GPU加速实战——混合精度训练
作者:小鹿鹿鹿,夕小瑶

其实小夕的内心是拒绝的,就一台破Xp,再优化能快到哪里去呀T^T
燃鹅
小夕找了一份开源代码,结果刚开始跑小夕就震惊了!什么鬼?训练速度怎么这么快?出bug了吧????
一毛一样的模型、超参数和硬件环境,竟然可以获得2.X倍的加速。
关键的关键,这不是一个特例,在各类网络训练问题上都提速明显,遍地开花~~~ 
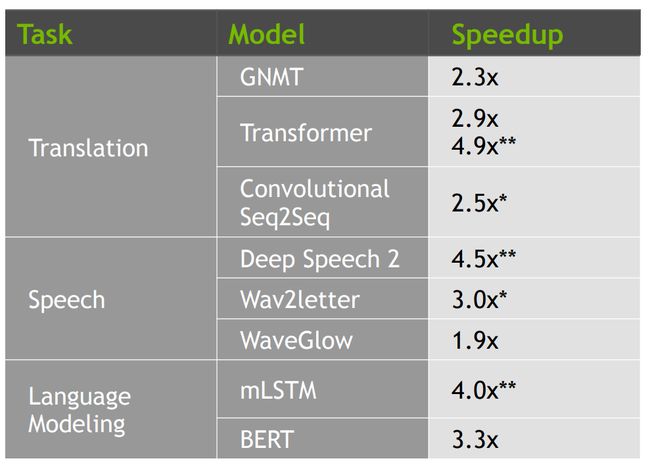
混合精度训练
一切还要从2018年ICLR的一篇论文说起。。。
《MIXED PRECISION TRAINING》
这篇论文是百度&Nvidia研究院一起发表的,结合N卡底层计算优化,提出了一种灰常有效的神经网络训练加速方法,不仅是预训练,在全民finetune BERT的今天变得异常有用哇。而且小夕调研了一下,发现不仅百度的paddle框架支持混合精度训练,在Tensorflow和Pytorch中也有相应的实现。下面我们先来讲讲理论,后面再分析混合精度训练在三大深度学习框架中的打开方式。
理论原理
训练过神经网络的小伙伴都知道,神经网络的参数和中间结果绝大部分都是单精度浮点数(即float32)存储和计算的,当网络变得超级大时,降低浮点数精度,比如使用半精度浮点数,显然是提高计算速度,降低存储开销的一个很直接的办法。然而副作用也很显然,如果我们直接降低浮点数的精度直观上必然导致模型训练精度的损失。但是呢,天外有天,这篇文章用了三种机制有效地防止了模型的精度损失。待小夕一一说来o(* ̄▽ ̄*)ブ
权重备份(master weights)
我们知道半精度浮点数(float16)在计算机中的表示分为1bit的符号位,5bits的指数位和10bits的尾数位,所以它能表示的最小的正数即2^-24(也就是精度到此为止了)。当神经网络中的梯度灰常小的时候,网络训练过程中每一步的迭代(灰常小的梯度 ✖ 也黑小的learning rate)会变得更小,小到float16精度无法表示的时候,相应的梯度就无法得到更新。
论文统计了一下在Mandarin数据集上训练DeepSpeech 2模型时产生过的梯度,发现在未乘以learning rate之前,就有接近5%的梯度直接悲剧的变成0(精度比2^-24还要高的梯度会直接变成0),造成重大的损失呀/(ㄒoㄒ)/~~

还有更难的,假设迭代量逃过一劫准备奉献自己的时候。。。由于网络中的权重往往远大于我们要更新的量,当迭代量小于Float16当前区间内能表示的最小间隔的时候,更新也会失败(哭瞎┭┮﹏┭┮我怎么这么难鸭)
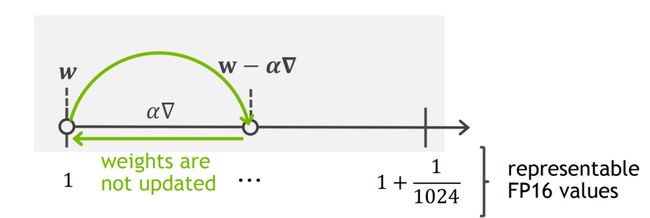
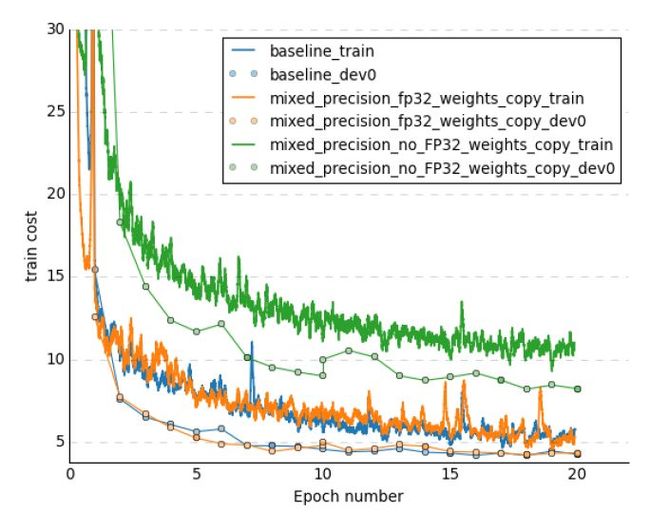
所以怎么办呢?作者这里提出了一个非常simple but effective的方法,就是前向传播和梯度计算都用float16,但是存储网络参数的梯度时要用float32!这样就可以一定程度上的解决上面说的两个问题啦~~~
我们来看一下训练曲线,蓝色的线是正常的float32精度训练曲线,橙色的线是使用float32存储网络参数的learning curve,绿色滴是不使用float32存储参数的曲线,两者一比就相形见绌啦。
损失放缩(loss scaling)
有了上面的master weights已经可以足够高精度的训练很多网络啦,但是有点强迫症的小夕来说怎么还是觉得有点不对呀o((⊙﹏⊙))o.
虽然使用float32来存储梯度,确实不会丢失精度了,但是计算过程中出现的指数位小于 -24 的梯度不还是会丢失的嘛!相当于用漏水的筛子从河边往村里运水,为了多存点水,村民们把储水的碗换成了大缸,燃鹅筛子依然是漏的哇,在路上的时候水就已经漏的木有了。。
