java数据结构篇-ArrayList使用和源码分析
抱歉最近实在是太鸽了

主要是ArrayList我是真傻了,我参考了大量前辈们写的资料,将源码翻了几遍,真的傻了,这还是我当初学的ArrayList嘛,光整理这些资料变成自己的东西就花了好久
这篇文章我参考了前辈们的一些博客文,在他们的基础上加上自己的一些理解并且进行了整理
ArrayList定义
ArrayList 底层是数组列表,当我们存储基本数据类型int、long、boolean …只能存储他们对应的包装类他们底层实现是数组Object[]elementData
相比于LinkList 它的查找和访问元素速度较快,但新增、删除的数据慢
我们来看看源码注释对ArrayList的官方解释
1.这类实现了List接口,可实现底层数组的大小的调整
2.运用了泛型允许所有类型的元素存储,包括null值,实现了所有list的操作
3.提供了操作数组大小的各类方法
4.用于内部存储列表,相当于Vector集合但是Vector同步,ArrayList不同步(线程非安全)
5.有迭代器iterator和列表迭代器Listiterator 在常量中进行操作运行
6.时间上,每一次添加一个元素时间复杂度都是0(n),相比于与Linklist性能低
7.每个ArrayList 实例都有一个容器,容器是一个array集合的大小,用于在集合中存储元素,容器至少和Arraylist大小一样大,当元素被添加到集合中会让容器的size自动增大,
8.我们可以增加list实例的容量,最好在添加大量元素之前进行预备的扩容早点定义大容量,减少重新分配元素的数量,但是这个步骤并不同步,如果多个线程同时访问一个实例如果出现一个线程是改内容的,务必在外部进行同步,来保证同步访问
9面对并发修改,迭代器快速失败、清理,而不是在未知的时间不确定的情况下冒险。请注意,快速失败行为不能被保证。通常来讲,不能同步进行的并发修改几乎不可能做任何保证。因此,写依赖这个异常的程序的代码是错误的,快速失败行为应该仅仅用于防止bug
ArrayList继承和实现,
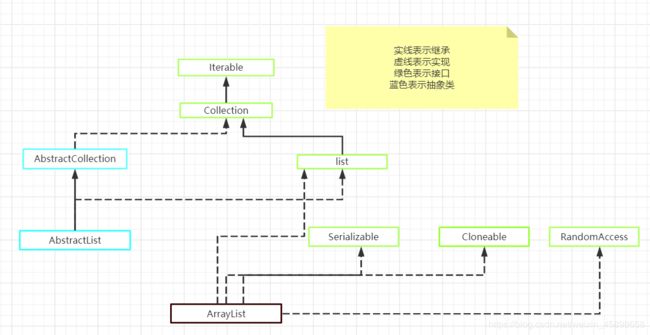
实现了RandomAccess 接口,可以随机访问,
实现了Cloneable接口,可以克隆
实现了Serializable 接口,可以序列化(对象变数据)反序列化(数据变对象)
实现了List接口,有List的特性方法
实现了Collection接口 是Collection家族成员之一
实现了Iterable接口,可以使用for-each迭代
ArrayList类的属性:
//序列化版本的UID
private static final long=serialVersionUID=8683452581122892189L;
//默认的初始容量
private static final int=DEFAULT_CAPACITY=10;
//用于空实例的共享空数组实例,new ArrayList(0)
private static final Object[] =EMPTY_ELEMENTDATA={};
//用于提供默认大小的实例的共享空数组实例
private static final Object[]= DEFAULTCAPACIYT_EMPTY_ELEMENTDATA={};
//存储ArrrayList元素的数组缓冲区,ArrayList 的容量是数组的长度
transient Object[]elementData;
//作为属性没有被封装为什么?
