新浪体育——篮球足球的直播和战报爬取
新浪体育——篮球足球的直播和战报爬取
用到的包的介绍

以上是基于python3.6.5的新浪体育直播间篮球足球的直播和战报爬取所引用到的全部内外部包,下面将会挑几个与爬虫息息相关的包进行介绍。
1.lxml
Python 标准库中自带了 xml 模块,但是性能不够好,而且缺乏一些人性化的 API,相比之下,第三方库 lxml 是用 Cython 实现的,而且增加了很多实用的功能,可谓爬虫处理网页数据的一件利器。lxml 大部分功能都存在 lxml.etree`中。
xml 是一个树形结构,lxml 使用etree._Element和 etree._ElementTree来分别代表树中的节点和树。etree._Element 是一个设计很精妙的结构,可以把他当做一个对象访问当前节点自身的文本节点,可以把他当做一个数组,元素就是他的子节点,可以把它当做一个字典,从而遍历他的属性。
2.BeautifulSoup*
官方解释:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
- Tag
- NavigableString
- BeautifulSoup
- Comment
Tag: HTML中的一个个标签
<title>The Dormouse's storytitle>
<a class="sister" href="http://example.com/elsie" id="link1">Elsiea>HTML 标签加上里面包括的内容就是 Tag,它有两个重要的属性,是 name 和 attrs。
单独获取某个属性:
print (soup.p['class'])
#['title']NavigableString: 标签内部的文字
print (soup.p.get_text())BeautifulSoup : 表示的是一个文档的全部内容
大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag,我们可以分别获取它的类型
Comment: 一个特殊类型的NavigableString对象,其实输出的内容仍然不包括注释符号
3.Selenium*
一种自动化测试工具。它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏览器,如果你在这些浏览器里面安装一个 Selenium 的插件,那么便可以方便地实现Web界面的测试。换句话说 Selenium 支持这些浏览器驱动。
声明浏览器对象:
chromedriver = 'C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe'
driver=webdriver.Chrome(chromedriver)用selenium做自动化,有时候会遇到需要模拟鼠标操作才能进行的情况,比如单击、双击、点击鼠标右键、拖拽等等。而selenium给我们提供了一个类来处理这类事件——ActionChains
我在写代码的过程中参考了以下这篇博客:
https://blog.csdn.net/huilan_same/article/details/52305176
(selenium之 玩转鼠标键盘操作(ActionChains))
click(on_element=None) ——单击鼠标左键
click_and_hold(on_element=None) ——点击鼠标左键,不松开
context_click(on_element=None) ——点击鼠标右键
double_click(on_element=None) ——双击鼠标左键
drag_and_drop(source, target) ——拖拽到某个元素然后松开
drag_and_drop_by_offset(source, xoffset, yoffset) ——拖拽到某个坐标然后松开
key_down(value, element=None) ——按下某个键盘上的键
key_up(value, element=None) ——松开某个键
move_by_offset(xoffset, yoffset) ——鼠标从当前位置移动到某个坐标
move_to_element(to_element) ——鼠标移动到某个元素
move_to_element_with_offset(to_element, xoffset, yoffset) ——移动到距某个元素(左上角坐标)多少距离的位置
perform() ——执行链中的所有动作
release(on_element=None) ——在某个元素位置松开鼠标左键
send_keys(*keys_to_send) ——发送某个键到当前焦点的元素
send_keys_to_element(element, *keys_to_send) ——发送某个键到指定元素
Selenium还可以很方便地进行元素定位,可以参考以下博客:
https://blog.csdn.net/jojoy_tester/article/details/53453888
(selenium WebDriver定位元素学习总结)
Selenium中元素定位共有八种
id
name
className
tagName
linkText
partialLinkText
xpath
cssSelector
详细可以参考:https://blog.csdn.net/kaka1121/article/details/51850881
4.其他
re——正则表达式工具
xlrd、xlwt——python中操作exel表格的工具
json——将 JavaScript 对象中表示的一组数据转换为字符串
…
新浪直播间网页结构介绍
首先进入新浪体育的官网首页,如下图所示,在最上面一排有一个直播,里面有我们需要爬取的内容:

页面整洁,层次分明的新浪体育直播间:


打开这个界面我们直接跳到了当前的日期,同时我们可以看到在网页的右面有日期的选择器,最早可以选至2012年1月1日,可供数据的时间跨度可以说是非常大了,对比腾讯直播间的2015年,加上该网页构造较为简单,这是我们选择新浪体育直播间的主要原因。
建议使用Google的chrome浏览器打开该界面,因为chrome有非常丰富的开发者工具。现在让我们来看看当前网页的源码和构造。

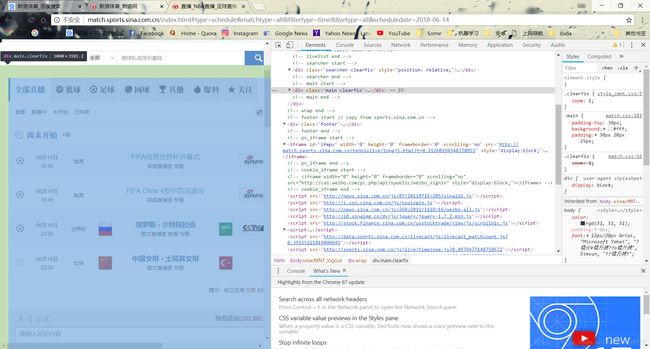
网页中部的主要内容都在class为‘main clearfix’的一个大div标签内。其主要内容分为三个部分:
默认选择全部直播的toptab板块
罗列了当天所有比赛的topcont板块
下方评论comment板块
打开其中我们需要的第二个内容板块,再接着打开其中的比赛时间表的字段,依次打开main_data和cont_figure_list字段找到了我们需要的比赛的列表,其中次序为奇偶的比赛因为背景颜色不同class并不相同。




每一场比赛在一个div结构下,于是接下来我们可以看一下每个比赛条目下具体的代码结构,并找出我们需要的部分和爬取方法了。

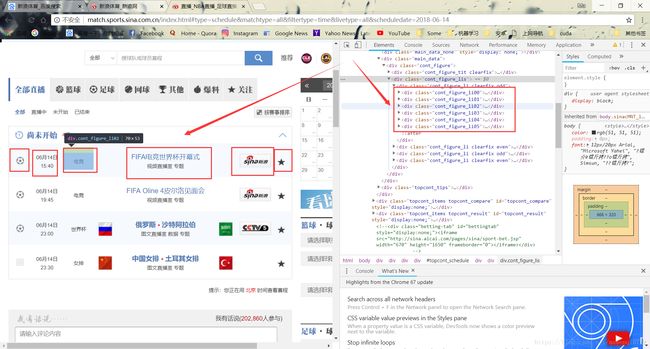
我们可以看到每个新闻目录下对应着在网页上横着罗列开的6个项目,这6个项目所代表的的部分我在图片中用红框标识了出来,开始的时候我决定用最左边图片的超链接的类来分别我所需要的篮球或足球体育类别,但是进一步点开观察每个比赛的直播和战报数据的时候发现cba的这两样数据很乱,于是选择了只用nba,而cba和nba最左边的标识是一样的,因此我选泽了直接判断第三个项目的文字是否是NBA来决定是否进入该比赛爬取数据。