于是loss scaling方法来了。首先作者统计了一下训练过程中激活函数梯度的分布情况,由于网络中的梯度往往都非常小,导致在使用FP16的时候右边有大量的范围是没有使用的。这种情况下, 我们可以通过放大loss来把整个梯度右移,减少因为精度随时变为0的梯度。
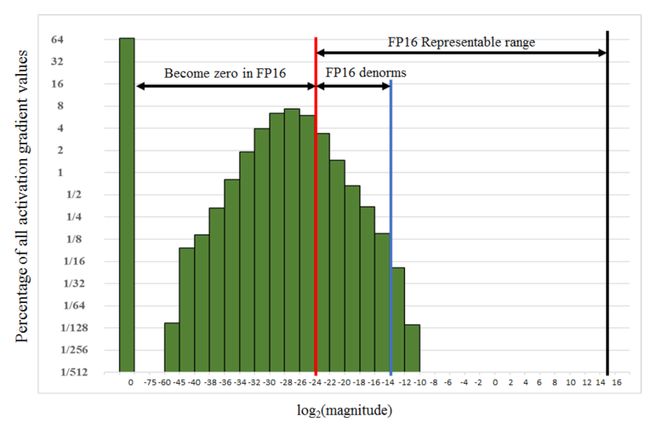
那么问题来了,怎么合理的放大loss呢?一个最简单的方法是常数缩放,把loss一股脑统一放大S倍。float16能表示的最大正数是2^15*(1+1-2^-10)=65504,我们可以统计网络中的梯度,计算出一个常数S,使得最大的梯度不超过float16能表示的最大整数即可。
当然啦,还有更加智能的动态调整(automatic scaling) o(* ̄▽ ̄*)ブ
我们先初始化一个很大的S,如果梯度溢出,我们就把S缩小为原来的二分之一;如果在很多次迭代中梯度都没有溢出,我们也可以尝试把S放大两倍。以此类推,实现动态的loss scaling。
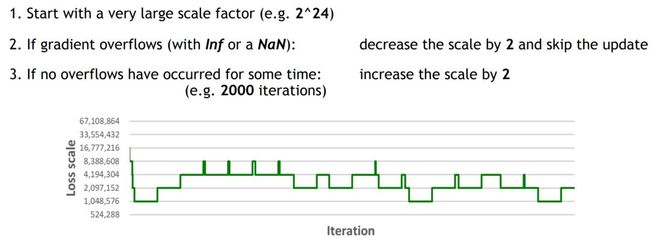
运算精度(precison of ops)
精益求精再进一步,神经网络中的运算主要可以分为四大类,混合精度训练把一些有更高精度要求的运算,在计算过程中使用float32,存储的时候再转换为float16。
-
matrix multiplication: linear, matmul, bmm, conv
-
pointwise: relu, sigmoid, tanh, exp, log
-
reductions: batch norm, layer norm, sum, softmax
-
loss functions: cross entropy, l2 loss, weight decay
像矩阵乘法和绝大多数pointwise的计算可以直接使用float16来计算并存储,而reductions、loss function和一些pointwise(如exp,log,pow等函数值远大于变量的函数)需要更加精细的处理,所以在计算中使用用float32,再将结果转换为float16来存储。
总结陈词
混合精度训练做到了在前向和后向计算过程中均使用半精度浮点数,并且没有像之前的一些工作一样还引入额外超参,而且重要的是,实现非常简单却能带来非常显著的收益,在显存half以及速度double的情况下保持模型的精度,简直不能再厉害啦。
三大深度学习框架的打开方式
看完了硬核技术细节之后,我们赶紧来看看代码实现吧!如此强大的混合精度训练的代码实现不要太简单了吧
Pytorch
导入Automatic Mixed Precision (AMP),不要998不要288,只需3行无痛使用!
from apex import ampmodel, optimizer = amp.initialize(model, optimizer, opt_level="O1") # 这里是“欧一”,不是“零一”with amp.scale_loss(loss, optimizer) as scaled_loss:scaled_loss.backward()
来看个例子,将上面三行按照正确的位置插入到自己原来的代码中就可以实现酷炫的半精度训练啦!
import torchfrom apex import ampmodel = ...optimizer = ...#包装model和optimizermodel, optimizer = amp.initialize(model, optimizer, opt_level="O1")for data, label in data_iter:out = model(data)loss = criterion(out, label)optimizer.zero_grad()#loss scaling,代替loss.backward()with amp.scaled_loss(loss, optimizer) as scaled_loss:scaled_loss.backward()optimizer.step()
