高性能mysql笔记-高性能索引
高性能索引
写在开头一些重要的话,如题高性能的索引。现在很多文章或者博客都会有一些索引建立的规则。
比如说程序员必须掌握的10条SQL技巧,你不知道的SQL10条索引规则。而且这些文章的阅读量比其他讲原理性的要高。能够体现出如今码农们急躁的心理。想通过这些技巧就掌握索引优化。举个明显的例子,前导模糊查询不能使用索引 select * from order where desc like ‘%XX’。单纯的只记住用前导模糊查询索引不起效。而不知所以然。只是记着这一规则,而不知道索引的数据结构导致失效的原因。所以接下来会讲一下底层数据结构,接着讲高性能索引的策略就会明白其中原因。
索引结构
当谈论索引的时候,绝大部分说的是B-tree索引。而不同的存储引擎会有不同的数据结构。如INNODB存储引擎使用的是B+Tree存储结构(特殊的BTree结构–中间节点存放索引,数据只存在叶子节点)
最典型的是聚簇索引以及二级索引,下面来分析下这两个索引的数据结构。
聚簇索引
聚簇索引在一张表中最多存在一个。因为叶子节点存储的数据类型是行数据。又因为数据表中只能存在一处物理行数据,所以聚簇索引最多只能一个。下面是聚簇索引的结构图。
聚簇索引叶子节点数据不止有行记录,还有TransactionID事务ID,Rollback Pointer回滚指针。
二级索引
左边是INNODB的聚簇索引以及二级索引。右边是MYISAM的索引
二级索引叶子节点的数据类型是主键。很多人会问为什么不是存储主键指针,这样数据变小,减少IO压力以及提高查询的效率。你说的没错,如果单纯查询,毫无疑问肯定是用指针。但如果考虑到插入以及删除时所带来的页分裂行位置改变,从而改变了主键的存储地址。这时候二级索引叶子节点数据需要重新维护。这样造成每次插入或者删除时都会带来性能的消耗。所以存储主键的值是用空间换取性能。但是这样会造成二次查找的问题,因为从二级索引找到主键后,需要再到聚簇索引中找到对应的行记录。
二次查找解决办法
- 索引覆盖
即二级索引包含了所需要查找的列时,无需再到聚簇索引中重新查找记录。 - 延时关联
先利用二级索引select主键,再用主键ID到聚簇索引中查找记录。
索引优势
- 减少服务器扫描的数据量
- 避免服务器对数据排序以及临时表的消耗
- 随机IO变成顺序IO
三星评价-判断是否满足高性能的索引要求
一星:索引是否将数据记录放到一起
二星:索引中数据排列数据与查找中的数据顺序一致
三星:索引包含了所有查找列
高性能策略
1、前缀索引和索引选择性
选择合适长度的索引,减少索引大小,降低IO压力。但如何选择合适的长度呢?
首先介绍一个概念,索引选择性,即列的不重复数据数量与列的数据总数的比值:count(不重复数)/count(列)。
当值越高,更适合使用索引。但这条规则不是绝对的,千万一上来的套用。
例子:在city_demo表的city列中找出合适长度的索引

可由上图中发现在length=7时,索引选择性最高。所以索引的长度可以选择7。
注意:若用groupby,orderby无法使用前缀索引扫描
2、多列索引
多列索引也叫做组合(复合)索引。不是在每个列中建立索引,而是对所有列建立一个索引。
复合索引需要满足最左前缀,即利用复合索引时,必须包含最左边的列。
create table t(
c1 int,
c2 int,
c3 int,
KEY(c1,c2,c3)
);
①:select * from t where c1,c2,c3
②:select * from t where c1,c2
③:select * from t where c1,c3
④:select * from t where c2,c3
⑤:select * from t where c1;
⑥:select * from t where c2
⑦:select * from t where c3上面7个查询中能利用索引的有①,②,③,⑤。如果这时候理解多列索引的数据结构,就很容易的理解为什么要包含最左边的列。
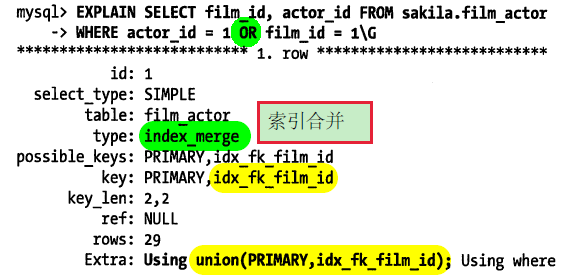
但EXPLAIN出现Using UNION或者type为index——merge(索引合并)时应该检查下查询和表的结构
索引中列顺序也可按索引选择性进行排序,经验法则
比如下面的情况
select * from payment
where staff_id=2 and customer_id=584;
建立复合索引
alter table payment add KEY(customer_id, staff_id);
5、聚簇索引
上面已经讲过了,这里就不再重复.如果不明白页分裂的过程,可以自行搜索了解。这里不详细说明。
6、覆盖索引
上面已经讲过了。不重复讲述
7、使用索引扫描来排序
通常排序有两种方式,第一种是索引扫描排序,第二种则是非索引即文件排序filesort。
还记得上面讲的索引优势吗? 第二条,减少数据排序和临时表的消耗。所以高性能策略建议使用索引扫描排序。如果索引不能够覆盖查询所需的列时,那就得每扫描一次索引记录就回表查询一次对应的行,那这样是随机IO。因此按索引顺序读取比全表扫描慢。
MYSQL使用同一个索引既满足排序,又用于查找行。这样的排序效果是最好的。
维护索引和表
维护表有三个目的:找到并修复损坏的表;维护准确的索引统计信息;减少碎片。
总结
编写查询语句时的建议
一、避免单行查找
二、使用原生数据排序避免filesort
三、索引覆盖(索引中的列包含了所需的列)
最重要的还是理解索引如何工作,才能创建合适的索引