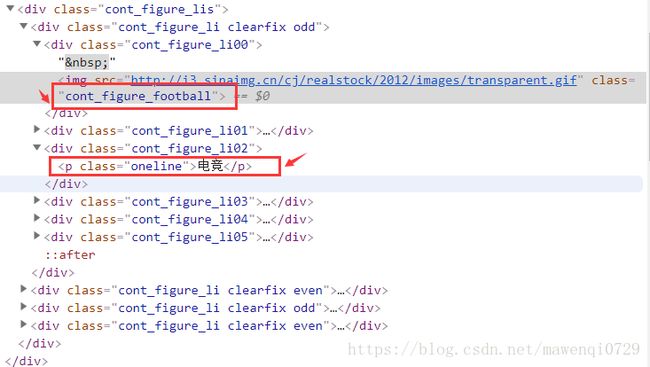
于是就非常方便容易地判断出了该比赛的类别,但是我们注意到,电竞比赛前面也用到了足球图标,而且足球不只有世界杯欧洲杯等等而已,而是类别非常多,这就是为什么我们不能用图标类别,也不能直接判断类别标签是否等于某个值来确定这个比赛是否是足球。


我们可以发现网页中的图片,队名等几乎都是超链接,(可以说是非常用心非常便利了),其中我标出来的两部分,一个的超链接能够让我们进入这个比赛的细节,一个能够直接跳到战报界面,是我们需要用到的。
接下去是点击比分进入的比赛细节:
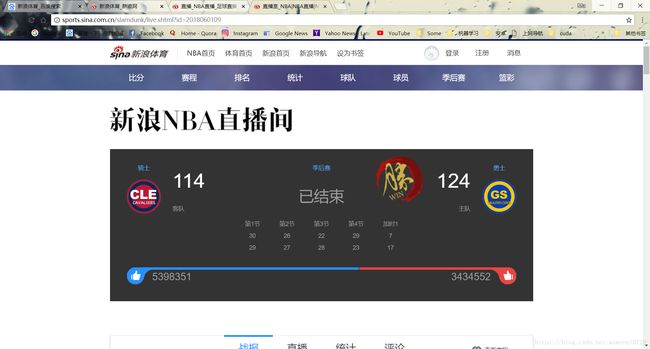



我们可以看到最上面是整场比赛的比分和概况,接下里默认是战报板块,基本上是一个标题一个图片配上一篇战报的格式。内部分为‘战报’,‘直播’,‘统计’,‘评论’四个板块。该板块由头部(
)中的四个超链接控制转换tab。

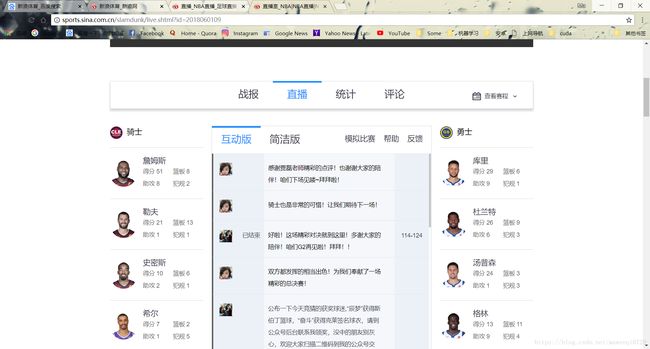
直播界面对用户也十分友好,两边能够看到两队首发的全部数据情况,中间是按照时间顺序排列的场上情况的直播,除了中场休息等这样的信息以外大多是某队的一个球员跟上某个动作。这些列表式的直播数据使我们需要的,下方还有球队数据的对比等我们暂时不爬取。


我们可以看到一大堆的直播数据每个由一个列表项表示,在标签属性里已经注明了,这条表述归属的队号和球员号,但是形式非常奇怪,有点像乱码,再打开看一下它们的内部结构:

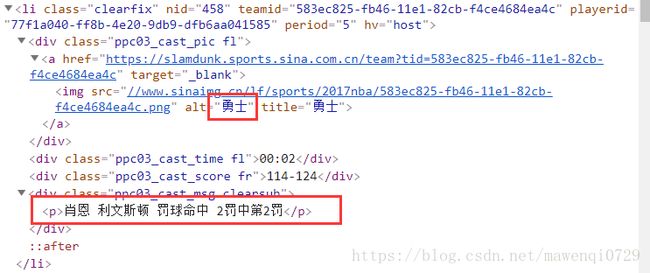
打开之后我们找到了我们可以爬取的队名和直播文字。而战报的文字当然直接在
标签内了。

同时我也发现,当我们改变直播大厅的日期的时候,网址只有scheduledate参数改变,如2018年6月12号的,网址为
http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=all&scheduledate=2018-06-12
然后我改变最后的日期参数就可以跳转到不同天的全部比赛,给我省了不少的时间。
以上就是新浪体育直播大厅结合源码有关页面的全部探索,于是就有了一个爬数据的基本思路。
代码与爬数据的步骤
1.准备
首先定义出一个webdriver,调用这个webdriver来打开模仿浏览器的行为访问数据。定义两个全局变量,page_list和cangoin,分别表示爬取数据的标号以及是否能够进入比赛细节页面爬取战报,我发现2014年7月以前的比赛只能进入单独的战报界面爬取战报,因为单场比赛界面里面的战报全部是空的,em。。可能是新浪后台的问题。选取2012年6月这一天的url方便进行测试。
chromedriver = 'C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe'
driver=webdriver.Chrome(chromedriver)
#driver=webdriver.Chrome()
global page_list
global cangoin
cangoin=0
page_return=1
driver.implicitly_wait(2)
url='http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=2012-06-06'2.挑出所有为NBA的比赛
首先用driver进入我们需要爬取数据的网页,定义出BeautifulSoup,然后按照刚才我找到的标识比赛类型的标签一层层向下找,用到了soup.find('标签名', 属性=值) 和soup.find_all('标签名', 属性=值) 的方法,其中第二个方法返回的是一个列表。为了做测试,我把所有不是NBA的比赛都输出在了控制台里,如果发现了对应的NBA比赛,就获取进入search方法进行战报和直播的爬取,如果是里面不能爬取战报的这类比赛,就要在该页面点击进入战报超链接的单独网页,我为了这种情况写了一个getzb的方法。所以isNBA的代码如下:
def isNBA(url):
driver.get(url)
#driver.get(url)
soup = BeautifulSoup(driver.page_source, 'lxml')
div_m = soup.find('div', class_='main_data')
div_c = div_m.find('div', class_='cont_figure')
div_l = div_c.find('div', class_='cont_figure_lis')
div = div_l.find_all('div', recursive=False)
for d in div:
dd = d.find_all('div', recursive=False)[2]
dp = dd.find('p')
if dp.get_text()=='NBA':
dzb = d.find_all('div', recursive=False)[3]
dfl = dzb.find('div', class_='cont_figure_li03_m')
span = dfl.find('span', class_='cRed')
sa = span.find('a')
print(sa['href'])
url_into = sa['href']
#print(21321)
print(url_into)
#print(213)
search(url_into)
print(cangoin)
if not cangoin:
p = dfl.find('p', recursive=False)
a = p.find('a', text='战报')
print (a['href'])
url_zb = a['href']
getzb(url_zb)
else:
print ('不在')
print (dp.get_text())3.进入单场比赛search战报直播
在进入单场比赛的界面后,默认就是战报板块,所以如果我设置的cangoin变量是1的话,就可以直接在当前界面爬取战报了,这里我设置了一个getnews的方法将爬数据和存储战报的这一块提出了search方法,接下来点击直播超链接,这里找到这个元素,因为没有id什么的,所以是直接复制那个元素的xpath找过去的,非常好用。点击后试图爬取直播却发现仅有
标签,但这个标签似乎是空的,里面所有的
- 标签都不见了,为此我debug了很久,具体见如下代码中好长一段的注释,最后发现直播里面这一大堆的数据是通过JavaScript动态加载过去的,于是我利用chrome开发者工具里的network找到了这个js文件,爬取后对它进行解码。并且发现每个js网址的网址中只有id部分不同,而这个id可以从当前网址中截取到,于是就非常容易获得这个js网站了,传给dejson()函数就好。



