关系抽取的论文收集
找了ACL NACL EMNLP这两年的一些关系抽取的论文
- Neural Relation Extraction with Selective Attention over Instances(16年,典型模型)
代码:(https://github.com/thunlp/NRE.)
运用attention机制来尽量减轻错误label的负面影响;
运用CNN将关系用sentence embedding的语义组合来表示,以此充分利用训练知识库的信息。
讲解参考:https://blog.csdn.net/xg123321123/article/details/53218870
给出了一组句子{x_1……x_n}和两个对应的实体,我们的模型测量每个关系r的概率。在本节中,我们将在两个主要部分介绍我们的模型:
句子编码器:给定一个句子x和两个目标实体,卷积神经网络(RNN)用于构造句子的分布式表示x。
对实例的选择性注意:当学习所有句子的分布向量表示时,我们使用句子层次的注意来选择真正表达对应关系的句子。
句子编码器:

图1 一种用于句子编码器的CNN/PCNN结构
如图1所示。通过CNN将语句x变换为其分布式表示X。首先,将句子中的词转化为密集的实值特征向量. 接下来,使用卷积层、最大合并层和非线性变换层来构造语句的分布式表示。接下来,使用卷积层、最大池化层和非线性变换层来构造语句的分布式表示。
输入表示:CNN的输入是句子x中原始的词。我们首先把单词转换成向量。通过词嵌入矩阵将每个输入词转换成一个向量。此外,要指定每个实体对的位置,我们还使用句子中所有单词的位置嵌入。
ACL2017
1.Deep Residual Learning for Weakly-Supervised Relation Extraction
模型: 9层CNN卷积+深度残差学习(github上有源代码)
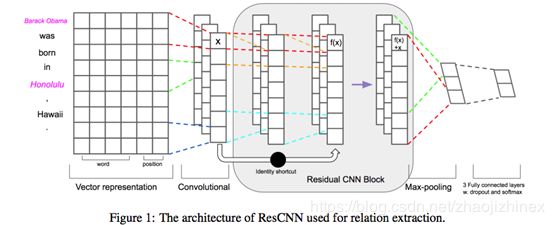
简介:
关系抽取是一个重要的课题。以前也有很多paper用CNN进行提取特征,不过他们大多只用了很浅的CNN(大部分都只有一层convolution layer+1 FC 层)。并没有人研究深层CNN好不好用。
本文中,我们研究了深层CNN用于远程监督的RE(relation extraction 后面也用简写)问题。具体来说,本文使用residual learning,word embedding 和 position embedding作为模型的输入,并使用identity feedback研究RE问题。实验室用NYT数据集,效果非常好(和所有CNN模型相比)。
2.Learning with Noise: Enhance Distantly Supervised Relation Extractionwith Dynamic Transition Matrix
模型:
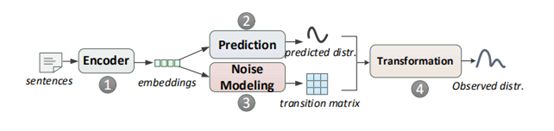
1,2跟以前的方法一致:对一个句子encode, 然后分类,得到一个句子的关系distribution。同时,3为模型动态地产生一个transition matrix T, 用来描述噪音模式。4就是将2,3的结果相乘,得到最终结果。
换句话说,在训练阶段,使用4的输出结果,作为加噪输出和标签匹配,也就是training loss使用的是4的输出结果和训练数据的标签进行计算。而在泛化阶段,使用的是2的输出结果。
简介:用一个噪音矩阵来拟合噪音的分布,即给噪音建模,从而达到拟合真实分布的目的。
动态转移矩阵能够有效地表征远程监督训练数据中的噪声。利用一种新的基于课程学习的方法可以有效地训练过渡矩阵,而不需要对噪声进行直接的监督。
讲解参考:https://zhuanlan.zhihu.com/p/36527644
https://blog.csdn.net/tgqdt3ggamdkhaslzv/article/details/78974736
本文中,作者使用一种对噪音数据显式建模的方法。尽管噪音数据是不可避免的,但是用一种统一的框架对噪音数据模式进行描述是可能的。作者的出发点是,远程监督数据集中通常会有对噪音模式有用的线索。比如说,一个人的工作地点和出生地点很有可能是同一个地点,这种情形下远程监督数据集就很有可能把born-in和work-in这两个关系标签打错。本文使用的方法是,对于每一个训练样本,对应一个动态生成的跃迁矩阵(transition matrix)。这个矩阵的作用是:对标签出错的概率进行描述和标示噪音模式
由于对于噪音模式没有直接的监督,作者使用一种课程学习的训练方法逐渐训练模型的噪音模式,并使用迹正则(trace regularization)来控制transition matrix在训练中的行为。本文的方法很灵活,它不对数据质量做任何假设,但可以在这样的线索存在的时候,有效利用数据质量先验知识来指导学习的过程。
本文主要创新点:使用dynamic transition,使用课程学习训练模型
3.Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme
简介:提出了一种新型的序列标注方案,将联合抽取问题转换为序列标注问题。并且,将这种方案应用于多种end-to-end模型(使用端到端模型,而不是先进行命名实体识别,NER,再进行关系抽取),比较这些模型的性能。本文还提出了一种新的模型。
模型:新标注方案&基于LSTM的end-to-end模型来解决联合抽取实体和关系的任务
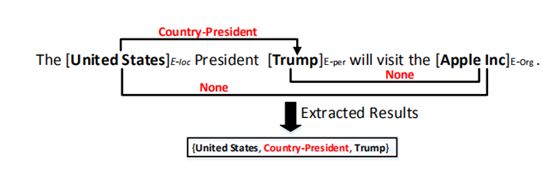
如图所示,模型的输入一句非结构化的文本,输出为一个预定关系类型的三元组。
为了实现该任务,作者首先提出了一种新的标注模式,将信息抽取任务转化为序列标注任务。如下图所示:

这种标注模式将文本中的词分为两类,第一类代表与抽取结果无关的词,用标签”O”来表示;第二类代表与抽取结果相关的词,这一类词的标签由三部分组成:当前词在entity中的位置-关系类型-entity在关系中的角色。作者使用“BIES”(Begin,Inside,End,Single)标注,来表示当前词在 entity中的位置。而关系类型则是从预先设定的关系类型集中获得的。entity 在关系中的角色信息,用“1”,“2”来表示。其中“1”表示,当前词属于三元组(Entity1,RelationType,Entity2)的 Entity1,“”同理”2”表示当前词属于 Entity2。最后根据标注结果将同种关系类型的两个相邻顺序实体组合为一个三元组。例如:通过标注标签可知,“United”与“States”组合形成了实体“United States”,实体“United States”与实体“Trump”组合成了三元组 {United States, Country-President, Trump}。如果一个句子中包含两个或者更多相同关系类型的三元组,我们基于最近原则将两个实体组合为三元组。本篇论文只考虑一个实体只属于一个三元组的情况。
End-to-end模型
当输入为文本语句的时候,为了自动实现对文本词序列的标注工作,作者提出了一个端到端的模型来实现了该工作。模型结构如下图

其中:
词嵌入层将每个词的 one-hot 表示向量转化为低维稠密的词嵌入向量(维度为 300) ;
Bi-LSTM 编码层(层数为 300)用于获得词的编码信息;
LSTM 解码层(层数为 600)用于产生标签序列。其中加入偏移损失来增强实体标签的关联性。
讲解参考:
https://zhuanlan.zhihu.com/p/31003123
https://www.jianshu.com/p/821e89f9ad66
ACL 2018
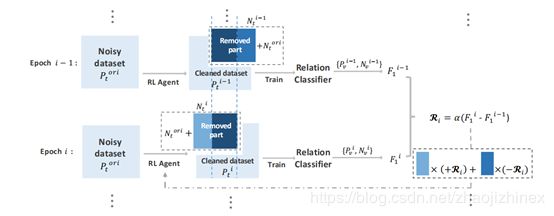
4. Robust Distant Supervision Relation Extraction via Deep Reinforcement Learning
简介:远程监控的代价是所得到的远距离监督的训练样本往往有很多噪音。为了对抗噪音,最近大多数现有的方法集中在选择一个最好的句子或计算一个特定实体对的句子集上的软注意力权重。然而,这些方法都是次优的,false positive问题仍然是影响性能的关键瓶颈。我们认为,那些标记不正确的候选句子必须用硬性决策来处理,而不是用软的注意力权重来处理。为了做到这一点,我们探索了一种深度强化学习策略来生成false positive指标,在该策略中,我们会自动识别任何关系类型的false positive,不需要任何监督信息。不同于以往研究中的去除操作,我们将它们重新分配到负面的例子中。
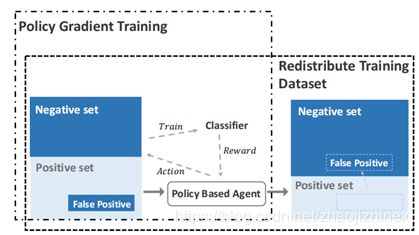
我们的深层强化学习框架旨在动态识别false positive样本。并在远程监督中将它们从正集转移到负集。
本文研究了利用动态选择策略进行鲁棒远程监控的可行性。更具体地说,我们设计了一个深度强化学习代理,其目的是学习根据关系分类器的性能变化选择是否删除或保留远程监督的候选实例。直觉上,我们的代理希望删除false positive,并重建一组清理过的远程监督的实例,以基于分类准确性最大化重建。该方法与分类器无关,适用于现有的任何远程监控模型.
提出了一种新的鲁棒远程监督关系提取的深度强化学习框架。
我们的方法是独立于模型的,这意味着它可以应用于任何最先进的关系提取器。
5.A Walk-based Model on Entity Graphs for Relation Extraction
