face论文翻译--3D Face Morphable Models “In-the-Wild”
3D Morphable模型(3DMMs)是三维人脸形状和纹理的有力统计模型,也是从单个图像重建面部形状的方法。随着新的3D传感器的出现,许多三维人脸数据集已经被收集,既包括中性,也包含有表情的面孔。但是,所有数据集都是在受控条件下捕获的。因此,即使能从这些数据中学习到强大的3D人脸模型,也很难建立足够的统计纹理模型来重建在无约束条件下捕获的人脸(“in-the-wild”)。在本文中,我们通过结合一个强有力的面部形态的统计模型,将面部轮廓的特征和表达方式结合在一起,提出了一种“在野外”的3DMM,并采用了“In -the-wild”纹理模型。我们证明了这种“in-thewild”纹理模型的使用极大地简化了拟合过程,因为没有必要对光照参数进行优化。此外,我们提出了一种新的快速算法,用于在任意图像中拟合3DMM。最后,我们以相对无约束的条件捕获了第一个3D人脸数据库,并以最先进的性能报告了定量评价。在标准的“野外”面部数据库中展示了互补的定性重建结果。
1. Introduction
在过去的几年里,我们在人脸检测和二维人脸地标定位等各种人脸分析任务上都取得了显著的进步。这主要是因为社区已经作出了相当大的努力来收集和注释在无约束条件下捕获的面部图像(通常被称为“in-the-wild”),以及可以利用大量数据的讨论性的方法。然而,由于缺乏地面真实数据,识别技术不能用于三维人脸形状估计。
在过去的二十年中,从单个图像中得到的三维人脸形状估计已经引起了许多研究者的关注。研究的两大主线是(i)拟合3D模型(3DMM)和(ii)从阴影(SfS)技术中应用形状。在Blanz和Vetter的工作中提出的3DMM拟合是第一个基于模型的3D人脸恢复方法。该方法要求在有显式通信的空间中建立一个三维的面部纹理和形状的统计模型。第一个3DMM是使用在良好控制的条件下捕获的200个面,只显示中性的表达式。这就是为什么这种方法只能在现实世界中使用,而不是“在野外”的图像。最先进的SfS技术利用特殊的多线性分解,找到一个近似的球形谐波分解的照明。此外,为了从大量的“野外”图像中获益,这些方法共同重建了大量的图像集合。然而,即使结果很有趣,因为在面部表面没有之前,这些方法只能恢复面部的2.5D表示,特别是面部法线的平滑近似。
在“in-the-wild”条件下,从单一图像恢复到三维面部形态仍然是计算机视觉中一个开放性和挑战性的问题,主要原因是:
• 从单个图像中提取三维面部形状的一般问题是一个病态的问题,这是众所周知的难以解决的问题,没有使用任何统计先验的形状和纹理的脸。也就是说,如果不事先知道物体的形状,就会发现问题中存在固有的模糊性。图像中位置的像素强度是物体的基础形状、表面反射率和正常特征、相机参数以及场景照明和其他物体的排列组合的结果。因此,对于这个问题,可能有无限的解决方案。
• 即使使用现代的采集设备,在“in-the-wild”图像中学习3D人脸形状和纹理的统计先验也是非常困难的。也就是说,尽管3D采集设备有了很大的改进,但它们仍然不能在任意条件下运行。因此,目前所有的三维人脸数据库都在受控条件下被录制。
有了可用的3D面部数据,我们就可以学习一种强有力的面部形状统计模型,这一模型对特性和表达都很好。然而,我们不可能建立一种面部纹理的统计模型,这一模型能够很好地概括“野外”的图像,同时,与统计形状模型相对应。这就是为什么目前的国家艺术的3D人脸重建方法仅仅依靠在一组稀疏的landmarks 数据集前匹配一个统计三维面部形状。
在这篇论文中,我们做出了一些贡献,使得使用3DMMs进行“In -the-wild”面部重建,特别是我们的贡献是:
• 我们提出了一种从“野外”面部图像中学习统计纹理模型的方法,该模型与之前的统计形状完全相符,同时显示了身份和表达的变化。基于特性的成功(例如,HOG , SIFT)主动外观模型(AAMs),我们进一步展示了如何在3DMMs中学习基于特征的纹理模型。我们展示了使用“in-the-wild”特性的纹理模型的优点是,由于不需要对光照参数进行优化,所以拟合策略非常简单。
• 利用最近在拟合统计变形模型方面的进展,我们提出了一种新颖且快速的拟合“野生”3DMMs的算法。此外,我们将我们的算法实现公开,我们相信这对社区来说是很大的好处,这给了拟合3DMMs缺乏健壮的开源实现。
• 由于缺乏ground-truth 数据,大部分3D人脸重建论文只报告定性结果。在这篇论文中,为了提供定量评价,我们收集了一个新的三维面部数据集,使用Kinect Fusion,尽管它在室内被录制,但它具有许多“in-the-world”特征。
论文的其余部分结构如下。在第2节中,我们详细介绍了我们的“in-the-wild”3DMM的结构,同时在第3节中,我们概述了采用我们的模型拟合“In -the-wild”图像的优化建议。第4节描述了我们的新数据集,这是第一个数据集,它提供了具有许多“in-the-world”特征的地面真实三维面部形状的图像。我们在第5节中概述了一系列定量和定性的实验,并在第6节得出结论。
2. Model Training
3DMM由三个参数模型组成:形状、录像和纹理模型。
2.1. Shape Model
让我们用N个顶点3 N×1的向量表示一个物体的3 d网格(形状)
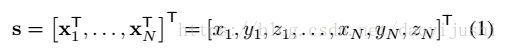
其中,![]() 是第 i 个顶点的笛卡尔坐标,通过将一套3D训练网格划分为密集的通信,可以构造一个三维形状模型,这样每一个都可以用相同数量的顶点来描述,并且所有的样本都有一个共享的语义排序。这些相应的栅格{si}然后通过应用Generalized Procrustes Analysis 和PCA后将被引进一个形态空间
是第 i 个顶点的笛卡尔坐标,通过将一套3D训练网格划分为密集的通信,可以构造一个三维形状模型,这样每一个都可以用相同数量的顶点来描述,并且所有的样本都有一个共享的语义排序。这些相应的栅格{si}然后通过应用Generalized Procrustes Analysis 和PCA后将被引进一个形态空间![]() , 其中
, 其中![]() 是平均形状向量,
是平均形状向量, ![]() 是在保留了第一个
是在保留了第一个![]() 主成分后的标准正交基,该模型可用于生成新的三维形状实例通过利用函数:
主成分后的标准正交基,该模型可用于生成新的三维形状实例通过利用函数:![]()

2.2. Camera Model
相机模型的目的是绘制(项目) 在图像平面上将以物体为中心的三维网格实例的笛卡尔坐标映射为二维笛卡尔坐标。在这项工作中,我们采用了针孔相机模型。 利用一个透视变换。然而,正投影模型也可以用同样的方法进行应用。
Perspective projection: 将三维点x =[x,y,z]T在图像平面x′= (x′,y′)T投影到2维坐标涉及两个步骤。首先,该3D点是旋转的和用线性视图转换了的。 假设相机是静止的:
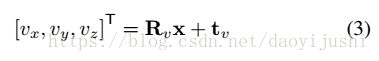
![]() 和
和![]() 分别是3D旋转和转换组件。然后应用了一个非线性透视变换:
分别是3D旋转和转换组件。然后应用了一个非线性透视变换:
