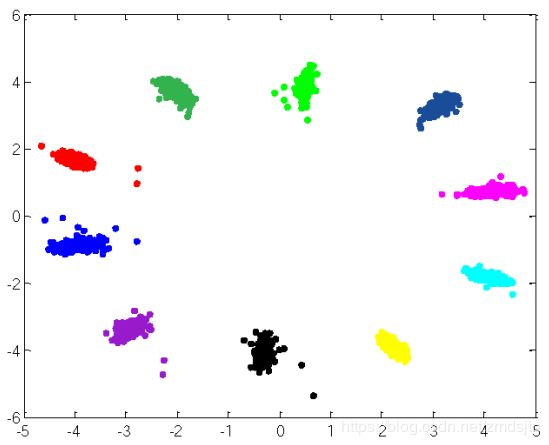
二维mnist可视化后看着还是非常神清气爽的:
- 从左到右分别为softmax,CPL,GCPL
- 实际用其他数据集复现出来的效果也类似
 |
 |
 |
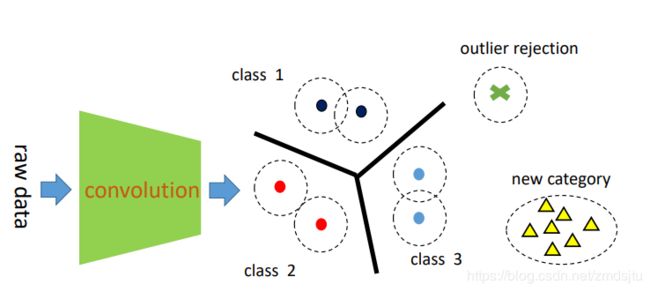
Prototype Learning
中心思想——学习出m个中心点(m可以和类别数量一致,也可以更多)
CNN网络将原数据映射到一个n维空间,类似于LVQ聚类算法,构建m个“中心点”用以代表各类,在反向传播的时候不断迭代更新各个“中心点”的位置,迫使类内更聚合,类间距离更大,关键点就在于如何设计loss
网络前向的时候,距离最近的中心点代表的类别即为最终结果
Loss设计
MCE/MCL/DCE三选一
- Minimum classification error loss(MCE)
- Margin based classification loss(MCL)
- Distance based cross entropy loss(DCE)
加上pl组成最终版loss
- Generalized CPL with prototype loss(GCPL)
作者实现的mnist采用的DCE+0.01PL,都可以试一下,DCE收敛速度最快
详细loss话不多说上代码:
Minimum classification error loss(MCE)
确实能拉近类内距离和增大类间距离,这里还有公式推导竟然,然而不重要,直接看loss代码
- 如果分类正确,标签距离-第二近的距离,为负,sigmoid后作为loss
- 如果分类错误,标签距离-最近距离,为正,sigmoid后作为loss
def mce_loss(features, labels, centers, epsilon):
# 如果10类,为一个N * 10的矩阵
dist = distance(features, centers)
values, indexes = tf.nn.top_k(-dist, k=2, sorted=True)
top2 = -values
d_1 = top2[:, 0]
d_2 = top2[:, 1]
row_idx = tf.range(tf.shape(labels)[0], dtype=tf.int32)
idx = tf.stack([row_idx, labels], axis=1)
# d_y 为标签的距离
d_y = tf.gather_nd(dist, idx, name='dy')
# indicator 正确的为1,错误的为0
indicator = tf.cast(tf.nn.in_top_k(-dist, labels, k=1), tf.float32)
# d_c,如果label正确为第二近的距离;如果错误,为最近的距离
d_c = indicator * d_2 + (1 - indicator) * d_1
# 如果标签正确,标签距离-第二近距离,为负;
# 如果标签错误,标签距离-最近距离,为正
measure = d_y - d_c
loss = tf.sigmoid(epsilon * measure, name='loss')
mean_loss = tf.reduce_mean(loss, name='mean_loss')
return mean_lossMargin based classification loss(MCL)
