
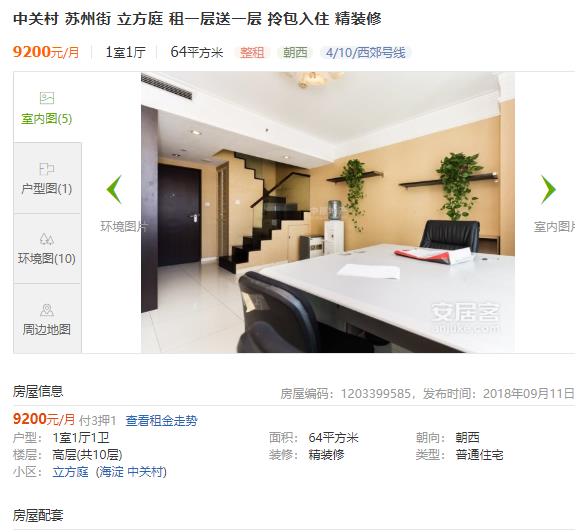
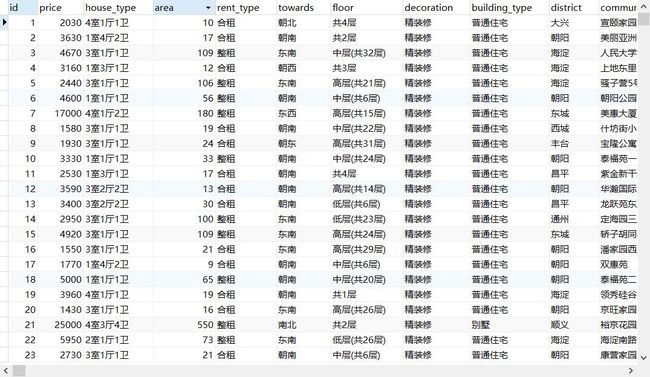
从图上可以看到每一条出租房屋信息,主要包括:价格,户型,面积,楼层,装修,类型,所在区,小区,出租方式,朝向,邻近的地铁线。
开始上代码:
创建一个scrapy项目(scrapy startproject Anjuke_Spider)。会生成如下图3的目录。然后,在“spiders”文件夹下创建一个py文档,这里命名为“anjuke_zufang”。然后加入“run”文件。最后的目录如图4.
下面,跳过scrapy的"settings"设置,直接写主要代码。
引入所要用的库:
import scrapy
from scrapy.spiders import Rule
from scrapy.linkextractors import LinkExtractor
from Anjuke_Spider.items import AnjukeSpiderItem
然后创建一个爬虫的类:
class AnjukeSpider(scrapy.spiders.CrawlSpider): name = 'anjuke'
写起始的url:
start_urls = ['https://bj.zu.anjuke.com/']
接下来就是本文的核心,LinkExtractor,首先得根据抓包数据和网页进行分析,并不是所有的网页爬取都能使用LinkExtractor。首先得分析需要爬取的网页url。
首先分析不同的目录页url,点击页面下的页码项,去不同目录页,发现其url如下:
https://bj.zu.anjuke.com/?from=navigation 第1页
https://bj.zu.anjuke.com/fangyuan/p2/ 第2页
https://bj.zu.anjuke.com/fangyuan/p3/ 第3页
https://bj.zu.anjuke.com/fangyuan/p4/ 第4页
https://bj.zu.anjuke.com/fangyuan/p5/ 第5页
其中试着将第1页的url改为“https://bj.zu.anjuke.com/fangyuan/p1/”,访问这个url,发现返回的正是第1页的页面。 这样便发现房源的目录页面有这样的规律,他们url大致一样,改变的仅是最后的页码编号,这可以用如下的代码匹配房源目录页面的url:
https://bj.zu.anjuke.com/fangyuan/p\d+/
在得到房源目录页面后,点击房源进入房源页面,获取所要的信息,如图5,我们点击网页获取我们需要的信息,可以发现其网址类似于图6所示,形如:
https://bj.zu.anjuke.com/fangyuan/1203399585?from=Filter_1&hfilter=filterlist
https://bj.zu.anjuke.com/fangyuan/1202089286?from=Filter_2&hfilter=filterlist
https://bj.zu.anjuke.com/fangyuan/1200258936?from=Filter_3&hfilter=filterlist
可以发现不同的网页,在url上主要是url末尾的10位数字不同。url的?号后的内容一般是jquery,有些内容可以去掉这样来简化url。把问号后的内容去掉发现其仍能够访问房源的页面,这样便能找到房源页面的url的规律,可以用如下的代码匹配房源的url:
https://bj.zu.anjuke.com/fangyuan/\d{10}


接下开始使用“Rule”和“LinkExtractor”:
rules = (
Rule(LinkExtractor(allow='fangyuan/p\d+/'), follow=True),
Rule(LinkExtractor(allow='https://bj.zu.anjuke.com/fangyuan/\d{10}'), callback='parse_item'),
)
第一行“Rule(LinkExtractor(allow='fangyuan/p\d+/'), follow=True)”,用“allow”指定要访问的网址,因为前面已经指定start_urls,所以这里将“follow”指定为“True”,表示在start_urls后面添加,合起来即“https://bj.zu.anjuke.com/fangyuan/p\d+/”,这里访问的是房源的目录页。
第二行“Rule(LinkExtractor(allow='https://bj.zu.anjuke.com/fangyuan/\d{10}'), callback='parse_item')”是在第一行访问房源页的基础上,访问每一个房源页,“callback”指定下面对数据进行处理的方法。
接下来就该定义一个方法,方法名应该与“callback”指定的方法名相同。
def parse_item(self, response):
price = int(response.xpath("//ul[@class='house-info-zufang cf']/li[1]/span[1]/em/text()").extract_first())
house_type = response.xpath("//ul[@class='house-info-zufang cf']/li[2]/span[2]/text()").extract_first()
area = int(response.xpath("//ul[@class='house-info-zufang cf']/li[3]/span[2]/text()").extract_first().replace('平方米',''))
rent_type = response.xpath("//ul[@class='title-label cf']/li[1]/text()").extract_first()
towards = response.xpath("//ul[@class='house-info-zufang cf']/li[4]/span[2]/text()").extract_first()
floor = response.xpath("//ul[@class='house-info-zufang cf']/li[5]/span[2]/text()").extract_first()
decoration = response.xpath("//ul[@class='house-info-zufang cf']/li[6]/span[2]/text()").extract_first()
building_type = response.xpath("//ul[@class='house-info-zufang cf']/li[7]/span[2]/text()").extract_first()
district = response.xpath("//ul[@class='house-info-zufang cf']/li[8]/a[2]/text()").extract_first()
station = response.xpath("//ul[@class='house-info-zufang cf']/li[8]/a[3]/text()").extract_first()
community = response.xpath("//ul[@class='house-info-zufang cf']/li[8]/a[1]/text()").extract_first()