简介:提出了一种新的基于图的神经网络关系提取模型.我们的模型同时处理句子中的多对,并考虑它们之间的交互作用。句子中的所有实体都作为节点放置在一个完全连通的图结构中。边由实体对的position-aware contexts表示。为了考虑两个实体之间不同的关系路径,我们构造了每对实体之间的l-length walks。由此产生的walks被合并,并不断更新将边用更长的walks表示。在ACE 2005 dataset上表现出不错的性能,未加其他方法。

本文说一对entity pair之间的关系会被相同句子中的其它关系影响,比如上图,Toefting(person entity)通过with直接与teammates(person entity)产生关系,而teammates又通过with与capital(geopolitical entity)直接产生关系。而Toefting和capital又可以直接通过in或者间接通过teammates产生关系。也就是说Toefting-teammates-capital这条path对Toefting-capital的关系是有帮助的。
模型:
讲解参考:https://blog.csdn.net/qq_37014750/article/details/83386852
6.Ranking-Based Automatic Seed Selection and Noise Reduction for Weakly Supervised Relation Extraction
简介:
- 创造性的将关系提取中的自动选种和数据降噪任务转换成排序问题;
- 提出多种既可用于 Bootstrapping 关系提取自动选种,又能用于远程监督关系提取降噪的策略;
- 在收集自 Wikipedia 和 ClueWeb 的数据集上,通过实验证实提出的算法的实用性和先进性。
讲解参考:https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/83542782
EMNLP2017
7.End-to-End Neural Relation Extraction with Global Optimization
简介:然而,以往使用统计模型进行的工作表明,与局部分类相比,全局优化可以获得更好的性能。为了更好地学习上下文表示,我们建立了一个全局优化的端到端关系提取神经模型,提出了新的LSTM特征。此外,我们还提出了一种新的句法信息集成方法,以便于全局学习,但对语法的背景要求较低,易于扩展。
讲解参考:https://blog.csdn.net/appleml/article/details/78390210(这个没太懂啥意思)
8.Incorporating Relation Paths in Neural Relation Extraction
简介:提出了对文本中的关系路径进行建模,结合 CNN 模型完成关系抽取任务。
传统基于 CNN 的方法,通过 CNN 自动将原始文本映射到特征空间中,以此为依据判断句子所表达的关系

这种 CNN 模型存在的问题是难以理解多句话文本上的语义信息。比如说 A is the father of B. B is the father of C. 就没法得出 A 和 C 的关系,基于此,论文提出了在神经网络的基础上引入关系路径编码器的方法,其实就是原来的 word embedding 输入加上一层 position embedding,position embedding 将当前词与 head entity/tail entity 的相对路径分别用两个 vector 表示。然后用 αα 来平衡 text encoder(E) 和 path encoder(G)。

