1-2-1-函数式编程
为什么要学习函数式编程
- 函数式编程是随着React的流行受到越来越多的关注
- Vue 3也开始拥抱函数式编程
- 函数式编程可以抛弃this
- 打包过程中可以更好的利用tree shaking过滤无用代码
- 方便测试,方便并行处理
- 有很多库可以帮助我们进行函数式开发:lodash、undersore、ramda
什么是函数式编程
函数式编程(Functional Programming,FP),FP是编程范式之一,我们常说的编程范式还有面向对象编程、面向过程编程。
-
面向对象编程的思维方式:把现实世界中的事物抽象成程序世界中的类和对象,通过封装、继承和多态来演示事物事件的联系
-
函数式编程的思维方式:把现实世界的事物和事件之间的联系抽象到程序世界(对运算过程进行抽象)
-
程序的本质:根据输入通过某种运算获得相应的输出,程序开发过程中会涉及很多输入和输出的函数。
-
x -> f(联系、映射) -> y, y = f(x)
-
函数式编程中的函数指的不是程序中的函数(方法),而是数学中的函数即映射关系,例如:y = sin(x),x和y的关系
-
相同的输入始终要得到相同的输出(纯函数)
-
函数式编程用来描述数据(函数)之间的映射
-
前置知识
- 函数是一等公民
- 高阶函数
- 闭包
函数是一等公民
MDN First-class Function
- 函数可以存储在变量中
- 函数作为参数
- 函数作为返回值
在Javascript中函数就是一个普通的对象(可以通过new Function()),我们可以把函数存储到变量/数组中,它还可以作为另一个函数的参数或者返回值,甚至我们可以在程序运行的时候,通过new Function('alert(1)')来构造一个新的函数。
- 把函数赋值给变量
// 把函数赋值给变量
let fn = function () {
console.log('hello First-class Function')
}
// 一个示例
const BlogConstroller = {
index (posts) { return Views.index(posts) },
show (posts) { return Views.show(posts) },
create (attrs) { return Db.create(attrs) },
update (posts, attrs) { return Db.update(posts, attrs) },
destroy (posts) { return Db.destroy(posts) },
}
// 优化
const BlogConstroller = {
index: Views.index,
show: Views.show,
create: Db.create,
update: Db.update,
destroy: Db.destroy,
}
高阶函数
-
高阶函数(Higher-order function)
- 可以把函数作为参数传递给另一个函数
- 可以把函数作为另一个函数的返回结果
-
函数作为参数
// forEach
function forEach(Array, fn){
for(let i = 0; i < Array.length; i++){
fn(Array[i])
}
}
const arr = [1, 2, 3, 4, 5, 6, 7, 8]
forEach(arr, function(item){
console.log(item)
})
// filter
function filter(Array, fn){
let arr = []
for(let i = 0; i < Array.length; i++){
if(fn(Array[i])){
arr.push(Array[i])
}
}
return arr
}
const arr = [1, 2, 3, 4, 5, 6, 7, 8]
let result = filter(arr, function(item){
return item % 2 === 0
})
console.log(result)
- 函数作为返回值
function makeFn () {
const msg = "woailili"
return function(){
console.log(msg)
}
}
// const fn = makeFn()
// fn()
makeFn()()
//once
function once (fn) {
let done = false
return function () {
if(!done){
done = true
return fn.apply(this, arguments)
}
}
}
const pay = once(function (money) {
console.log(`支付${money}元`)
})
pay(1)
pay(1)
pay(1)
// once函数是一个高阶函数,它接收一个函数作为参数,作用就是返回一个函数,返回的这个函数不管执行几次,它只会调用一次这个参数函数。
// 一句话说就是,生成一个只会执行一次的函数
高阶函数的意思
函数式编程的核心思想,函数式编程的核心是将运算过程抽象成函数,然后可以在任何使用的情况下复用这些函数。调用的时候可以不去关心它实现的细节,只需要了解自己的目标就可以。
- 抽象可以帮我们屏蔽细节,只需要关注目标
- 高阶函数是用来抽象通用的问题,代码简洁
- 灵活的函数调用
想前面封装的forEach函数,它的作用就是循环一个数组,并按照传入的函数取处理循环的每一个数组元素。我们在调用的时候不需要去关系循环的细节,只需要关系想要对数组进行怎样的处理就可以了。
常用的高阶函数
- forEach
- map
- filter
- every
- some
- find/findIndex
- reduce
- sort
- ……
map
// map