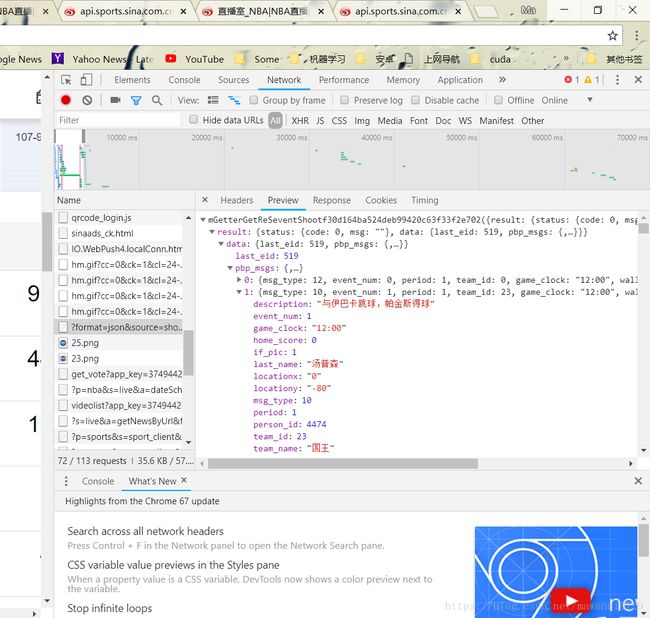
search的代码如下:
def search(url_into):
print(1)
print(url_into)
driver.get(url_into)
driver.get(url_into)
global page_return
global real_name
global real_time
soup = BeautifulSoup(driver.page_source, 'lxml')
if cangoin:
getnews(url_into)
tab_zb = driver.find_element_by_xpath('/html/body/section[2]/div/div[1]/div[1]/a[4]').click()#'a[tab()="live"]'
ActionChains(driver).click(tab_zb)
#body = soup.find('body', ppccont='news')
#print (body['class'])
span = soup.find('span', class_='qq_spanoption')
as_ = span.find('a', class_='qq_login_h')
print (as_['href'])
id = as_['href'][-10:]
href='http://api.sports.sina.com.cn/pbp/?format=json&source=web&withhref=1&mid='+id+'&pid=&eid=0&dpc=1'
de_json(href)
#print (soup.prettify())
a = soup.find('a', tab='live')
print(a['class'])
# div = soup.find('div', class_='ppc03_cast_cont', stype='auto')
# print (div['scrolling'])
# if(div!=None):
# #div = soup.find('div', class_='ppc03_cast_tabs clearfix')
# ol = div.find('ol', recursive=False)
# print (ol['class'])
# div_d = div.find('div', recursive=False)
# print (div_d['class'])
# guest = div_d.find('div', class_ ="ppc03_cast_select bselector01 fr")
# select = guest.find('select')
# option = select.find('option')
# print (select.name)
# #guest = div_d.find('a', tab = 'guest', recursive=True)
# print (guest.get_text())
# li = ol.find_all('li', recursive=False)
# li = ol.find_all(re.compile("^li"))
# divs = ol.find_all('div', class_ = 'ppc03_cast_score fr')
# #print (divs[0].get_text())
# #print (ol.descendants[0])
# for l in li:
# div1 = l.find('div', recursive=False)#, class_='ppc03_cast_time f1' c
# print ('哈哈哈哈哈')
# print (l['nid'],'hhhhhhhhhh')
# real_name.append(div1.get_text())
# print (div1)
# print('hehehe')
# print (real_name)
# else:
# return
# page_return=14.在单独的战报界面里爬取战报getzb
单独的战报界面只需要找到包含大段文字的部分就非常简单爬取文字了,因为战报的文字都非常规整地罗列在
标签内,然后定义一个文件夹路径,这里用到了page_list来作为战报的序号及文件名。用open()函数打开文件。
def getzb(url):
global page_list
driver.get(url)
soup = BeautifulSoup(driver.page_source, 'lxml')
db = soup.find('div', class_='blkContainerSblk')
dbody = db.find('div', id='artibody')
ps = dbody.find_all('p', recursive=False)
page_list = page_list - 1
write_path = 'D:\其他\战报\\' + str(page_list-1) + '.txt'
fo = open(write_path, "w", encoding='utf-8')
for p in ps:
pt = p.get_text()
print(pt)
fo.write(pt.replace(' ', ''))
fo.write('\n')
fo.close()5.解析json爬取直播
刚才我找到的json网站打开其实是这样的:


在解码json的网站把这段json解码后看到了它真正的结构:
 这里写图片描述
这里写图片描述
用json.load(json文件) 的方法可以解码json,让他变成右边的树状结构,然后我们可以用索引的方式找到需要的信息,这里我保存了五条可能用到的信息,分别是:队名,当前比赛时间,该条比赛描述,当前主队得分,客队得分。调用xlwt打开exel写入信息。
代码如下:
def de_json(url):
driver.get(url)
soup = BeautifulSoup(driver.page_source, 'lxml')
print (soup.prettify())
pre = soup.find('pre')
json_t = pre.get_text()
json_string = json.loads(json_t)
#print (json_string)
workbook = xlwt.Workbook() # excle打开
sheet1 = workbook.add_sheet('sheet1', cell_overwrite_ok=True)
write_path = 'D:\其他\直播\\'+str(page_list-1)+'.xls'
#page_list = page_list-1
page_in_list = 0
for i in json_string['result']['data']['pbp_msgs']:
#ele = json_string[i]
#print (i.key)
print (i)
print (json_string['result']['data']['pbp_msgs'][i]['team_name'])
print (json_string['result']['data']['pbp_msgs'][i]['game_clock'])
des = json_string['result']['data']['pbp_msgs'][i]['description']
txt = re.sub(r'<.*?>','',des)
#print(re.match(r'>[\u4e00-\u9fa5]*<', des))
#if re.match(r'>[\u4e00-\u9fa5]*<', des):
#txt = re.match(r'>[\u4e00-\u9fa5]*<', des)[1:-1] + re.match(r'a>[\u4e00-\u9fa5]*',des)[2:]
#print('Yesyesyes')
#else:
#txt = des
print (txt)
print (json_string['result']['data']['pbp_msgs'][i]['home_score'])
print (json_string['result']['data']['pbp_msgs'][i]['visitor_score'])
#print (i['game_clock'])
#print ('\n')
sheet1.write(page_in_list, 0, json_string['result']['data']['pbp_msgs'][i]['team_name'])
sheet1.write(page_in_list, 1, json_string['result']['data']['pbp_msgs'][i]['game_clock'])
sheet1.write(page_in_list, 2, txt)
sheet1.write(page_in_list, 3, json_string['result']['data']['pbp_msgs'][i]['home_score'])
sheet1.write(page_in_list, 4, json_string['result']['data']['pbp_msgs'][i]['visitor_score'])
page_in_list = page_in_list + 1
workbook.save(write_path)
page_in_list = page_in_list + 1
#json=soup.prettify()
#json_string = json.load(json)
#for i in [0:565]6.在单场比赛界面爬战报getnews()
与getzb()类似,代码如下:
def getnews(url):
driver.get(url)
soup = BeautifulSoup(driver.page_source, 'lxml')
divc = soup.find('div', class_='barticle_content')
ps = divc.find_all('p', recursive=False)
write_path = 'D:\其他\战报\\'+str(page_list)+'.txt'
fo = open(write_path, "w", encoding='utf-8')
for p in ps:
pt = p.get_text()
print (pt)
fo.write(pt.replace(' ', ''))
fo.write('\n')
fo.close()7.调整时间
表示出所有的日期放入网址爬取不同天的数据。
for i in years[0:]:
if (i == '2012' ):
for m in mouth[5:]: # 每次出问题记得更改
if (m in ['01','03','05','07','08','10','12']):
for n in days2[:]:
print(i + '-' + m + '-' + n)
print(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
isNBA('http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
elif (m in ['02']):
for n in days4:
print(i + '-' + m + '-' + n)
isNBA(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
else:
for n in days1:
if (m=='06' and n =='02'):
continue
print(i + '-' + m + '-' + n)
print(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
isNBA(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
elif (i=='2016'):
for m in mouth[5:]: # 每次出问题记得更改
if (m in ['01','03','05','07','08','10','12']):
for n in days2[:]:
print(i + '-' + m + '-' + n)
print(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
isNBA('http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
elif (m in ['02']):
for n in days4:
print(i + '-' + m + '-' + n)
isNBA(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
else:
for n in days1:
print(i + '-' + m + '-' + n)
print(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
isNBA(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
else:
for m in mouth[0:]: # 每次出问题记得更改
if (m in ['01','03','05','07','08','10','12']):
if (i == '2014' and m=='08'):
cangoin=1
for n in days2:
print(i + '-' + m + '-' + n)
isNBA('http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
elif (m in ['02']):
for n in days3:
print(i + '-' + m + '-' + n)
isNBA(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
else:
for n in days1:
print(i + '-' + m + '-' + n)
isNBA(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
7.整体代码
最后不能忘了关闭driver
# -*- coding:utf-8 -*-
from lxml import etree
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
import time
from distutils import log
import os
import sys
from selenium.webdriver.common.action_chains import *
import re
import xlrd
import xlwt
import json
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8')
def setpl():
global page_list
page_list = 4056
global cangoin
def isNBA(url):
driver.get(url)
#driver.get(url)
soup = BeautifulSoup(driver.page_source, 'lxml')
div_m = soup.find('div', class_='main_data')
div_c = div_m.find('div', class_='cont_figure')
div_l = div_c.find('div', class_='cont_figure_lis')
div = div_l.find_all('div', recursive=False)
for d in div:
dd = d.find_all('div', recursive=False)[2]
dp = dd.find('p')
if dp.get_text()=='NBA':
dzb = d.find_all('div', recursive=False)[3]
dfl = dzb.find('div', class_='cont_figure_li03_m')
span = dfl.find('span', class_='cRed')
sa = span.find('a')
print(sa['href'])
url_into = sa['href']
#print(21321)
print(url_into)
#print(213)
search(url_into)
print(cangoin)
if not cangoin:
p = dfl.find('p', recursive=False)
a = p.find('a', text='战报')
print (a['href'])
url_zb = a['href']
getzb(url_zb)
else:
print ('不在')
print (dp.get_text())
def getzb(url):
global page_list
driver.get(url)
soup = BeautifulSoup(driver.page_source, 'lxml')
db = soup.find('div', class_='blkContainerSblk')
dbody = db.find('div', id='artibody')
ps = dbody.find_all('p', recursive=False)
page_list = page_list - 1
write_path = 'D:\其他\战报\\' + str(page_list-1) + '.txt'
fo = open(write_path, "w", encoding='utf-8')
for p in ps:
pt = p.get_text()
print(pt)
fo.write(pt.replace(' ', ''))
fo.write('\n')
fo.close()
def search(url_into):
print(1)
print(url_into)
driver.get(url_into)
driver.get(url_into)
global page_return
global real_name
global real_time
soup = BeautifulSoup(driver.page_source, 'lxml')
if cangoin:
getnews(url_into)
tab_zb = driver.find_element_by_xpath('/html/body/section[2]/div/div[1]/div[1]/a[4]').click()#'a[tab()="live"]'
ActionChains(driver).click(tab_zb)
#body = soup.find('body', ppccont='news')
#print (body['class'])
span = soup.find('span', class_='qq_spanoption')
as_ = span.find('a', class_='qq_login_h')
print (as_['href'])
id = as_['href'][-10:]
href='http://api.sports.sina.com.cn/pbp/?format=json&source=web&withhref=1&mid='+id+'&pid=&eid=0&dpc=1'
de_json(href)
#print (soup.prettify())
a = soup.find('a', tab='live')
print(a['class'])
# div = soup.find('div', class_='ppc03_cast_cont', stype='auto')
# print (div['scrolling'])
# if(div!=None):
# #div = soup.find('div', class_='ppc03_cast_tabs clearfix')
# ol = div.find('ol', recursive=False)
# print (ol['class'])
# div_d = div.find('div', recursive=False)
# print (div_d['class'])
# guest = div_d.find('div', class_ ="ppc03_cast_select bselector01 fr")
# select = guest.find('select')
# option = select.find('option')
# print (select.name)
# #guest = div_d.find('a', tab = 'guest', recursive=True)
# print (guest.get_text())
# li = ol.find_all('li', recursive=False)
# li = ol.find_all(re.compile("^li"))
# divs = ol.find_all('div', class_ = 'ppc03_cast_score fr')
# #print (divs[0].get_text())
# #print (ol.descendants[0])
# for l in li:
# div1 = l.find('div', recursive=False)#, class_='ppc03_cast_time f1' c
# print ('哈哈哈哈哈')
# print (l['nid'],'hhhhhhhhhh')
# real_name.append(div1.get_text())
# print (div1)
# print('hehehe')
# print (real_name)
# else:
# return
# page_return=1
def getnews(url):