Encoder 还采用了多样例学习机制(Multi-instances Learning),用一个句子集合联合预测关系,句子集合的选择方法有随机方法(rand),最大化方法(max, 选最具代表性的),选择-注意力机制(att),注意力机制的效果最好。
讲解参考:https://www.leiphone.com/news/201708/3bt3QcwNF3o1o3aA.html
9.A Soft-label Method for Noise-tolerant Distantly Supervised Relation Extraction
简介:以前的语句级降噪模型并没有达到令人满意的性能,因为它们使用硬标签,这些标签是在培训期间由遥远的监督和不可变确定的。为此,我们提出了一种实体对级去噪方法,该方法利用正确标注的实体对中的语义信息,在训练过程中动态地纠正错误的标签。我们提出了一种联合评分函数,其结合基于实体对表示的关系分数和硬标签的置信度,以获得针对特定实体对的新标签,即软标签。在训练期间,软标签代替硬标签成为金标签。在基准数据集上的实验表明,我们的方法显着地减少了噪声实例,并且优于最先进的系统。
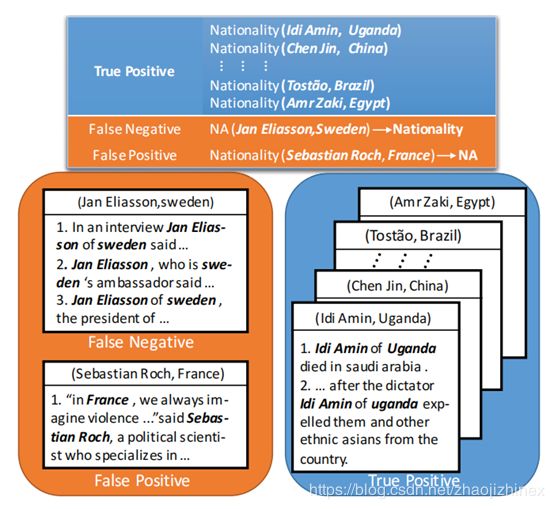
关于Nationality关系的软标签更正的一个例子。我们打算使用正确标记的实体对(蓝色)的句法/语义信息来纠正训练中的false positive和false negative实例(橙色)。
为了更好地了解我们的知识,我们首先提出了一种实体对级别的抗噪方法,而以前的工作只专注于句子级的噪声。
我们提出了一种简单而有效的方法,称为软标签法,用于在训练过程中动态纠正错误标签。
EMNLP2018
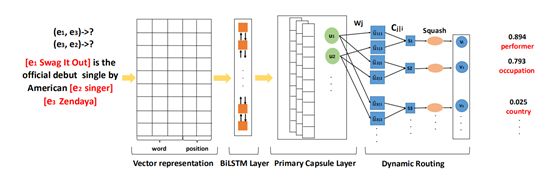
10. Attention-Based Capsule Networks with Dynamic Routing for Relation Extraction
简介:胶囊是一组神经元,其活动向量表示特定类型实体的实例化参数。在本文中,我们探索了用于多实例多标签学习框架中的关系提取的胶囊网络,并提出了一种基于具有注意机制的胶囊网络的新型神经网络方法。
模型:Attention-Based Capsule Networks
11.RESIDE: Improving Distantly-Supervised Neural Relation Extraction using Side Information(有代码)
简介:提出了一种远程监控神经关系提取方法,它利用KBs中的附加边信息来改进关系提取。它使用实体类型和关系别名信息在预测关系时施加软约束。Reside使用图形卷积网络(GCN)从文本中对语法信息进行编码,并在有限的边信息可用时提高性能。
我们提出了一种新的神经网络方法RESIDE ,它利用知识库的附加监督,以原则性的方式改进远程监督的RE。
RESIDE使用图形卷积网络(GCN)对句法信息进行建模,并且即使在有限的辅助信息的情况下,它也具有竞争力。
数据集和RESIDE源码:http://github.com/malllabiisc/RESIDE.
模型:RESIDE