subway_line = response.xpath("//ul[@class='title-label cf']/li[3]/text()").extract_first()
方法parse_item的response返回的便是房源页面的HTML数据,因为没有json数据,所以只能从HTML数据匹配所需要的数据。这里用的Xpath,获取price(租金)、house_type(户型)、area(面积)、rent_type(出租方式)、towards(朝向)、floor(楼层)、decoration(装修)、building_type(楼类型)、district(所在区)、station(临近地铁站)、community(社区、小区)、subway_line(地铁线路)。
最后贴上anjuke_zufang.py的完整代码:
import scrapy
from scrapy.spiders import Rule
from scrapy.linkextractors import LinkExtractor
from Anjuke_Spider.items import AnjukeSpiderItem
class AnjukeSpider(scrapy.spiders.CrawlSpider):
name = 'anjuke'
start_urls = ['https://bj.zu.anjuke.com/']
rules = (
Rule(LinkExtractor(allow='fangyuan/p\d+/'), follow=True),
Rule(LinkExtractor(allow='https://bj.zu.anjuke.com/fangyuan/\d{10}'), callback='parse_item'),
)
def parse_item(self, response):
price = int(response.xpath("//ul[@class='house-info-zufang cf']/li[1]/span[1]/em/text()").extract_first())
house_type = response.xpath("//ul[@class='house-info-zufang cf']/li[2]/span[2]/text()").extract_first()
area = int(response.xpath("//ul[@class='house-info-zufang cf']/li[3]/span[2]/text()").extract_first().replace('平方米',''))
rent_type = response.xpath("//ul[@class='title-label cf']/li[1]/text()").extract_first()
towards = response.xpath("//ul[@class='house-info-zufang cf']/li[4]/span[2]/text()").extract_first()
floor = response.xpath("//ul[@class='house-info-zufang cf']/li[5]/span[2]/text()").extract_first()
decoration = response.xpath("//ul[@class='house-info-zufang cf']/li[6]/span[2]/text()").extract_first()
building_type = response.xpath("//ul[@class='house-info-zufang cf']/li[7]/span[2]/text()").extract_first()
district = response.xpath("//ul[@class='house-info-zufang cf']/li[8]/a[2]/text()").extract_first()
station = response.xpath("//ul[@class='house-info-zufang cf']/li[8]/a[3]/text()").extract_first()
community = response.xpath("//ul[@class='house-info-zufang cf']/li[8]/a[1]/text()").extract_first()
subway_line = response.xpath("//ul[@class='title-label cf']/li[3]/text()").extract_first()
item = AnjukeSpiderItem()
item['price'] = price
item['house_type'] = house_type
item['area'] = area
item['rent_type'] = rent_type
item['towards'] = towards
item['floor'] = floor
item['decoration'] = decoration
item['building_type'] = building_type
item['district'] = district
item['station'] = station
item['community'] = community
item['subway_line'] = subway_line
yield item
对于scrapy项目,除了要写爬虫的主程序,还需要配置settings,items,pipelines,middleware等文件。还需要修改run文件。对于items文件修改如下:
import scrapy
class AnjukeSpiderItem(scrapy.Item):
price = scrapy.Field()
house_type = scrapy.Field()
area = scrapy.Field()
rent_type = scrapy.Field()
towards = scrapy.Field()
floor = scrapy.Field()
decoration = scrapy.Field()
building_type = scrapy.Field()
district = scrapy.Field()
community = scrapy.Field()
station = scrapy.Field()
subway_line = scrapy.Field()
本项目需要在settings中设置headers,如下:
DEFAULT_REQUEST_HEADERS = {
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
run文件如下:
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
# 获取settings.py模块的设置
from Anjuke_Spider.spiders.anjuke_zufang import AnjukeSpider
settings = get_project_settings()
process = CrawlerProcess(settings=settings)
# 可以添加多个spider
process.crawl(AnjukeSpider)
# 启动爬虫,会阻塞,直到爬取完成
process.start()
其次还需要在pipelines中将结果写入一个文件中,本项目将结果写入了mysql数据库,这里不再详细介绍。
其中要注意的是,在爬取的过程中,会触发网站的反爬机制,但是在设置一个随机的时间间隔便能继续进行,在settings中设置:
DOWNLOAD_DELAY = 1.5