Tensorflow
一句话实现混合精度训练之修改环境变量,在python脚本中设置环境变量
os.environ['TF_ENABLE_AUTO_MIXED_PRECISION'] = '1'除此之外,也可以用类似pytorch的方式来包装optimizer。
Graph-based示例
opt = tf.train.AdamOptimizer()#add a lineopt = tf.train.experimental.enable_mixed_precision_graph_rewrite(opt,loss_scale='dynamic')train_op = opt.miminize(loss)
Keras-based示例
opt = tf.keras.optimizers.Adam()#add a lineopt = tf.train.experimental.enable_mixed_precision_graph_rewrite(opt,loss_scale='dynamic')model.compile(loss=loss, optimizer=opt)model.fit(...)
PaddlePaddle
一句话实现混合精度训练之添加config(惊呆毕竟混合精度训练是百度家提出的,内部早就熟练应用了叭)
--use_fp16=true举个栗子,基于BERT finetune XNLI任务时,只需在执行时设置use_fp16为true即可。
export FLAGS_sync_nccl_allreduce=0export FLAGS_eager_delete_tensor_gb=1export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7BERT_BASE_PATH="chinese_L-12_H-768_A-12"TASK_NAME='XNLI'DATA_PATH=/path/to/xnli/data/CKPT_PATH=/path/to/save/checkpoints/python -u run_classifier.py --task_name ${TASK_NAME} \--use_fp16=true \ #!!!!!!add a line--use_cuda true \--do_train true \--do_val true \--do_test true \--batch_size 32 \--in_tokens false \--init_pretraining_params ${BERT_BASE_PATH}/params \--data_dir ${DATA_PATH} \--vocab_path ${BERT_BASE_PATH}/vocab.txt \--checkpoints ${CKPT_PATH} \--save_steps 1000 \--weight_decay 0.01 \--warmup_proportion 0.1 \--validation_steps 100 \--epoch 3 \--max_seq_len 128 \--bert_config_path ${BERT_BASE_PATH}/bert_config.json \--learning_rate 5e-5 \--skip_steps 10 \--num_iteration_per_drop_scope 10 \--verbose true
更多以及后续内容,请各位看官移步微信公众号「夕小瑶的卖萌屋」 ,会有更加精彩的内容等着大家哦 ヘ|・∀・|ノ*~●