const map = (Array, fn) => {
let arr = []
for(let value of Array){
arr.push(fn(value))
}
return arr
}
const arr = [1, 2, 3, 4, 5, 6, 7, 8]
let result = map(arr, item => item * 2)
console.log(result)
// every
const every = (Array, fn) => {
for(let value of Array){
if(!fn(value)){
return false
}
}
return true
}
const arr = [1, 2, 3, 4, 5, 6, 7, 8]
let result = every(arr, item => item > 2)
console.log(result)
// some
const some = (Array, fn) => {
for(let value of Array){
if(fn(value)){
return true
}
}
return false
}
const arr = [1, 2, 3, 4, 5, 6, 7, 8]
let result = some(arr, item => item > 100)
console.log(result)
闭包
-
闭包(Closure):函数和其周围的状态(词法环境)的引用捆绑在一起形成闭包。
-
可以在另一个作用域中调用一个函数(1)的内部函数(2)并访问到该函数(1)的作用域中的成员。
-
闭包的本质:函数在执行的时候会放到一个执行栈上,当函数执行完之后从执行栈上移除,但是堆上的作用域成员因为被外部引用不能释放,因此当内部函数调用的时候依然可以访问到外部函数的成员。
-
function makeFn () {
const msg = "woailili"
return function(){
console.log(msg)
}
}
// const fn = makeFn()
// fn()
makeFn()()
//once
function once (fn) {
let done = false
return function () {
if(!done){
done = true
return fn.apply(this, arguments)
}
}
}
const pay = once(function (money) {
console.log(`支付${money}元`)
})
pay(1)
pay(1)
pay(1)
闭包案例
const makePower = function (power) {
return function(number){
return Math.pow(number, power)
}
}
// 求平方的函数
const power2 = makePower(2)
// 求立方的函数
const power3 = makePower(3)
console.log(power2(2))
console.log(power3(2))
纯函数
纯函数概念
-
纯函数:相同的输入永远得到相同的输出,而且没有任何可观察的副作用。
-
纯函数就类似于数学中的函数(用来描述输入和输出之间的关系),y=f(x)。
-
lodash是一个纯函数的功能库,提供了对数组、数字、对象、字符串、函数等操作的一些方法。
-
数组的 slice 和 splice 分别是纯函数和不纯的函数。
-
slice 返回数组中的指定部分,不会改变原数组。
-
splice 对数组进行操作返回该数组,会改变原数组。
-
-
函数式编程不会保留计算中间的结果,所以变量是不可变的(无状态的)
-
我们可以把一个函数的执行结果交给另一个函数去处理。
-
Loadsh
lodash上手
https://www.lodashjs.com/
yarn init -y
yarn add lodash --save
const _ = require('lodash')
const arr = [1, 'a', 3, 'b', 5, 'c']
console.log(_.first(arr))
console.log(_.last(arr))
console.log(_.toUpper(_.last(arr)))
console.log(_.reverse(arr))
const result = _.each(arr, (item, index) => {
console.log(index, item)
})
console.log(result)
console.log(_.includes(arr, 1))
console.log(_.findIndex(arr, item => {
return item === 1
}))
纯函数的优势
-
可缓存(可以提高函数的行能)
- 因为纯函数对于相同的输入始终又相同的结果,所以可以把纯函数的结果缓存起来
const _ = require('lodash')
function getArea (r) {
console.log(r)
return Math.PI * r * r
}
const getAreaWithMemory = _.memoize(getArea)
console.log(getAreaWithMemory(2))
console.log(getAreaWithMemory(2))
console.log(getAreaWithMemory(2))
//模拟实现memoize纯函数
/**
* 分析memoize函数接收一个函数,并返回一个新的函数,
* 这个新的函数可以将传进来的函数的结果缓存起来。
*/
const memoize = function (fn) {
let cache = {}
return function () {
const key = JSON.stringify(arguments)
cache[key] = cache[key] || fn.apply(fn, arguments)
return cache[key]
}
}
-
可测试
- 纯函数可以让测试更加方便
因为单元测试就是在断言程序的执行结果,而纯函数始终都有输入和输出,所以所有的纯函数都是可以测试的函数。
-
并行处理
- 在多线程环境下并行操作共享的内存数据很可能会出现意外情况。纯函数下不需要访问共享的内存数据,所以在并行环境下可以任意运行纯含数(Web Work)
因为纯函数是一个封闭的空间,它只依赖于自己的参数,不需要访问共享的内存数据,所以在并行的情况下依然可以任意的运行纯函数。
ES6以后新增的webwork可以开启多个线程。但是在js多数的情况下还是以单线程为主。
副作用
- 纯函数对于相同的输入始终都会有相同的输出,而且没有任何的可观察的副作用。
// 不纯的
let mini = 18
function checkAge (age) {
return age >= mini
}
//纯的(有硬编码,可以通过函数柯里化解决)
function checkAge (age) {
let mini = 18
return age >= mini
}
副作用让一个函数变得不纯(如上例),纯函数的根据相同的输入返回相同的输出,如果函数依赖于外部的状态,就无法保证输出相同,就会带来副作用。
副作用来源:
- 配置文件
- 数据库
- 获取用户的输入
- ……
比如说,在获取用户输入的时候可能带来跨站脚本攻击。
所有的外部交互都有可能带来副作用,副作用也使得方法通用性下降不适合扩展和可重用性,同时副作用会给程序中带来安全隐患,给程序带来不确定性,但是副作用不可能完全禁止,但要尽可能控制他们在可控范围内发生。
柯里化(Haskell Brooks Curry)
- 使用柯里化解决函数硬编码的问题
// 普通函数
// function checkAge (mini, age) {
// return age >= mini
// }
// console.log(checkAge(18, 20))
// console.log(checkAge(18, 22))
// console.log(checkAge(18, 25))
// console.log(checkAge(18, 26))
// mini 为18可能会经常用到,我已我们就可以使用函数式编程封装一下这个映射过程的一部分
// 函数柯里化
// const checkAge = mini => {
// return function (age) {
// return age >= mini
// }
// }
// 箭头函数最简版
const checkAge = mini => (age => age >= mini)
const checkAgeHas18 = checkAge(18)
console.log(checkAgeHas18(20))
console.log(checkAgeHas18(22))
console.log(checkAgeHas18(25))
柯里化:
- 当一个函数有多个参数的时候先传递一部分参数调用它(这部分参数以后永远不变)。
- 然后返回一个新的函数接收剩余的参数,返回结果。
Lodash中的柯里化
_.curry(func)
-
功能:创建一个函数,该函数接收一个或多个func的参数,如果func所需要的参数都被提供,则执行func并返回执行的结果。否则继续返回该函数并等待接收剩余的参数。
-
参数:需要柯里化的函数
-
返回值:柯里化后的函数
const _ = require('lodash')
// lodash函数柯里化方法
const getSum = (a, b, c) => a+b+c
const curried = _.curry(getSum)
console.log(curried(1, 2, 3))
console.log(curried(1, 2)(3))
console.log(curried(1)(2)(3))
lodash 案例
const _ = require('lodash)
// 柯里化案例
const match = _.curry((reg, string) => string.match(reg))
const hasSpace = match(/\s+/g)
const haveNumber = match(/\d+/g)
// console.log(hasSpace("hello world")) // [ ' ' ]
// console.log(haveNumber("hello world1")) // [ '1' ]
// 案例值filter
const filter = _.curry((fn, array) => array.filter(fn))
const findSpace = filter(hasSpace)
console.log(filter(hasSpace, ['John Connor', 'John_Donne']))
console.log(filter(findSpace, ['John Connor', 'John_Donne']))
console.log(findSpace(['John Connor', 'John_Donne']))
柯里化的实现原理
// 柯里化的实现原理
function getSum (a, b, c) {
return a + b + c
}
const curriedGetSum = curry(getSum)
console.log(curriedGetSum(1, 2, 3))
console.log(curriedGetSum(1)(2, 3))
console.log(curriedGetSum(1, 2)(3))
function curry (fn) {
return function curriedFunc (...args) {
if(args.length < fn.length){
// return function (...args1) {
// return curriedFunc(...[...args,...args1])
// }
return function () {
return curriedFunc (...args.concat(Array.from(arguments)))
}
}
return fn(...args)
}
}
柯里化总结
- 柯里化可以让我们给一个函数传递较少的参数得到一个已经记住了某些固定参数的新函数
- 这是一种对函数参数的"缓存"
- 让函数变得更灵活,让函数的力度更小
函数组合
-
纯函数和柯里化很容易写出洋葱代码 h(g(f(x)))
- 获取数组的最后一个元素转换成大写字母, .toUpper(.first(_.reverse(array)))
-
函数组合可以让我们把细粒度的函数重新组合生成一个新的函数。
管道
下面这张图表示程序中使用函数处理数据的过程,给fn函数输入一个参数a,返回结果b。可以想想a数据通过一个管道得到一个b数据。
![]()
当fn函数比较复杂的时候,我们可以把函数fn拆分成多个小函数,此时多了中间运算过程中产生的m和n。
下面这张图可以想象成把fn这个管道拆分成了3个管道f1,f2,f3,数据a通过管道f3得到结果m,m通过管道f2得到结果n,n通过管道f1得到结果b。
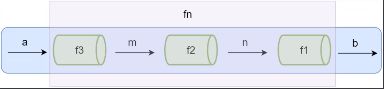
组合函数会忽略小管道处理数据的过程中产生的中间值,只关心开始的输入和最终的输出。
fn compose(f1, f2, f3)
b = fn(a)
函数组合
-
函数组合(compose):如果一个函数要经过多个函数处理才能得到最终值,这个时候可以把中间过程的函数合并成一个函数。
- 函数就像是数据的管道,函数组合就是把这些管道连接起来,让数据穿过多个管道形成最终结果。
- 函数组合默认是从右到左执行。
// 函数组合演示
function compose (f, g) {
return function (value) {
return f(g(value))
}
}
const composeFn = compose(_.first, _.reverse)
console.log(composeFn([1, 2, 3, 4])
)
lodash中的组合函数
- lodash 中的组合函数 flow() 或者 flowRight() ,他们都可以组合多个函数。
- flow() 是从左到右执行。
- flowRight() 是从右到左执行,使用的更多一些。
//lodash的组合函数
const _ = require("lodash")
const reverse = array => array.reverse()
const first = array => array[0]
const toUpper = string => string.toUpperCase()
const composeFn = _.flowRight(toUpper, first, reverse)
console.log(composeFn(['one', 'two', 'three']))
lodash组合函数原理
const reverse = array => array.reverse()
const first = array => array[0]
const toUpper = string => string.toUpperCase()
// const compose = function (...args) {
// return function (value) {
// return args.reduceRight(function (acc, fn) {
// return fn(acc)
// }, value)
// }
// }
// 箭头函数的写法
const compose = (...args) => value => args.reduceRight((acc, fn) => fn(acc), value)
const composeFn = compose(toUpper, first, reverse)
console.log(composeFn(['one', 'two', 'three']))
函数组合-结合律
- 函数组合要满足结合律(associativity):我们既可以把 g 和 h 组合,还可以把 f 和 g 组合,结果都是一样的。
// 结合律(associativity)
let f = compose(f, g, h)
let associative = compose(compose(f, g), h) == compose(f, compose(g, h))
// true
函数组合——练习
// NEVER SAY DIE ---> never-say-die
const _ = require('lodash')
let str = 'NEVER SAY DIE'
// // 先柯里化(函数组合只能组合一元函数)
// const split = splitChar => str => _.split(str, splitChar)
// const splitStrWidthSpace = split(' ')
// const join = joinChar => array => _.join(array, joinChar)
// const joinArrayWithHyphen = join('-')
// // 函数组合
// const formattingStr = _.flowRight(_.toLower, joinArrayWithHyphen, splitStrWidthSpace)
// console.log(formattingStr(str))