加入了margin容错度,sigmoid换成了relu,其他一致
def mcl_loss(features, labels, centers, margin):
dist = distance(features, centers)
values, indexes = tf.nn.top_k(-dist, k=2, sorted=True)
top2 = -values
d_1 = top2[:, 0]
d_2 = top2[:, 1]
row_idx = tf.range(tf.shape(labels)[0], dtype=tf.int32)
idx = tf.stack([row_idx, labels], axis=1)
d_y = tf.gather_nd(dist, idx, name='dy')
indicator = tf.cast(tf.nn.in_top_k(-dist, labels, k=1), tf.float32)
d_c = indicator * d_2 + (1 - indicator) * d_1
# 只考虑正确的,顺便加上了“软间隔”margin
loss = tf.nn.relu(d_y - d_c + margin, name='loss')
mean_loss = tf.reduce_mean(loss, name='mean_loss')
return mean_lossDistance based cross entropy loss(DCE)
这个代码看着非常舒服,距离的负数作为logits算softmax loss
def dce_loss(features, labels, centers, t, weights=None):
dist = distance(features, centers)
logits = -dist / t
mean_loss = softmax_loss(logits, labels, weights)
return mean_lossGeneralized CPL with prototype loss(GCPL)
上述三个loss加一些正则,MCE/MCL/DCE + λPL
# prototype loss (PL)
def pl_loss(features, labels, centers):
batch_num = tf.cast(tf.shape(features)[0], tf.float32)
batch_centers = tf.gather(centers, labels)
dis = features - batch_centers
return tf.div(tf.nn.l2_loss(dis), batch_num)然后这片文章就没什么了
顺便放下结果:
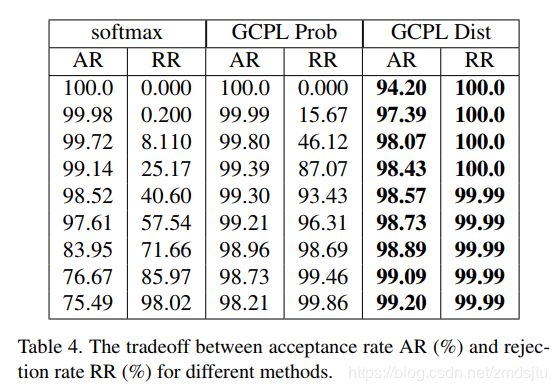
- 泛化能力更佳,相同的数据量下,GCPL表现更佳(如果足够其实差别不大,233)

- 新增类别可视化,中间那一坨为新增类别(还是分得很开的,可以用来作为unknown)
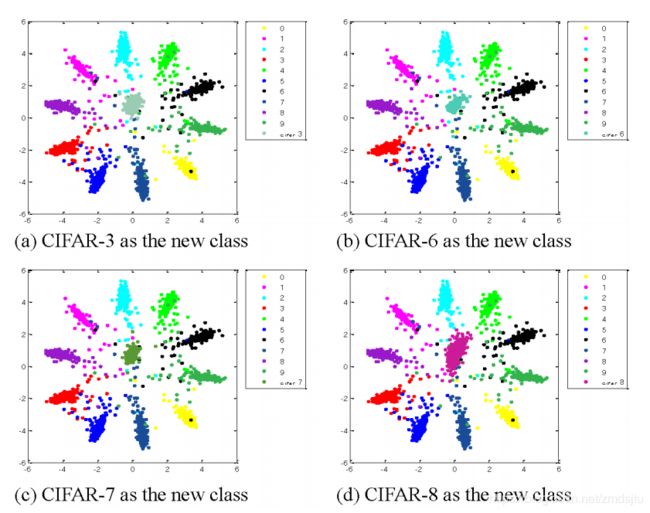
- out-of-domain判断的能力,也即鉴别unknown的能力(mnint/CIFAR-10对比,其实差异蛮大的,233),至少可以吊打softmax
Reference:
1.论文:地址
2.源码: 地址
3.论文解读:地址