driver.get(url)
soup = BeautifulSoup(driver.page_source, 'lxml')
divc = soup.find('div', class_='barticle_content')
ps = divc.find_all('p', recursive=False)
write_path = 'D:\其他\战报\\'+str(page_list)+'.txt'
fo = open(write_path, "w", encoding='utf-8')
for p in ps:
pt = p.get_text()
print (pt)
fo.write(pt.replace(' ', ''))
fo.write('\n')
fo.close()
def de_json(url):
driver.get(url)
soup = BeautifulSoup(driver.page_source, 'lxml')
print (soup.prettify())
pre = soup.find('pre')
json_t = pre.get_text()
json_string = json.loads(json_t)
#print (json_string)
workbook = xlwt.Workbook() # excle打开
sheet1 = workbook.add_sheet('sheet1', cell_overwrite_ok=True)
write_path = 'D:\其他\直播\\'+str(page_list-1)+'.xls'
#page_list = page_list-1
page_in_list = 0
for i in json_string['result']['data']['pbp_msgs']:
#ele = json_string[i]
#print (i.key)
print (i)
print (json_string['result']['data']['pbp_msgs'][i]['team_name'])
print (json_string['result']['data']['pbp_msgs'][i]['game_clock'])
des = json_string['result']['data']['pbp_msgs'][i]['description']
txt = re.sub(r'<.*?>','',des)
#print(re.match(r'>[\u4e00-\u9fa5]*<', des))
#if re.match(r'>[\u4e00-\u9fa5]*<', des):
#txt = re.match(r'>[\u4e00-\u9fa5]*<', des)[1:-1] + re.match(r'a>[\u4e00-\u9fa5]*',des)[2:]
#print('Yesyesyes')
#else:
#txt = des
print (txt)
print (json_string['result']['data']['pbp_msgs'][i]['home_score'])
print (json_string['result']['data']['pbp_msgs'][i]['visitor_score'])
#print (i['game_clock'])
#print ('\n')
sheet1.write(page_in_list, 0, json_string['result']['data']['pbp_msgs'][i]['team_name'])
sheet1.write(page_in_list, 1, json_string['result']['data']['pbp_msgs'][i]['game_clock'])
sheet1.write(page_in_list, 2, txt)
sheet1.write(page_in_list, 3, json_string['result']['data']['pbp_msgs'][i]['home_score'])
sheet1.write(page_in_list, 4, json_string['result']['data']['pbp_msgs'][i]['visitor_score'])
page_in_list = page_in_list + 1
workbook.save(write_path)
page_in_list = page_in_list + 1
#json=soup.prettify()
#json_string = json.load(json)
#for i in [0:565]
chromedriver = 'C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe'
driver=webdriver.Chrome(chromedriver)
#driver=webdriver.Chrome()
global page_list
global cangoin
cangoin=0
setpl()
page_return=1
real_name=[]
driver.implicitly_wait(2)
url='http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=2012-06-06'
#isNBA(url)
print('url1 is done!')
url2='http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=all&scheduledate=2014-02-10'
#isNBA(url2)
#search('http://sports.sina.com.cn/nba/live.html?id=2014101502')
i='2012'
m='06'
n='06'
#isNBA('http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(1)
years=['2012','2013','2014','2015','2016','2017']
mouth=['01','02','03','04','05','06','07','08','09','10','11','12']
days1=['01','02','03','04','05','06','07','08','09','10','11','12','13','14','15','16','17','18','19','20','21','22','23','24','25','26','27','28','29','30']
days2=['01','02','03','04','05','06','07','08','09','10','11','12','13','14','15','16','17','18','19','20','21','22','23','24','25','26','27','28','29','30','31']
days3=['01','02','03','04','05','06','07','08','09','10','11','12','13','14','15','16','17','18','19','20','21','22','23','24','25','26','27','28']
days4=['01','02','03','04','05','06','07','08','09','10','11','12','13','14','15','16','17','18','19','20','21','22','23','24','25','26','27','28','29']
'''
i='2012'
m='06'
for k in range(28):
n=days3[k]
isNBA('http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
'''
for i in years[0:]:
if (i == '2012' ):
for m in mouth[5:]: # 每次出问题记得更改
if (m in ['01','03','05','07','08','10','12']):
for n in days2[:]:
print(i + '-' + m + '-' + n)
print(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
isNBA('http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
elif (m in ['02']):
for n in days4:
print(i + '-' + m + '-' + n)
isNBA(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
else:
for n in days1:
if (m=='06' and n =='02'):
continue
print(i + '-' + m + '-' + n)
print(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
isNBA(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
elif (i=='2016'):
for m in mouth[5:]: # 每次出问题记得更改
if (m in ['01','03','05','07','08','10','12']):
for n in days2[:]:
print(i + '-' + m + '-' + n)
print(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
isNBA('http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
elif (m in ['02']):
for n in days4:
print(i + '-' + m + '-' + n)
isNBA(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
else:
for n in days1:
print(i + '-' + m + '-' + n)
print(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
isNBA(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
else:
for m in mouth[0:]: # 每次出问题记得更改
if (m in ['01','03','05','07','08','10','12']):
if (i == '2014' and m=='08'):
cangoin=1
for n in days2:
print(i + '-' + m + '-' + n)
isNBA('http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
elif (m in ['02']):
for n in days3:
print(i + '-' + m + '-' + n)
isNBA(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
else:
for n in days1:
print(i + '-' + m + '-' + n)
isNBA(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
driver.quit()
足球代码爬取
由于前面介绍过的原因,足球种类太多没法用图标的名字或者单个名字进行过滤,所以采取了排除法,并且对爬取到的战报进行了过滤,过滤掉了一些不适于做我们数据的过乱的战报。比如查找strong标签,因为带有strong标签的一篇战报中有2场或多场比赛的报道,但基本过程跟篮球差不多。
代码如下:
#encoding=utf-8
from lxml import etree
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
import time
from distutils import log
import os
import sys
from selenium.webdriver.common.action_chains import *
import re
import xlrd
import xlwt
import json
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8')
def search(url):
print(1)
print(url)
driver.get(url)
driver.get(url)
global page_return
global real_name
global real_time
soup = BeautifulSoup(driver.page_source, 'lxml')
div = soup.find('div', class_='cont_figure_lis')
if(div!=None):
div = div.find_all('div', recursive=False)
page_return=1
for i in div:
name_judge=0 #
name=[]
real_name = []
real_time=[]
#print(real_name)
index = 0
url_set = []
page_return = 1
#找到合适的战报等元素并进入
if (i.find('div')):
m = i('div')[2]
# print(m.get_text())
if (m.get_text().replace(" ", "").strip() == "" or '奥' in m.get_text() or '篮' in m.get_text()
or '排' in m.get_text() or 'NBA' in m.get_text() or '网' in m.get_text()
or 'U' in m.get_text() or '抽签' in m.get_text() or '斯' in m.get_text()
or '拳击'in m.get_text() or 'F'in m.get_text() or 'BA' in m.get_text()
or '棋' in m.get_text() or '牌' in m.get_text() or '排球' in m.get_text()
or '乒乓'in m.get_text() or '羽' in m.get_text() or '游泳' in m.get_text() or '亚俱杯' in m.get_text() or '东京赛'in m.get_text()
or '美传奇巨星' in m.get_text() or '新秀赛' in m.get_text() or '冰壶' in m.get_text() or 'NCAA' in m.get_text()):
continue
else:
m=i.find_all('div',recursive=False)[1]
for m_time in re.findall(r'[0-9]{2,2}',m.get_text()):
real_time.append(m_time)
n = i.find_all('div',recursive=False)[3]
#print(len(n.find_all('div')))
if(len(n.find_all('div',recursive=False))!=3):
continue
# 选中中间那一栏
n1 = n.find_all('div',recursive=False)[1] # 选中中间有字的一栏
if (n1.find('h4')):
#print(50)
n1_1 = n1.find('h4')
if (n1_1.find_all('a',recursive=False)):
for name_ in n1_1.find_all('a',recursive=False):
real_name.append(name_.get_text())
print(real_name)
for name_judge_ in real_name:
if ('篮' in name_judge_ or '排' in name_judge_ or '美传奇巨星' in name_judge_ or '李娜' in name_judge
or ('长春亚泰' in name_judge_ and real_time[0] == '07' and real_time[1] == '09')
or ('利物浦' in name_judge_ )
or ('广州恒大' in name_judge_ and real_time[0] == '11' and real_time[1] == '04')
or ('拜仁' in name_judge_ and real_time[0] == '12' and real_time[1] == '16')
):
name_judge=1
break
if(name_judge==1):
continue
if (n1.find('p')):
n1_2 = n1.find('p')
if (n1_2.find('a')):
for n1_2_ in n1_2('a'):
# print(10)
#print(n1_2_.get_text())
if (n1_2_.get_text() == "战报" or n1_2_.get_text() == '实录'):
print(n1_2_.get_text())
index = index + 1
print(n1_2_['href'])
url_set.append(n1_2_['href'])
else:
continue
else:
continue
else:
continue
else:
continue
if (index != 2):
#print(index)
continue
else:
get_txt(url_set[0], name)
if (page_return != 0):
get_livetxt(url_set[1])
# 方法体1:遍历网页依次找到链接地址
# 方法体1结束
# url = 'http://match.sports.sina.com.cn/livecast/1/iframe/live_log.html?168198'
# url_new = 'http://sports.sina.com.cn/j/2012-08-17/21216193280.shtml'
else:
return
def get_txt(url, name): # ,real_name)
print(2)
driver.get(url)
global page_return
soup = BeautifulSoup(driver.page_source, 'lxml')
strong_list = 0
txt_list = []
test_time_count=0
test_time=[]
if(soup.find('span',id='pub_date')):
mtime=soup.find('span',id='pub_date')
test_time.append(re.findall(r'[0-9]{2,2}\u6708',mtime.get_text())[0][0:2]) #月
test_time.append(re.findall(r'[0-9]{2,2}\u65e5',mtime.get_text())[0][0:2]) #日
if(len(test_time)==0):
if (soup.find('span', class_='article-a__time')):
mtime = soup.find('span',class_='article-a__time')
test_time.append(re.findall(r'[0-9]{2,2}\u6708', mtime.get_text())[0][0:2])
test_time.append(re.findall(r'[0-9]{2,2}\u65e5', mtime.get_text())[0][0:2])
print(test_time)
if(len(test_time)==2):
if(test_time[0]!=real_time[0]):
page_return=0
return
if(int(test_time[1])1])-1 or int(test_time[1])>int(real_time[1])+1):
page_return=0
return
if (soup.find('div', class_='BSHARE_POP blkContainerSblkCon clearfix blkContainerSblkCon_14')):
intern_deal('BSHARE_POP blkContainerSblkCon clearfix blkContainerSblkCon_14', soup, txt_list,
name, strong_list)
elif (soup.find('div', class_='blkContainerSblkCon')):
intern_deal('blkContainerSblkCon', soup, txt_list, name, strong_list)
elif (soup.find('div', class_='article-a__content')):
intern_deal('article-a__content', soup, txt_list, name, strong_list)
elif (soup.find('div',
class_='layout-equal-height__item layout-fl layout-of-hidden layout-pt-c layout-wrap-b layout-pr-a layout-br-a')):
intern_deal(
'layout-equal-height__item layout-fl layout-of-hidden layout-pt-c layout-wrap-b layout-pr-a layout-br-a',
soup, txt_list, name, strong_list)
else:
page_return = 0
def intern_deal(class1,soup,txt_list,name,strong_list):
print(3)
global page_list
tag=1#用来判断是否已经到达进球信息的标签
global page_return
start_list=0#定义有文字的p的开始位置
previous_list=0#定义一个计数器,算出第一个分钟起始位置
txt1 = soup.find('div', class_=class1)
# 如果有一个空P开头那么就计算一下,从后面第二个P开始
if txt1.find('p').get_text().replace(' ','').strip()=="":
start_list=1
print(100)
if (txt1.find('p')):
list_number=0
# print(len(txt1('p')))
if (len(txt1('p')) <= 4+start_list):
page_return=0
return
#用来判断是否是一篇合格的新闻即分钟要出现在前4个p中
newstag=0
for news_tag in txt1.find_all('p',recursive=False)[0:5]:
if(re.match(r'.*\u5206\u949f.*', news_tag.get_text()) != None):
newstag=1
if(newstag==0):
page_return=0
return
else:
for i in txt1.find_all('p',recursive=False)[1+start_list:4+start_list]:
# print(3)
if (i.find('strong')):
#print(i('strong')[0].get_text())
#print(len(i('strong')[0].get_text()))
#print(i.get_text().strip())
#print(i.get_text().strip()[0:len(i('strong')[0].get_text())])
#print(3)
if (i('strong')[0].get_text() ==i.get_text().strip()[0:len(i('strong')[0].get_text())] and not
re.match(r'.*\u5206\u949f.*',i('strong')[0].get_text())):
strong_list = strong_list + 1
# print(strong_list)
if (strong_list >= 2):
page_return=0
return
for i in txt1.find_all('p')[1+start_list:-1]:
# print(10000)
# i = i.get_text().replace(" ", "").strip()
# print(i[0:2])
# print(i.attrs)
#print(i.get_text)
if(i.attrs!={}):
# print(i.attrs)
#print(i.get_text)
continue
#print()
if (i.get_text().replace(" ", "").strip()[0:2] == "进球" or i.get_text().replace(" ", "").strip()[0:2] == '信息' ):
tag=0
continue
if(len(i.get_text().replace(" ", "").strip())<=35 and tag==0):
continue
if ((re.match(r'.*[0-9]-[\u4e00-\u9fa5].*', i.get_text()) != None #一龥
or re.match(r'.*[0-9]\'',i.get_text())!=None)and list_number>=3): # 如果匹配到了最后一个球员名单
name.append(i.get_text().replace(" ", "").strip()[0:2]) # 加入名字列表
break
list_number=list_number+1 #分钟
if ((re.match(r'.*\u5206\u949f.*', i.get_text()) == None and '开场' not in i.get_text() and '开始' not in i.get_text()) and previous_list == 0): # 如果不match分钟就跳过
continue
else:
final_txt = i.get_text()
if (i.find('a')):
len1 = len(i.find_all('a'))
# print(len1)
final_txt = final_txt.replace('[点击观看视频]', '').replace('[点击观看进球视频]', '')
for m in range(len1):
a_txt = i('a')[m].get_text()
# print(a_txt)
final_txt = final_txt.replace(a_txt, '')
else:
print()
if (i.find('script')):
len1 = len(i.find_all('script'))
# print(len1)
for m in range(len1):
a_txt = i('script')[m].get_text()
# print(a_txt)
final_txt = final_txt.replace(a_txt, '')
else:
print()
if (i.find('style')):
len1 = len(i.find_all('style'))
# print(len1)
for m in range(len1):
a_txt = i('style')[m].get_text()
# print(a_txt)
final_txt = final_txt.replace(a_txt, '')
if (i.find('span')):
len1 = len(i.find_all('span'))
# print(len1)
for m in range(len1):
a_txt = i('span')[m].get_text()
# print(a_txt)
final_txt = final_txt.replace(a_txt, '')
else:
print()
# print(3)final_txt.replace(" ", "").replace('[','').replace(']','').replace(':','').replace('【','').replace('】','').strip()
final_txt = final_txt.replace(" ", "").replace('[', '').replace(']', '').replace(':', '').replace(
'【', '').replace('】', '').replace('(', '').replace(')', '').replace('(', '').replace(')',
'').strip()
if (len(final_txt) >= 10):
txt_list.append(final_txt) # 将链接内的字符删除
previous_list = previous_list + 1
# if (name[1] not in real_name): # 判断名字是否在其中
#如果一个网页最后一个P元素为空,那么就这么做..爬倒数第二个
zuihounumber=-1
maxxunhuan=10
while(zuihounumber<0 and maxxunhuan>0):
if (re.findall(r'([\u4e00-\u9fa5].*[\u4e00-\u9fa5])', txt1('p')[zuihounumber].get_text().replace(" ", "").strip()) and not txt1('p')[zuihounumber].find('a')):
txt_list.append( (re.findall(r'([\u4e00-\u9fa5].*[\u4e00-\u9fa5])', txt1('p')[zuihounumber].get_text().replace(" ", "").strip()))[0])
zuihounumber=1
else:
zuihounumber=zuihounumber-1
maxxunhuan=maxxunhuan-1