//一位阿里的前辈做过测试说:是因为private 一定程度上会影响其他内部类的访问
//ArrayList中元素的数量
private int size
ArrayList 构造机制:
ArrayList 可以通过构造方法在初始化的时候指定数组的大小
1.无参数构造方法
transient Object[] elementData;
private static final Object[] EMPTY_ELEMENTDATA = {};
public ArrayList() {
super();
this.elementData = EMPTY_ELEMENTDATA;//底层数组列表指向这个空的数组,
//只有当add时候才会分配默认DEFAULT_CAPCITY=10的初始容量
}
2.带参数的构造方法
通过构造方法设置数组的范围
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData =
new Object[initialCapacity];
} else if (initialCapacity == 0) {//如果initialCapacity==0 就使用EMPTY_ELEMENTDATA
this.elementData = EMPTY_ELEMENTDATA;
} else {//如果initialCapacity<0 ,就创建一个新的长度initialCapcity
throw new IllegalArgumentException(
"Illegal Capacity: "+ initialCapacity);
}
}
/**
*无参数构造方法将elementData 赋值为DEFAULTCAPACITY_EMPTY_ELEMENTDATA
*/
//add方法会调用ensureCapcityInteter方法在确定
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!//size是指实际存储的数据容量
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == EMPTY_ELEMENTDATA) {//如果我们的储存数组指向这个默认给我们的空数组
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);//我会判断下是我原本的DEFAULT_CAPACITY=10大还是add后的minCapactiy大,大的定位我们的数组初始容量
}
ensureExplicitCapacity(minCapacity);
}
注:大家看到final修饰的EMPTY_ELEMENTDATA可能会奇怪final修饰的变量不是不能变吗,那我们怎么加数据
确实不能变,不能变的是栈内存里面的那个地址引用,final修饰的基本类型数据不能变,修饰的引用类型引用不能变
3.带一个集合参数的构造方法
/**
* 带一个集合参数的构造方法
* @param c集合 代表集合中的元素会被放到list中
* 如果集合为空,抛出NullPointException
*
*/
public ArrayList(Collection<? extends E> c) {//这个Collection 运用了泛型,表示允许Collection底下任何集合类任何
elementData = c.toArray();//1.使用将集合转换为数组的方法
// 如果 size != 0
if ((size = elementData.length) != 0) {//2为了防止toArray方法不正确的的执行,导致没有返回Object[] 会做一些判断和处理
// c.toArray 可能不正确的,不返回 Object[]
// https://bugs.openjdk.java.net/browse/JDK-6260652
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(
elementData, size, Object[].class);
} else {
//3.如果数组大小为0,则使用EMPTY_EMEMENTDATA
// size == 0
// 将EMPTY_ELEMENTDATA 赋值给 elementData
this.elementData = EMPTY_ELEMENTDATA;
}
}
ArrayLIst扩容机制:
数组本身你定了范围后,长度就限定在那个范围
一个长度为十的数组不够,会新建一个长度为10+10/2的数组再将原来数组的数据信息复制到新数组,将引用指向这个新数组
图示:
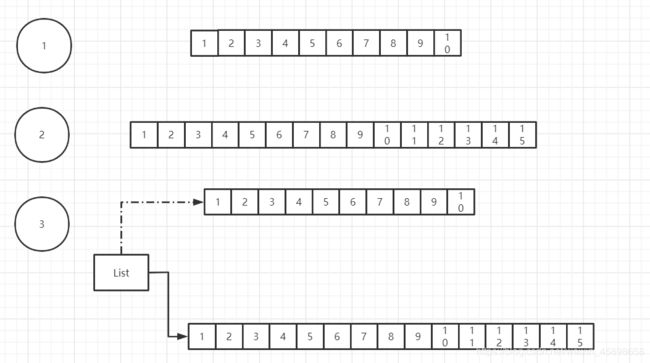
研究如何扩容什么时候扩容,我们来看看源码
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!//在父类的AbstractList上定义了modCount属性,用于记录数组修改的次数
//1.先把增加后的容量作为参数放进一个方法判断,是否需要扩容
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == EMPTY_ELEMENTDATA) {//可能数组指向的是我们的空数组我先赋值一个范围
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);//谁大用谁的
}
ensureExplicitCapacity(minCapacity);//将确定好的增加元素的范围再进行一次判断