// 老师的思路(姜还是老的辣一点点)
const split = _.curry((splitChar, str) => _.split(str, splitChar))
const join = _.curry((joinChar, array) => _.join(array, joinChar))
const formattingStr = _.flowRight(_.toLower, join('-'), split(' '))
console.log(formattingStr(str))
函数组合——调试
函数组合不会对外暴露计算的中间值,在外面并不能打印中间值来检查在处理数据的那一步出了问题。
可以定义一个打印中间值的一元函数,将这个函数加到组合函数中,打印我们想要的组合函数中间值。
const log = middleValue => {
console.log(middleValue)
return middleValue
}
为了清楚的知道打印的中间值是函数组合中的哪一步的中间值,可以给 log 函数添加一个标签参数,调用的时候给打印的中间值添加一个标签。
const trace = _.curry((tag, middleValue) => {
console.log(tag, middleValue)
return middleValue
})
Lodash中的FP模块
前面的练习中可以看到,在使用 lodash 函数进行函数组合处理的时候,很多情况都需要对lodash的二次封装,就很烦。
- lodash/fp
lodash 的 fp 模块提供了实用的对函数式编程友好的方法
// NEVER SAY DIE ---> never-say-die
const _ = require('lodash')
const fp = require('lodash/fp')
const formattingStr = _.flowRight(_.toLower, fp.join('-'), fp.split(' '))
let str = 'NEVER SAY DIE'
console.log(formattingStr(str))
lodash 和 lodash/fp模块中的map的区别
const _ = require('lodash')
console.log(_.map(['23', '8', '10'], parseInt)) // [ 23, NaN, 2 ]
原因:
-
map:
Creates an array of values by running each element in collection through iteratee. The iteratee is invoked with three arguments: (value, index|key, collection). -
parseInt:
function parseInt(s: string, radix?: number): number
Converts a string to an integer.
@params — A string to convert into a number.
@paramradix — A value between 2 and 36 that specifies the base of the number in numString. If this argument is not supplied, strings with a prefix of ‘0x’ are considered hexadecimal. All other strings are considered decimal.
const fp = require('lodash/fp')
console.log(fp.map(parseInt, ['23', '8', '10'])) // [ 23, 8, 10 ]
原因:
- map:
Point Free
首先,Point Free是一种编程风格。
**Point Free:**我们可以把数据处理的过程定义成与数据无关的合成运算,不需要用到代表数据的那个参数,只要把简单的运算步骤合成到一起,在使用这个模式之前我们需要定义一些辅助的基本函数。
- 不需要指明处理的数据
- 只需要合成运算过程
- 需要定义一些辅助的基本运算函数
_.flowRight(_.toLower, fp.join('-'), fp.split(' '))
函数式编程的核心,把运算过程抽象成函数。Point Free模式就是把抽象出来的函数合成一个新的函数,合成的过程不涉及具体数据,只关心运算过程,也是一个抽象的过程。
// Hello World ----> hello_world
const fp = require('lodash/fp')
const f = fp.flowRight(fp.replace(/\s+/g, '_'), fp.toLower)
console.log(f('Hello World'))
在合成 f 的时候并不需要关系传入的具体数据是什么,只需要关心运算过程,然后把每一步的运算过程组合起来就可以了。比如,第一步将字符串转换成小写,然后将字符串中的空格替换成下划线。
练习案例
// 把一个字符串中的首字母提取并转换成大写,使用.作为分隔符
// world wild web ==>W.W.W
const fp = require('lodash/fp')
// const f = fp.flowRight(fp.toUpper, fp.join('.'), fp.map(fp.first), fp.split(' '))
const f = fp.flowRight(fp.join('.'), fp.map(fp.flowRight(fp.toUpper, fp.first)), fp.split(' '))
console.log(f('world wild web'))