BiSeNet: 一种用于实时语义分割的双边分割网络

论文地址:https://arxiv.org/abs/1808.00897.pdf
代码地址:https://github.com/CoinCheung/BiSeNet
语义分割既需要丰富的空间信息,又需要相当大的感受野。然而,现在的方法通常会牺牲空间分辨率来实现实时推理速度,这导致了较差的性能。
在本文中,作者使用了一种新的双边分割网络(BiSeNet)来解决这一难题。他们首先设计了一条小步长的空间路径来保存空间信息并生成高分辨率的特征。同时,使用具有快速下采样策略的上下文路径来获得足够的接受场。在这两条路径之上,作者引入了一个新的特征融合模块来有效地组合特征。提出的体系结构在城市景观、CamVid和Coco-Stuff数据集上的速度和分割性能之间取得了适当的平衡。
01 Introduction
语义分割的研究是计算机视觉中的一项基础性工作,其实质就是为每个像素赋予语义标签。它可以广泛应用于增强现实设备、自动驾驶和视频监控等领域。这些应用对高效的推理速度有很高的要求,以实现快速交互或响应。
最近,实时语义分割的算法表明,主要有三种方法来加速模型:
1)尝试通过裁剪或调整大小来限制输入大小以降低计算复杂度。该方法虽然简单有效,但空间细节的丢失会破坏预测,特别是边界附近的预测,导致度量精度和可视化精度的下降。
2)一些工作不是调整输入图像的大小,而是修剪网络的通道以提高推理速度,特别是在基本模型的早期阶段。然而,它削弱了空间容量。
3)对于最后一种情况,ENET建议放弃模型的最后阶段,以追求极其紧密的框架。然而,这种方法的缺点是明显的:由于ENET放弃了最后一阶段的下采样操作,模型的接受域不足以覆盖大对象,导致分辨能力较差。
总体而言,上述方法在精度和速度上都有所折衷,在实际应用中表现较差。图1(A)给出了说明。

图1
为了弥补上述空间细节的缺失,研究者们广泛使用了U型结构,通过融合骨干网的层次化特征,U型结构逐渐提高了空间分辨率,填补了一些缺失的细节。然而,这种技术有两个缺点:
1)由于在高分辨率特征图上引入了额外的计算,所以完整的U型结构可以降低模型的速度。
2)更重要的是,如图1(B)所示,修剪或修剪过程中丢失的大部分空间信息不能通过涉及浅层轻松恢复。换句话说,U型技术更好地被视为一种解脱,而不是一种必要的解决方案。
为了在不损失速度的情况下追求更高的准确率,本文还研究了两条路径的融合和最终预测的精细化,并分别提出了特征融合模块(FFM)和注意力精化模块(ARM)。
本文主要贡献:
1、提出了一种具有空间路径(SP)和上下文路径(CP)的双边分割网络(BiSeNet)。
2、设计了两个具体的模块,特征融合模块(FFM)和注意力细化模块(ARM),以在可接受的成本下进一步提高准确率。
3、在城市景观、CamVid和Coco-Stuff的基准上取得了令人印象深刻的结果。更具体地说,本文在城市景观测试数据集上以105FPS的速度获得了68.4%的结果。
02 Related Work
最近,许多基于FCN的方法在不同的语义切分任务基准上都取得了最好的性能。这些方法有空间信息(Spatial information)、U型方法(U-Shape method)、上下文信息(Context information)、注意力机制(Attention mechanism)、实时分割(Attention mechanism),他们大多是为了编码更多的空间信息或扩大接收范围。
3 Bilateral Segmentation Network
在这一部分中,作者首先详细说明了他们提出的具有空间路径和上下文路径的双边分割网络(BiSeNet)。其次,还对这两条路径的有效性进行了相应的阐述。最后演示如何将这两条路径的功能与功能融合模块和本文的BiSeNet整体架构相结合。