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);//如果我未来的范围大于我数组整体的长度我就要考虑扩容了
}
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private void grow(int minCapacity) {//
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);//确定新的容器容量:*1.5,这里采用了位运算,比原来乘除更快
//oldCapacity>>1 表示 0.5*oleCapacity
if (newCapacity - minCapacity < 0)//但是有可能出现:我add方法我一次加了很多元素,直接超过了1.5原容量,
//那我就按你加元素后的容量来
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)//当然毕竟是容器,肯定是有着它自己的限制如果系统1.5呗后的量
//比MAX_ARRAY_SIZE((2^31-1)-8) 还要大,那就拿着扩容后最少容量去判断下新容量应该是多少
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
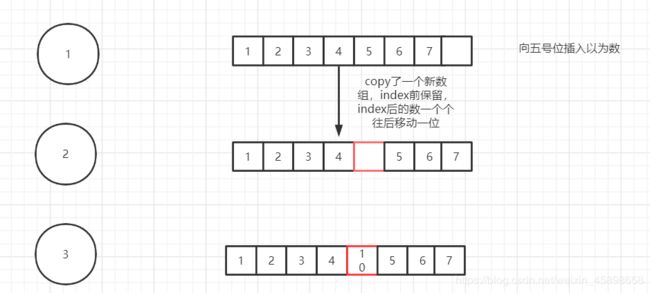
2.指定位置进行新增时候的扩容机制:
public void add(int index, E element) {
rangeCheckForAdd(index);//先看看这个index有没有超过array的size的范围
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
// arraycopy 复制了一个数组从index位置开始,为了给这个index腾出个位置,然后数组一个个复制到index+1后面然后在把放到这个index的位置里
JavaBug经典问题:
ArrayList(int initialCapcity) 这个带参构造方法会不会初始化内部的elementData 大小:
首先我们先明白下ArrayList有length 和size 两种大小,length 是本身数组的长度,size是数组内部有值的大小也叫集合的长度

我们再看看这个构造方法源码:
private int size;
public ArrayList(int initialCapacity) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
}
//这时候,size并没有被定义,虽然我们数组长度是10,但ArrayList它认为自己长度为0
//这时候你输入size 是为0 ,输出set(6,1)这样是会爆出越界
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
//set(int index,xxx )会调用rangeCheck这个方法判断你要输入的index是否超过了size超过就报错
报错如下:此时size为0,没有初始化

ArrayList的定点删除机制:
public E remove(int index) {
rangeCheck(index);//检查是否越界
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
//根据内容对象来删
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
本质上跟新增是一样的,新加了一个新数组,把index+1后面的数据全部向前移动,将index+1后面的数组一个个赋值。
总结:定点删除和新增:
都是先将index之后的数据放到一个临时数组里
删除是从index 开始复制,也就是覆盖
新增是从index+1开始复制,也就是留位置
比较核心的增改调用流程图
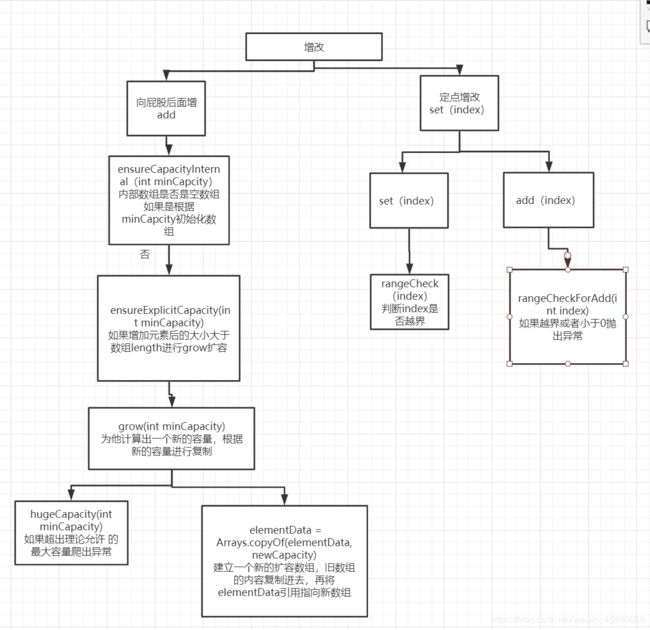
注:
ArrayList线程安全问题:
ArrayList本身是线程不安全的,但它有个替代品Vector 是将Arraylist所有机制都加上线程锁
ArrayList本身不适合做先进先出的队列
相比于LinkList 遍历性能更好
常用方法:
add(E e) 将制定元素添加到列表尾部
addAll(Collection c) //将Collection下的集合一个个遍历添加到尾部
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();//先变成数组
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount:增加modCount值
System.arraycopy(a, 0, elementData, size, numNew);//一个个遍历赋值
size += numNew;
return numNew != 0;
}
contains(Object o)//是否有某个元素
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
ensureCapacity( int minCapactiye)//扩容
indexOf(Object o) 列表中首次出现的元素的索引,如果不包含元素返回-1