# if (
# re.findall(r'([\u4e00-\u9fa5].*[\u4e00-\u9fa5])', txt1('p')[-1].get_text().replace(" ", "").strip())):
# txt_list.append(
# (re.findall(r'([\u4e00-\u9fa5].*[\u4e00-\u9fa5])',
# txt1('p')[-1].get_text().replace(" ", "").strip()))[
# 0])
# elif (
# re.findall(r'([\u4e00-\u9fa5].*[\u4e00-\u9fa5])', txt1('p')[-2].get_text().replace(" ", "").strip())):
# txt_list.append(
# (re.findall(r'([\u4e00-\u9fa5].*[\u4e00-\u9fa5])',
# txt1('p')[-2].get_text().replace(" ", "").strip()))[
# 0])
# elif (
# re.findall(r'([\u4e00-\u9fa5].*[\u4e00-\u9fa5])', txt1('p')[-3].get_text().replace(" ", "").strip())):
# txt_list.append(
# (re.findall(r'([\u4e00-\u9fa5].*[\u4e00-\u9fa5])',
# txt1('p')[-3].get_text().replace(" ", "").strip()))[
# 0])
# elif (
# re.findall(r'([\u4e00-\u9fa5].*[\u4e00-\u9fa5])', txt1('p')[-4].get_text().replace(" ", "").strip())):
# txt_list.append(
# (re.findall(r'([\u4e00-\u9fa5].*[\u4e00-\u9fa5])',
# txt1('p')[-4].get_text().replace(" ", "").strip()))[
# 0])
# else:
# txt_list.append(
# (re.findall(r'([\u4e00-\u9fa5].*[\u4e00-\u9fa5])',
# txt1('p')[-5].get_text().replace(" ", "").strip()))[
# 0])
# print(real_name[0])
# print(real_name[1])
print(txt_list)
#print(name[0],real_name)
if(len(name)==0):
page_return=0
return
if((name[0] not in real_name[0] and name[0] not in real_name[1])and name[0]!='女王' and name[0]!='托' and name[0]!='皇马' and name[0]!='巴萨'):
page_return=0
else:
# print(1000)
write_path = '/Users/hejie/Desktop/课外学习/数据集/新浪直播数据/战报/'+str(page_list)+'.txt'
#print(write_path)
# print(1000)
fo = open(write_path, "w",encoding='utf-8')
# print(1000)
# print(6)
# print(txt)
for i in txt_list:
# print(1000)
# print(type(i.strip()))
print(i)
fo.write(i.replace(' ', ''))
fo.write('\n')
fo.close()
# print(txt_list)
#浏览器配置
else:
page_return=0
return
def get_livetxt(url):
print(4)
print(url)
number = re.findall(r'\b[0-9][0-9]{4,7}\b',url)[0]
#print(number)
url_='http://api.sports.sina.com.cn/?p=live&s=livecast&a=livecastlog&id='+number+'&dpc=1'#真正的要访问的url
print(url_)
msg=[]
total_time=[]
score=[]
driver.get(url_)
soup = BeautifulSoup(driver.page_source, 'lxml')
#如果得到的url是一个网站
if (soup.find('pre')==None):
print("选择1")
msg,total_time,score=get_txt_direct(url)
#如果得到的url是直接一个数据库文件
else:
print('选择2')
msg,total_time,score=get_txt_indirect(url_)
global page_list
page_in_list = 0
judge=0#定义的是上半场最终访问时间
workbook=xlwt.Workbook()#excle打开
sheet1=workbook.add_sheet('sheet1',cell_overwrite_ok=True)
#txt=soup.find("tbody")
#print(txt)
list=0
#a=['上' ,'下','完']
print(1000)
write_path = '/Users/hejie/Desktop/课外学习/数据集/新浪直播数据/实录/'+str(page_list)+'.xls'
print(write_path)
# for i in txt('tr'):
# if(i('td')[2]):
# if(i('td')[2].get_text()[0] not in a ):
# continue
# elif(i('td')[2].get_text()[0]=='完' and list<2):
# #print(i('td'))
# sheet1.write(page_in_list, 0, i('td')[1].get_text().strip())
# sheet1.write(page_in_list, 1, "完赛")
# sheet1.write(page_in_list, 2, i('td')[3].get_text().strip())
# page_in_list=page_in_list+1
# list=list+1
# #print(list)
# elif(i('td')[2].get_text()[0]=='上'):#记得将下半场的时间加上上半场的时间
# sheet1.write(page_in_list, 0, i('td')[1].get_text().strip())
# sheet1.write(page_in_list, 1, re.findall(r'[0-9]+',i('td')[2].get_text())[0])
# sheet1.write(page_in_list, 2, i('td')[3].get_text().strip())
# judge=re.findall(r'[0-9]+',i('td')[2].get_text())
# page_in_list = page_in_list + 1
# else:
# sheet1.write(page_in_list, 0, i('td')[1].get_text().strip())
# sheet1.write(page_in_list, 1, str(int(re.findall(r'[0-9]+', i('td')[2].get_text())[0])+judge))
# sheet1.write(page_in_list, 2, i('td')[3].get_text().strip())
# page_in_list = page_in_list + 1
# print(i('td'))
# print(3)
for i in range(len(msg)):
sheet1.write(page_in_list, 0, msg[i])
sheet1.write(page_in_list, 1, total_time[i])
sheet1.write(page_in_list, 2, score[i])
page_in_list=page_in_list+1
workbook.save(write_path)#存放excle表
page_list=page_list+1#
#全局变量在外面赋值
def get_txt_indirect(url):#有些网站分钟没有直接显示出来
msg=[]
total_time=[]
score=[]
driver.get(url)
soup = BeautifulSoup(driver.page_source, 'lxml')
# 定义一个文本,其是直播数据
txt = soup.find('pre').get_text()
txt = re.findall(r'\[.*\]', txt)
txt = txt[0]
print(txt)
jo = json.loads(txt)
shang_end=0 #end标志标志比赛的结束最多有两个
# json_number=0
for i in jo:
if ('st' in i and i['st']!=None ):
if ('q' in i ):
if(i['q']==1):
if(':' in i['m']):
continue
msg.append(i['m'].replace('.',''))
total_time.append((i['st']//60)+1)
score.append(i['s']['s1']+'-'+i['s']['s2'])
# print(i['m'])
# #print('上半场')
# print((i['st']//60)+1)
# print(i['s']['s1']+'-'+i['s']['s2'])
shang_end=(i['st']//60)+1#标记上半场的结束时间
elif(i['q']==2):
if (':' in i['m']):
continue
msg.append(i['m'].replace('.',''))
total_time.append((i['st'] // 60) + 1+shang_end)
score.append(i['s']['s1'] + '-' + i['s']['s2'])
# print(i['m'])
# #print('下半场')
# print((i['st'] // 60) + 1+shang_end)
# print(i['s']['s1'] + '-' + i['s']['s2'])
elif(i['q']==5):
if (':' in i['m']):
continue
if (len(re.findall(r'[0-9]-[0-9]',i['m']))==1):
msg.append(i['m'].replace('.',''))
total_time.append('完赛')
score.append(i['s']['s1'] + '-' + i['s']['s2'])
# print(i['m'])
# print('完赛')
# print(i['s']['s1'] + '-' + i['s']['s2'])
# print(1000)
break
else:
continue
#print(re.findall(r'[0-9]-[0-9]',i['m']))
else:
continue
else:
continue
else:
continue
#print(1000)
return msg,total_time,score
#有些网站分钟直接显示出来了
def get_txt_direct(url):
msg = []
total_time = []
score = []
global page_list
page_in_list_=0
driver.get(url)
judge = 0
# workbook = xlwt.Workbook()
# sheet1 = workbook.add_sheet('sheet1', cell_overwrite_ok=True)
soup = BeautifulSoup(driver.page_source, 'lxml')
txt = soup.find("tbody")
# print(3)
# print(txt)
list = 0
a = ['上', '下', '完']
start_time=0#记录上半场时间
# write_path = "E:直播数据\新郎直播数据\实录\\" + str(page_list) + ".xls"
# workbook.save(write_path)
# page_list = page_list + 1 #
for i in txt('tr')[::-1]:
#print(i('th')[0])
if (i.find('th')):
#print(1000)
#print(type(i('th')[0].get_text()))
if (re.findall(r'[0-9]+',i('th')[0].get_text())):
#print(1000)
#print(page_in_list_, 0, i('td')[0].get_text().strip())
if (':' in i('td')[0].get_text()):
continue
msg.append(i('td')[0].get_text().replace('.','').strip())
if(len(re.findall(r'[0-9]+',i('th')[0].get_text()))==1):#如果时间的长度为1,就调用一个就行 ,否则两者相加
total_time.append(re.findall(r'[0-9]+',i('th')[0].get_text())[0])
# print(page_in_list_, 1, re.findall(r'[0-9]+',i('th')[0].get_text())[0])
start_time=re.findall(r'[0-9]+',i('th')[0].get_text())[0]
else:
time_=0
for time_1 in re.findall(r'[0-9]+',i('th')[0].get_text()):
time_=time_+int(time_1)
total_time.append(time_)
# print(page_in_list_, 1, time_)
start_time = re.findall(r'[0-9]+', i('th')[0].get_text())[0]
score.append(i('td')[1].get_text().strip())
#print(page_in_list_, 2, i('td')[1].get_text().strip())
page_in_list_ = page_in_list_ + 1
elif (i('th')[0].get_text().replace(' ','').strip()=="" and int(start_time)>80):
if(re.findall(r'[0-9]-[0-9]',i('td')[0].get_text())):
# print(i('td'))
if (':' in i('td')[0].get_text()):
continue
msg.append(i('td')[0].get_text().replace('.','').strip())
total_time.append("完赛")
score.append(i('td')[1].get_text().strip())
# print(page_in_list_, 0, i('td')[0].get_text().strip())
# print(page_in_list_, 1, "完赛")
# print(page_in_list_, 2, i('td')[1].get_text().strip())
page_in_list_ = page_in_list_ + 1
list = list + 1
break
else:
continue
# print(list)
else:
continue
else:
continue
#print(3)
return msg,total_time,score
service_args=[]
#设置驱动器的浏览器
driver=webdriver.Chrome( )
page_list=4564
page_return=1
real_name=[]
#获取网页地址
#方法体2:切换到新窗口中,点击新窗口中的按钮