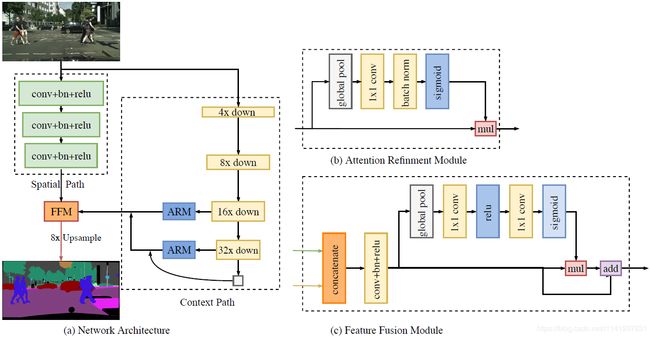
图2双边分割网络总览。(a)网络架构。块的长度表示空间大小,而厚度表示通道的数量。(b)注意力优化模块(ARM)的组件。(C)特征融合模块(FFM)的组件。读取线表示本文仅在测试时才执行此过程。
3.1 Spatial path
在语义分割方面,现有的一些方法试图保持输入图像的分辨率,通过膨胀卷积来编码足够的空间信息,而一些方法试图通过金字塔汇集模块、Atrus空间金字塔汇集或“大核”来捕捉足够的感受野。这些方法表明,空间信息和感受野是实现高精度的关键。然而,要同时满足这两个要求是很难的。特别是,在实时语义分割的情况下,现有的现有方法利用小输入图像或轻量级基模型来加速。较小的输入图像丢失了原始图像的大部分空间信息,而轻量级模型通过通道剪枝破坏了空间信息。
基于这一观察结果,作者提出了一种空间路径来保持原始输入图像的空间大小,并对丰富的空间信息进行编码。空间路径包含三个层。每层包括具有STRIDE=2的卷积,随后是批归一化和RELU。因此,此路径提取原始图像的1/8的输出特征图。由于特征图的空间大小,它编码了丰富的空间信息。图2(A)显示了该结构的细节。
3.2 Context path
空间路径编码了丰富的空间信息,而上下文路径则提供了足够的感受野。在语义分割任务中,接受场对任务的执行有着重要的意义。为了扩大接受范围,一些方法利用了金字塔汇集模块、Atrus空间金字塔汇集或“大内核”。但是,这些运算需要大量的计算和内存消耗,导致运算速度较慢。
同时考虑到较大的接受场和高效的计算,本文提出了上下文路径。上下文路径利用轻量级模型和全局平均池来提供更大的接受场。在这项工作中,轻量级的模型,如Xception,可以快速地对特征映射进行下采样,以获得较大的接受域,该接受域编码了高层语义上下文信息。然后在轻量级模型的尾部加入全局平均池,为最大接受域提供全局上下文信息。最后,将全局池化的上采样输出特性与轻量级模型的特性相结合。在轻量化模型中,本文采用了U型结构来融合后两个阶段的特点,这是一种不完全的U型风格。图2(C)显示了上下文路径的总体透视图。
注意力细化模块(Attention refinement module):在上下文路径中,本文提出了一个特定的注意力细化模块(ARM)来细化每个阶段的特征。如图2(B)所示,ARM采用全局平均汇集来捕获全局上下文,并计算注意力向量来指导特征学习。这种设计可以提炼上下文路径中每个阶段的输出特征。它不需要任何上采样操作,就可以很容易地集成全局上下文信息。因此,它所需的计算量可以忽略不计。
3.3 Network architecture
本文中使用预先训练好的Xception模型作为上下文路径的主干,使用三个卷积层和跨度作为空间路径。然后对这两条路径的输出特征进行融合,做出最终的预测。它可以同时达到实时性和高精度的要求。首先,本文将重点放在实际计算方面。虽然空间路径具有较大的空间大小,但它只有三个卷积层。因此,它不是计算密集型的。对于上下文路径,本文使用了一个轻量级的模型来快速下采样。此外,这两条路径并行计算,大大提高了效率。其次,本文讨论了该网络的精度方面。在本文中,空间路径编码了丰富的空间信息,而上下文路径提供了更大的感受野。它们是相辅相成的,以实现更高的性能。
特征融合模块(Feature fusion module):两条路径的特征表示层次不同。因此,本文不能简单地总结这些特点。空间路径捕获的空间信息大多编码了丰富的细节信息。此外,上下文路径的输出特征主要对上下文信息进行编码。换言之,空间路径的输出特征是低水平的,而上下文路径的输出特征是高水平的。因此,本文提出了一种特定的特征融合模块来融合这些特征。