removeRange(int fromIndex ,int toInex)//在 [fromIndex,toIndex) 区间的元素都删除
protected void removeRange(int fromIndex, int toIndex) {
modCount++;
int numMoved = size - toIndex;
System.arraycopy(elementData, toIndex, elementData, fromIndex,
numMoved);
// clear to let GC do its work//所谓删除只是索引不指向它,这个元素没有人指向他会慢慢给GC回收
int newSize = size - (toIndex-fromIndex);
for (int i = newSize; i < size; i++) {
elementData[i] = null;
}
size = newSize;
}
toArray//将list变成数组
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
clear()//清空元素
public void clear() {
modCount++;
// clear to let GC do its work
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
subList(int fromIndex,int toIndex) 截取某个区间的元素
public List<E> subList(int fromIndex, int toIndex) {
subListRangeCheck(fromIndex, toIndex, size);
return new SubList(this, 0, fromIndex, toIndex);
}
trimToSize()
去调ElementData 屁股后为null的部分//有种压缩的感觉
ArrayLIst 序列化和反序列化机制
序列化方法://初学者只需要知道序列化时把对象变成一个存在可以看到的文件,反序列化是把文件上的信息变成
序列化和反序列化实际运用
public static void main(String []args)throws IOException,ClassNotFoundException {
List<Integer>list =new ArrayList<>(Arrays.asList(3,4,5));
//新建一个带有东西的数组
ByteArrayOutputStream byteArrayOutputStream=new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream=new ObjectOutputStream(byteArrayOutputStream);//字节流包装
objectOutputStream.writeObject(list);//将list序列化
ByteArrayInputStream byteArrayInputStream=new ByteArrayInputStream(byteArrayOutputStream.toByteArray());
//字节流变成字节数组
ObjectInputStream objectInputStream=new ObjectInputStream(byteArrayInputStream);
List<Integer> newList= (List<Integer>)objectInputStream.readObject();//字节变成对象
System.out.println(Arrays.toString(newList.toArray()));//将list对象变成数组
}
![]()
将ArrayLisy实例的状态保存到一个流里面
ArrayList 实现Serializable接口被允许能进行序列化,但是ArrayLIst重写了readObject和writeObject 类自定义的序列化和反序列化策略,
自定义序列化和反序列化定义:
1.在序列化过程中,如果被序列化的类中定义了writeObject 和readObject 方法,虚拟机 会试图 调用对象类里的writeObject和readObject 方法进行用户自定义的序列化和反序列化
2.如果没有这样的方法,则默认调用是ObjectOutputStream 的defaultWriteObject 方法以及ObjcetInputStream 的defaultReadObject方法
3.用户自定义的writeObject 和readObject 方法可以允许用户控制序列化的过程,比如可以在序列化的过程中动态改变序列化的数值
ArrayList源码中自定义的序列化和反序列化
/**
* 将ArrayLisy实例的状态保存到一个流里面
*/
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;//modCount变动计数器先把他冻结在一个变量
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// 按照顺序写入所有的元素
for (int i=0; i<size; i++) {//首先Arraylist是一个动态数组,1.5倍扩容的情况下会有数组会有很多为null的元素,
//这些空元素序列并没有必要, 所以我们ArrayList的elementData是被transient修饰的,避免全部没用的元素被序列化