#driver.switch_to.window(driver.window_handles[1])
'''
link=element.get_attribute('href')#获取到链接地址,然后进行跳转
driver.navigate().to(link)
driver.implicitly_wait(10)#等待10s,有可能链接还不能找到
element.click()模拟元素点击
'''
driver.implicitly_wait(2) #等待10s以便页面加载完全
#element=driver.find_element_by_xpath("/html/body/div[2]/div/div[2]/div/a[2]")#找到直播数据按钮
#element.click()
#driver.implicitly_wait(2)#等待10s以便页面加载完全
#抓取直播里面的文字信息
#element=driver.find_element_by_xpath("/html/body/div[2]/div/div[2]/div/a[6]")#找到战报元素
#print (5)#一个断点低级提示
#element.click() #点击战报元素
#mse=get_txt(url_new)
#a=['1','2','3','4']
#soup=BeautifulSoup(driver.page_source, 'lxml')
#txt1=soup.find('div',class_='article-a__content')
#for i in txt1('p')[:-1]:
# if('strong' in i.prettify())
# #print(len(i('strong')[0].get_text()))
# print(i('strong')[0].get_:text()[-3])
# #print("dasdsadsa")
# if(i('strong')[0].get_text()[-3] in a):
# #print(321321)
# continue
# print(i.get_text().replace(" ","").strip())
#print(i)
#fo.close()
years=['2012','2013','2014','2015','2016','2017']
mouth=['01','02','03','04','05','06','07','08','09','10','11','12']
days1=['01','02','03','04','05','06','07','08','09','10','11','12','13','14','15','16','17','18','19','20','21','22','23','24','25','26','27','28','29','30']
days2=['01','02','03','04','05','06','07','08','09','10','11','12','13','14','15','16','17','18','19','20','21','22','23','24','25','26','27','28','29','30','31']
days3=['01','02','03','04','05','06','07','08','09','10','11','12','13','14','15','16','17','18','19','20','21','22','23','24','25','26','27','28']
days4=['01','02','03','04','05','06','07','08','09','10','11','12','13','14','15','16','17','18','19','20','21','22','23','24','25','26','27','28','29']
try:
for i in years[0:]:
if(i== '2012' ):
for m in mouth[0:]:#每次出问题记得更改
if(m in ['06']):
for n in days1[16:]:
print(i + '-' + m + '-' + n)
print(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
search('http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate='+i+'-'+m+'-'+n)
elif (m in [ '09']):
for n in days1[25:]:
print(i + '-' + m + '-' + n)
print(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
elif (m in [ '11']):
for n in days1[28:]:
print(i + '-' + m + '-' + n)
print(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
elif(m in ['07']):
for n in days2[22:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(m in ['08']):
for n in days2[21:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(m in ['10']):
for n in days2[30:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
else:
for n in days2[30:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif( i == '2016'):
for m in mouth[11:]:
if (m in [ '11']):
for n in days1[23:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif (m in ['09']):
for n in days1[13:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif (m in [ '06']):
for n in days1[18:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif (m in ['04']):
for n in days1[8:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif (m in ['02']):
for n in days4[2:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(m in ['05']):
for n in days2[4:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(m in ['07']):
for n in days2[1:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(m in ['12']):
for n in days2[9:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
else:
for n in days2:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(i=='2013'):
for m in mouth[9:]:
if (m in [ '11']):
for n in days1:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif (m in ['09']):
for n in days1[28:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif (m in ['04']):
for n in days1[26:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif (m in ['06']):
for n in days1[1:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif (m in ['02']):
for n in days3[15:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(m in ['01']):
for n in days2:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(m in ['03']):
for n in days2[30:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif (m in ['10']):
for n in days2[23:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif (m in ['07']):
for n in days2[2:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
else:
for n in days2:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(i=='2014'):
for m in mouth[11:]:
if (m in ['04', '09']):
for n in days1:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(m in ['12']):
for n in days2[13:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif (m in ['11']):
for n in days1[26:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif (m in [ '06']):
for n in days1[28:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif (m in ['02']):
for n in days3[24:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(m in ['07']):
for n in days2[12:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(m in ['08']):
for n in days2[15:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(m in ['10']):
for n in days2[23:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
else:
for n in days2:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(i=='2015'):
for m in mouth[8:]:
if (m in [ '06', '11']):
for n in days1:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif (m in ['09']):
for n in days1[23:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif (m in ['04']):
for n in days1[14:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif (m in ['02']):
for n in days3:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(m in ['01']):
for n in days2[22:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(m in ['03']):
for n in days2[29:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(m in ['05']):
for n in days2[2:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(m in ['07']):
for n in days2[26:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
else:
for n in days2:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
else:
for m in mouth[11:]:
if (m in [ '06', '09']):
for n in days1:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif (m in [ '11']):
for n in days1[29:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif (m in ['04']):
for n in days1[26:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif (m in ['02']):
for n in days3[19:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(m in ['01']):
for n in days2[11:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(m in ['03']):
for n in days2[23:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(m in ['05']):
for n in days2[13:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif (m in ['07']):
for n in days2[18:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(m in ['08']):
for n in days2[27:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
elif(m in ['10']):
for n in days2[27:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
else:
for n in days2[16:]:
search(
'http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=' + i + '-' + m + '-' + n)
print(i + '-' + m + '-' + n)
#search('http://match.sports.sina.com.cn/index.html#type=schedule&matchtype=all&filtertype=time&livetype=ed&scheduledate=2017')
driver.quit()
except Exception as e:
print(e)
else:
print("error")