考虑到特征的不同层次,本文首先将空间路径和上下文路径的输出特征进行拼接。然后,本文利用批次归一化来平衡特征的尺度。接下来,本文将连接的特征集中到一个特征向量中,并计算一个权重向量,就像SENET一样。该权重向量可以对特征重新加权,这相当于特征选择和组合。图2(C)显示了此设计的详细信息。
损失函数(Loss function):在本文中,本文还利用辅助损失函数来监督本文提出的方法的训练。本文使用主损失函数来监督整个BiSeNet的输出。此外,本文添加了两个特定的辅助损失函数来监督上下文路径的输出。所有损耗函数都是软最大损耗,如公式1所示。此外,本文使用参数α来平衡主损失和辅助损失的权重,如公式2所示。本文中的α等于1,节点损失使优化器更容易对模型进行优化。
![]()
其中p是网络的输出预测。
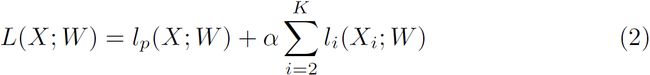
其中lp是级联输出的自身损失。Xi是Xception模型第一阶段的输出特征。Li是第i阶段的辅助损失,在本文中K等于3。L是联合损失函数。这里,本文只在训练阶段使用辅助损失。
4 Experimental Results
本文采用改进的Xception模型Xception39进行实时语义分割。
4.1 Implementation protocol
Network:空间路径采用三卷积,上下文路径采用Xception39模型。然后利用特征融合模块将这两条路径的特征结合起来对最终结果进行预测。空间路径和最终预测的输出分辨率为原始图像的1/8。
Training details:我们在训练中使用小批次随机梯度下降法[16],批次大小为16,动量为0.9,重量衰减为1e−4。本文采用了“poly”学习速率策略,其中初始速率乘以(1−iter/max_iter) power幂每次迭代的幂为0.9。初始学习速率为2.5e−2。
Data augmentation:在训练过程中,我们对输入图像采用均值减法、随机水平翻转和随机尺度对数据集进行扩充。刻度包含{0.75,1.0,1.5,1.75,2.0}。最后,我们将图像随机裁剪成固定大小进行训练。
4.2 Ablation study
在这一小节中,详细地研究了提出的BiSeNet中每个组件的影响。在接下来的实验中,使用Xception39作为基本网络,并在城市景观验证数据集[9]上对本文的方法进行了评估。
表1 基线模型的精度和参数分析:在城市景观验证数据集上的Xception39和Res18。在这里使用FCN-32作为基础结构。估计输入为3×640×360的触发器。

表2 一张NVIDIA Titan XP卡上的U形-8和U-形-4的速度分析。图像大小为W×H。

表3详细比较了我们提出的BiSeNet中每个组件的性能。CP:上下文路径;SP:空间路径;GP:全局平均池;ARM:注意力细化模块;FFM:特征融合模块。
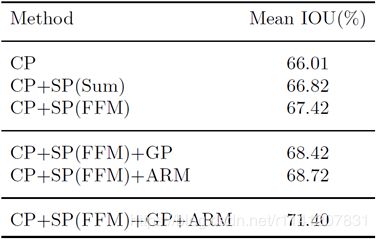
表4 基线模型的精度和参数分析:在城市景观验证数据集上的Xception39和Res18。这里使用FCN-32作为基础结构。估计输入为3×640×360的触发器。
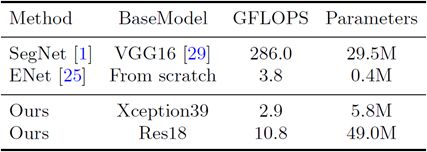
表5 将我们的方法与其他最先进的方法进行速度比较。图像大小为W×H,Ours1和Ours2是基于Xception39和Res18模型的BiSeNet。
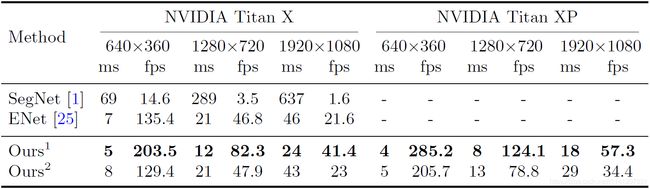