//在这里会一个个的遍历elementData实际元素
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {//如果在序列化期间,集合发生了变动就抛出异常
throw new ConcurrentModificationException();
}
}
反序列化源码:
/**
*
*
*/
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();//将字节码一个个赋值下去
}
}
}
**
ArrayList clone机制
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
//下文中Fail-Fast 机制和迭代器息息相关,各位可以结合一起阅读
Fail-Fast 机制:
**
Fail-Fast机制百科解释:
在系统设计中,快速失效系统一种可以立即报告任何可能表明故障的情况的系统。快速失效系统通常设计用于停止正常操作,而不是试图继续可能存在缺陷的过程。这种设计通常会在操作中的多个点检查系统的状态,因此可以及早检测到任何故障。快速失败模块的职责是检测错误,然后让系统的下一个最高级别处理错误。
这也可以说是一种思想在做设计时候优先考虑异常情况,一旦发生异常,直接停止并上报,预先识别一些错误情况,防止更大错误的产生
java中的fail-fast 机制指的是 java集合中的一种错误检验机制,当多个线程对一些线程不安全的集合做出改变时候,会产生fail-fast机制抛出我们的老朋友:ConcurrentModificationException 防止在多线程并发操作数据的时候出现问题。
但是非单线程时候也会出现问题
ArrayList中的Fail-Fast机制
modCount 用来记录ArrayList 结构发生变化的次数。结构发生变化是指添加或者添加或者删除至少一个元素所有的操作,或者是调整内部数组的大小,仅仅只是设置元素的值不算结构发生变化
在进行序列化或者迭代等操作时,需要比较操作前后modCount 是否改变,如果改变了,在迭代器或者序列化时候,会调用checkForComodification(),判断期间是否有改变,需要抛出ConcurrentModificationException 异常来保证数据的安全
这是Fail-Fast机制,当然这也是个问题,我们有时候也会希望在迭代器期间会改变元素
迭代器Iterator 已经为我们提供remove 方法,所以我们只需要调用迭代里面的remove 方法就可以 了
ArrayList 迭代器机制:
//迭代器是一种集合的遍历方式之一,ArrayList 通过内部类实现Iterator 接口来实例化迭代器类,通过Iterator来实现对集合内部元素数组的遍历
源码中的ArrayList 创建迭代器:
/**
* Returns an iterator over the elements in this list in proper sequence.
*
* The returned iterator is fail-fast.
*
* @return an iterator over the elements in this list in proper sequence
* //翻译:以正确的顺序遍历这个列表中的元素
*/
public Iterator<E> iterator() {
return new Itr();
}
//Iterator 是ArrayList 的一个内部类, Itr 有一个成员变量叫expectedModCount
Itr属性
private class Itr implements Iterator<E> {
//下一个要返回的元素的下标
int cursor; // index of next element to return
//最后一个要返回的元素的下标,没有元素返回1
int lastRet = -1; // index of last element returned; -1 if no such
//期望的modCount//操作计数器
int expectedModCount = modCount;.
}
内部类Itr的hasnext方法
public boolean hasNext(){
return cursor!=size;
}
Itr的next方法
public E next() {
checkForComodification();//
int i = cursor;
if (i >= size)//检查一遍下标cursor,赋值给一个变量是为了将数据冻住,防止想要判断的数被更改
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
final void checkForComodification() {//前文讲到Fail-Fast机制,检查一遍集合是否有改动
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
所以在你还在迭代的时候改动集合会抛出 ConcurrentModificationException异常
如下代码
ArrayList arrayList=new ArrayList();
for(int i=0;i<10;i++){
arrayList.add(i);
}
Iterator<Integer > iterator=arrayList.listIterator();//拿到我们Arraylist的迭代器
