以太坊RLP编码原理
概要
This is a serialization method for encoding arbitrarily structured binary data (byte arrays).
这是以太坊黄皮书中对RLP编码的定义,以太坊中的所有对象都会使用RLP编码序列化为字节数组。
RLP把数据分成两类,一类是所有的字节数组的集合(e.g. hello world),一类是列表(e.g. [“hello”,“world”,[[]]]) ,其他数据类型可以根据自己的规则转换成这两类,比如struct可以转换成列表。
编码定义
- 字节数组集合
其中||x||指x的长度,BE(x)指x去掉了前导0的大端表示,.x字符串拼接,相当于concat(x)

公式解析
- 如果是单个字节,并且值在(0,128]之间,编码就是其本身。
比如字符'x'的编码是[120] - 如果x长度小于56,编码是x然后前缀加上(128+x的长度)
hello world的编码是 [139 104 101 108 108 111 32 119 111 114 108 100],其中[104 101 108 108 111 32 119 111 114 108 100]是hello world的byte数组,139是128+11(hello world的字节数组长度) - 如果不是上面2种情况,编码是x然后前缀加上(183+x的长度的大端表示的长度然后连接x的长度的大端表示)
现在对This is a serialization method for encoding arbitrarily structured binary data (byte arrays)这句话进行编码
x的长度是92,大端表示是0x5c,大端表示的长度是1
所以x的编码是[184 92 84 104 105 .....]
- tree-like结构集合
s(x)为集合中所有元素的RLP编码后的字符串连接
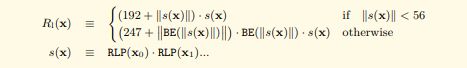
公式解析
- 如果s(x)的长度在(0,56]之间,编码是s(x)然后前缀加上(192+s(x)的长度)
我们来看下["hello","world"]的编码。
根据列2,hello的编码是[133 104 101 108 108 111],world的编码是[133 119 111 114 108 100]
s(x)的长度是12,前缀是192+12=204
所以编码是[204 133 104 101 108 108 111 133 119 111 114 108 100] - 如果s(x)的长度在(56,], 编码是s(x)然后前缀加上247+s(x)的长度的大端表示的长度,然后连接s(x)的长度的大端表示
看下["This is a serialization method for encoding arbitrarily structured binary data (byte arrays)","This is a serialization method for encoding arbitrarily structured binary data (byte arrays)"]的编码
根据例3, This is a serialization method for encoding arbitrarily structured binary data (byte arrays)的编码是[184 92 84 104 105 115 32 105 115 32 97 32 115 101 114 105 97 108 105 122 97 116 105 111 110 32 109 101 116 104 111 100 32 102 111 114 32 101 110 99 111 100 105 110 103 32 97 114 98 105 116 114 97 114 105 108 121 32 115 116 114 117 99 116 117 114 101 100 32 98 105 110 97 114 121 32 100 97 116 97 32 40 98 121 116 101 32 97 114 114 97 121 115 41] 长度是94, s(x)长度是188 188的大端表示是oxbc,长度是1,247+1=248,所以编码是[248,188,182 92...115 41]
RLP源码解析
到这里大家应该对RLP的原理都比较了解下,现在一起看下RLP的源码。
RLP源码在rlp文件夹下面,主要包括3个文件,typecache.go(可以根据类型找到编码器和解码器).encode.go(编码器),decode.go(解码器)
typecache.go
type typeinfo struct {
decoder
writer
}
typeInfo里面声明了编码器和解码器
func genTypeInfo(typ reflect.Type, tags tags) (info *typeinfo, err error) {
info = new(typeinfo)
if info.decoder, err = makeDecoder(typ, tags); err != nil {
return nil, err
}
if info.writer, err = makeWriter(typ, tags); err != nil {
return nil, err
}
return info, nil
}
这段很简单,就是通过类型生产typeinfo。
func structFields(typ reflect.Type) (fields []field, err error) {
for i := 0; i < typ.NumField(); i++ {
if f := typ.Field(i); f.PkgPath == "" { // exported
tags, err := parseStructTag(typ, i)
if err != nil {
return nil, err
}
if tags.ignored {
continue
}
info, err := cachedTypeInfo1(f.Type, tags)
if err != nil {
return nil, err
}
fields = append(fields, field{i, info})
}
}
return fields, nil
}
编码每个字段,生成typeinfo
encode.go
func makeWriter(typ reflect.Type, ts tags) (writer, error) {
kind := typ.Kind()
switch {
case typ == rawValueType:
return writeRawValue, nil
case typ.Implements(encoderInterface):
return writeEncoder, nil
case kind != reflect.Ptr && reflect.PtrTo(typ).Implements(encoderInterface):
return writeEncoderNoPtr, nil
case kind == reflect.Interface:
return writeInterface, nil
case typ.AssignableTo(reflect.PtrTo(bigInt)):
return writeBigIntPtr, nil
case typ.AssignableTo(bigInt):
return writeBigIntNoPtr, nil
case isUint(kind):
return writeUint, nil
case kind == reflect.Bool:
return writeBool, nil
case kind == reflect.String:
return writeString, nil
case kind == reflect.Slice && isByte(typ.Elem()):
return writeBytes, nil
case kind == reflect.Array && isByte(typ.Elem()):
return writeByteArray, nil
case kind == reflect.Slice || kind == reflect.Array:
return makeSliceWriter(typ, ts)
case kind == reflect.Struct:
return makeStructWriter(typ)
case kind == reflect.Ptr:
return makePtrWriter(typ)
default:
return nil, fmt.Errorf("rlp: type %v is not RLP-serializable", typ)
}
}
根据类型create编码器,writeBool,writeString之类的都很简单,都是按照黄皮书来的,我们就仔细看下makeStructWriter
func makeStructWriter(typ reflect.Type) (writer, error) {
fields, err := structFields(typ)
if err != nil {
return nil, err
}
writer := func(val reflect.Value, w *encbuf) error {
lh := w.list()
for _, f := range fields {
if err := f.info.writer(val.Field(f.index), w); err != nil {
return err
}
}
w.listEnd(lh)
return nil
}
return writer, nil
}
这个方法首先调用了structField,获取struct每个字段的fieldInfo, 然后遍历调用每个字段的编码器。
decode.go
解码器的流程和编码器的类似。
func makeStructDecoder(typ reflect.Type) (decoder, error) {
fields, err := structFields(typ)
if err != nil {
return nil, err
}
dec := func(s *Stream, val reflect.Value) (err error) {
if _, err := s.List(); err != nil {
return wrapStreamError(err, typ)
}
for _, f := range fields {
err := f.info.decoder(s, val.Field(f.index))
if err == EOL {
return &decodeError{msg: "too few elements", typ: typ}
} else if err != nil {
return addErrorContext(err, "."+typ.Field(f.index).Name)
}
}
return wrapStreamError(s.ListEnd(), typ)
}
return dec, nil
}
strcut的decode也是遍历所有的字段,然后分别调用每个字段的解码器。