表6 在城市景观测试数据集上与其他最先进的方法进行了准确度和速度的比较。我们在具有2048×1024分辨率输入的NVIDIA Titan XP上进行了培训和评估。“-”表示这些方法没有给出相应的精度速度结果。
4.3 Speed and Accuracy Analysis
在这一部分中,首先分析算法的速度。然后,与其他算法相比,在CitySces、CamVid和Coco-Stuff基准测试上的最终结果。
Speed analysis: 速度是算法的一个重要因素,特别是当我们将其应用到实践中时。我们在不同的环境下进行了实验,以进行全面的比较。首先,我们在表4中显示了FLOP和参数的状态。FLOP和参数表示处理此分辨率图像的操作次数。为了进行公平的比较,我们选择640×360作为输入图像的分辨率。同时,表5给出了我们的方法与其他方法在不同输入图像分辨率和不同硬件基准下的速度比较。最后,我们报告了我们在城市景观测试数据集上的速度和相应的精度结果。从表6可以看出,与其他方法相比,我们的方法在速度和精度上都有了很大的进步。在评估过程中,我们首先将2048×1024分辨率的输入图像缩放到1536×768分辨率,以测试速度和精度。同时,我们使用在线自举策略计算损失函数。在这个过程中,我们没有使用任何测试技术,比如多尺度或多作物测试。
Accuracy analysis:与其他非实时语义分割算法相比,我们的BiSeNet也能达到更高的准确率。这里,我们将展示城市景观、CamVid和Coco-Stuff基准的精度结果。同时,为了保证方法的有效性,我们还将其应用于不同的基础模型,如标准的ResNet18和ResNet101。接下来,我们将详细介绍一些培训细节。
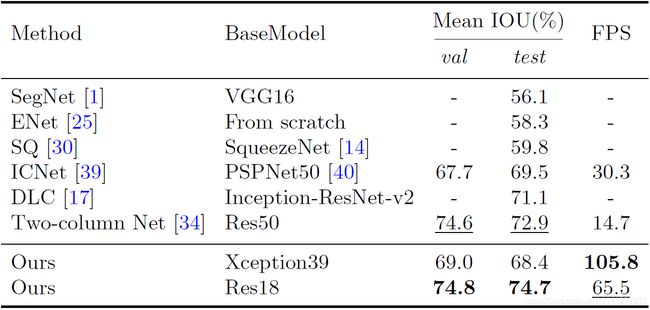
表7 在城市景观测试数据集上,将我们的方法与其他最先进的方法进行了精度比较。“-”表示这些方法没有给出相应的结果。
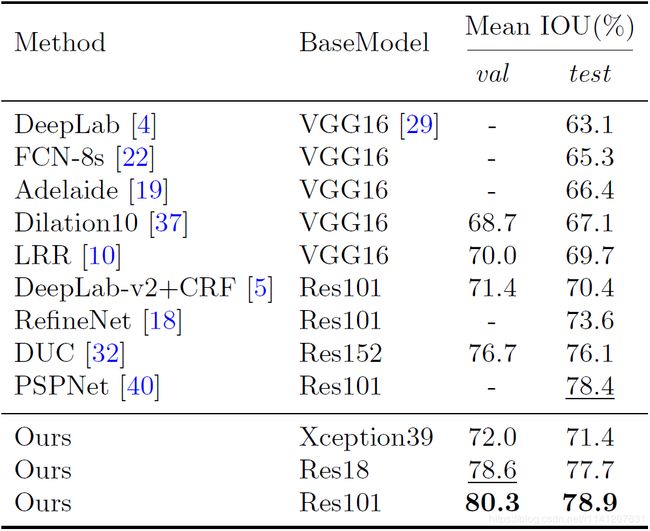
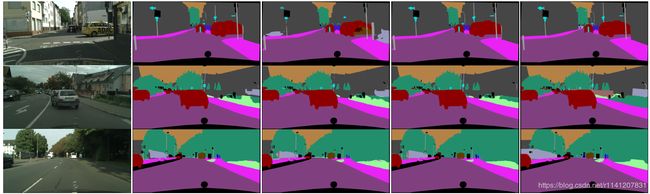
Cityscapes:如表7所示,我们的方法在不同的模型上也取得了令人印象深刻的结果。为了提高精度,我们随机选取1024×1024个作物作为输入。在这里,我们只使用城市景观数据集的精细数据。图4显示了我们的结果的一些可视示例。
![]()
图4基于城市景观数据集的Xception39、Res18和Res101模型的BiSeNet结果示例。
CamVid:表8显示了CamVid数据集的统计精度结果。对于测试,我们使用训练数据集和验证数据集来训练我们的模型。在这里,我们使用960×720分辨率进行训练和评估。
COCO-Stuff:我们还在表9中报告了我们在可可粉验证数据集上的准确性结果。在培训和验证过程中,我们将输入裁剪到640×640分辨率。为了公平比较,我们不采用多尺度测试。
表8 CamVid测试数据集的准确性结果。Ours1和Ours2表示基于Xception39和Res18网络的模型。
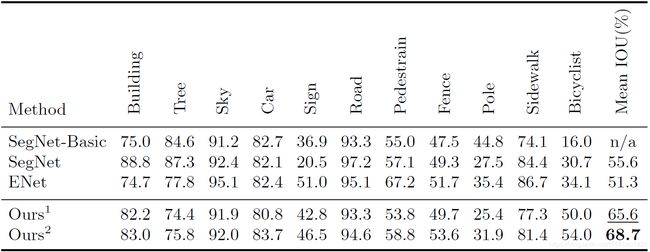
表9 COCO-STRIPT验证数据集的准确性结果。
5 Conclusions
为了同时提高实时语义切分的速度和准确率,提出了双边切分网络(BiSeNet)。我们提出的BiSeNet包含两条路径:空间路径(SP)和上下文路径(CP)。空间路径的设计目的是保留原始图像的空间信息。上下文路径利用轻量级模型和全局平均池快速获得较大的接受场。利用丰富的空间细节和较大的感受野,我们在105FPS的Cityscapes测试数据集上获得了68.4%的平均IOU。