while (iterator.hasNext()){//判断下下面是由还有元素,如果有就把它拿出来
Integer j =iterator.next();
if( j== 1){
arrayList.remove(j);
}
}

不仅仅是在迭代器遍历,foreach循环遍历的时候最好不要进行remove和add的修改操作可能会触发fail-each机制触发异常
我们看看实际情况:
//直接for 通过i作为索引去循环遍历不会出现问题
ArrayList<Integer> arrayList=new ArrayList();
for(int i=0;i<10;i++){
arrayList.add(i);
}
for(int i =0;i<arrayList.size();i++){
if(i==3){
arrayList.remove(3);
}
}
System.out.println(arrayList);
//如果是foreach会触发
ArrayList<Integer> arrayList=new ArrayList();
for(int i=0;i<10;i++){
arrayList.add(i);
}
//35
for(int i :arrayList){
if(i==3){
arrayList.remove(3);
}
}
System.out.println(arrayList);

这里有前辈通过jad 反编译工具对这段代码进行了反编译处理我这里直接套用了
foreach其实内部有相关的语法糖, 内部实现如下
ArrayList<Integer> arrayList=new ArrayList();
for(int i=0;i<10;i++){
arrayList.add(i);
}
Iterator iterator =arrayList.iterator();//拿到了集合的迭代器
do{
if(!iterator.hasNext())
break;
Integer i =(Integer)iterator.next();
if(i==(3))
arrayList.remove(i);
}while(true);
System.out.println(arrayList )
//foreach 依然是通过迭代器实现的,如果循环遍历期间出现改动依然会触发 checkForComodification()方法中的异常抛出
其实总结一下为什么我们循环期间remove或者add 会在 checkForComodification(); 方法里判断modCount 和
expectedModCount 不一样 ,我们remove 在变动modCount时候并没有跟着改动expectedModCount
总结图指示
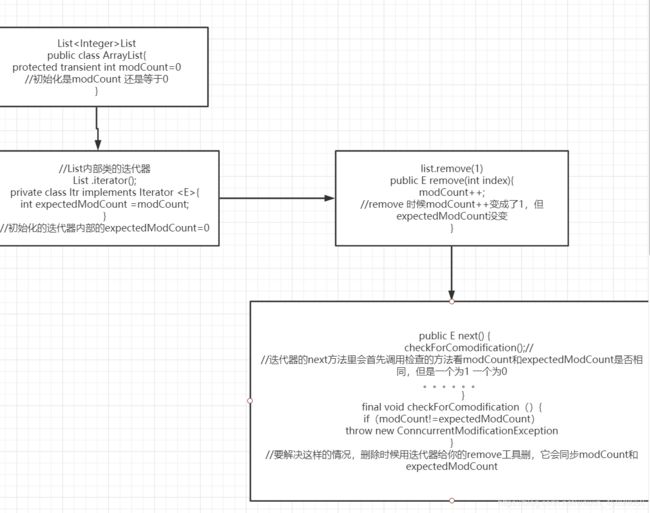
Fail-Fast问题如何解决:
(我们不直接通过list直接去删除而是让迭代器帮我们去删除,将arraylist.remove 换成iterator.remove)
我们来看看迭代器remove的源码
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
// 移除之后将modCount 重新赋值给 expectedModCount,为了保证在 checkForComodification();这个方法中我们modCount 是当前实况的变动计数
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
总结:
1.ArrayList 底层为数组,数组为了保证序列化的效率被transient修饰防止被全部序列化,没有被private修饰防止影响内部类访问数组的情况
2.ArrayList自动扩容,扩容jdk1.8之后用了 位运算来加快扩容的计算效率,
3.不管构造方法给不给初始值两都会初始化一个数组,但不给初始值时候如果添加元素,依然会进行扩容给你赋初始容量,所以创建ArrayList 最好给初始容量,减少不必要的扩容的次数
4.迭代器或者foreach(底层还是用了迭代器)遍历时候,中间不要list.remove或者list.add ,它只会改modCount不会改expectedModCount ,两者不相等会触发fail-fast机制会抛出异常
5.多线程访问集合时候务必保证通过防止触发fail-fast
6.ArrayLIst 遍历非常快,如size、isEmpty、get、set、iterator、这些操作时间复杂都是0(1)
如果涉及到定点增,删,其他处理时间复杂度0(n)
7.ArrayList 和Vector 大致相同但是ArrayList 是线程非安全
8.ArrayList 重写了序列化反序列化,避免序列化无用的null元素(都是一个个遍历序列化的)
参考资料:
https://mp.weixin.qq.com/s/WoGclm7SsbURGigI3Mwr3w //《吊打面试官》系列-ArrayList
https://blog.csdn.net/u013277209/article/details/101757718
https://mp.weixin.qq.com/s__biz=MzI3NzE0NjcwMg==&mid=2650123769&idx=2&sn=87d070e0a1a5e66a87eed4e22a99aa63&chksm=f36bb0d8c41c39ce80af4ff385a75f762a7f73850589517cb1ba28a42e9eb09eeb3bd81d4201&scene=21#wechat_redirect