- Syntactic Sentence Encoding:Reside在连接的位置和单词嵌入上使用Bi-GRU来编码每个令牌的本地上下文。为了捕获远程依赖,使用依赖树上的GCN,并将其编码附加到每个令牌的表示中。最后,对令牌的关注用于压制不相关的令牌,并获得对整个句子的嵌入。更多细节见5.1节。
- Side Information Acquisition:在这个模块中,我们使用了来自KBs的额外监督,并使用开放的IE方法来获取相关的边信息。模型稍后将使用这些信息,如5.2节所述。
- Instance Set Aggregation:在本部分中,将句法编码器的句子表示与上一步得到的匹配关系嵌入连接起来。然后,使用注意重于句子,学习整个包的表示。然后,在将实体类型嵌入到softmax分类器中进行关系预测之前,将其与实体类型连接起来。更多细节请参阅5.3部分。
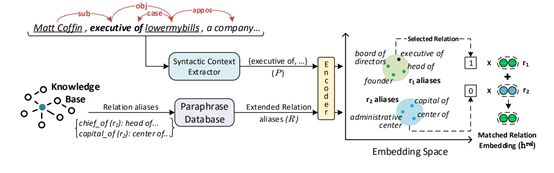
给定句子的关系别名侧信息提取。首先,句法上下文抽取器识别目标实体之间的相关关系短语P。然后,在嵌入空间中将它们与KB中的关系别名扩展集R相匹配。最后,将与最近别名对应的关系嵌入作为关系别名信息。
讲解参考:https://blog.csdn.net/imsuhxz/article/details/83748905
12.Improving Distantly Supervised Relation Extraction using Word and Entity Based Attention
(上一篇里面的其中一个对照模型BGWA)
简介:首先,我们提出了两种用于二次监督关系提取的新的词注意模型:(1)基于双向门控递归单元(Bi-GRU)的词汇注意模型(BGWA)。(2)以实体为中心的注意模型(EA);(3)利用加权投票法将多个互补模型相结合的组合模型,以改进关系提取。
其次,我们介绍了GDS,一种用于关系提取的新的远程监督数据集。 GDS消除了所有先前远程监控基准数据集中存在的测试数据噪声,使得可靠的自动评估成为可能
第三,通过对多个现实世界数据集的广泛实验,证明了所提出的方法的有效性。
模型:Bi-GRU word attention (BGWA) model
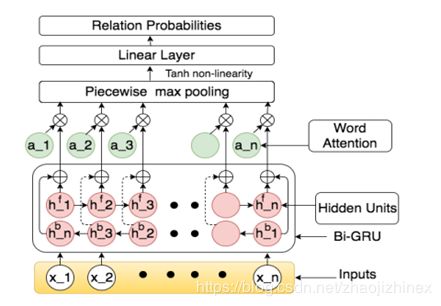
Entity Attention (EA) Model

13. Neural Relation Extraction via Inner-Sentence Noise Reduction and Transfer Learning
基于内句降噪和迁移学习的神经关系提取
简介:本文做知识图谱中的关系抽取的,创新点有三个:
- 通过Sub-Tree Parse (STP)来移除句子内的噪音的,还可以降低句子长度。
- 通过entity-wise attention来帮助句子捕捉句子内的重点的。
- 通过迁移学习,在entity type分类上预训练后,再迁移到关系分类的任务上帮助模型提高鲁棒性。
模型:
该模型的总体结构用于远程监督关系提取,表达了处理实例的过程。详细描述了两个模块:(A)一个是BGRU;(B)另一个是STP,红括号中的单词代表实体。
Sub-Tree Parser 每个实例都放入依赖关系解析模块,以便首先构建依赖关系解析树。然后,我们可以根据STP方法对句子进行裁剪。最后,通过嵌入矩阵将每个实例的字标记和位置标记转换为分布式表示。
讲解参考:https://blog.csdn.net/manmanxiaowugun/article/details/85636278
14.Graph Convolution over Pruned Dependency Trees Improves Relation Extraction
简介:提出一种用于关系提取的图卷积网络变体
依赖树帮助关系提取模型捕捉词之间的长期关系. 然而,现有的基于依赖性的模型要么通过过于积极地修剪依赖树而忽略关键信息(例如,否定),要么计算效率低,因为难以在不同树结构上并行化。我们提出了一种适合关系抽取的图卷积网络的扩展,它可以并行地在任意依赖结构上有效地聚集信息。为了在最大限度地去除不相关内容的同时合并相关信息,我们进一步将新的修剪策略应用于输入树,方法是将字紧靠在两个实体之间的最短路径周围保持关系。通过详细的分析表明,该模型与序列模型具有互补的优势,并结合它们进一步提高了模型的发展水平。

从TACKBP挑战语料库中修改的示例。还显示了主题(“he”)和对象(“Mike Cane”)之间的原始UD依赖树的子树,其中,实体之间的最短依赖路径以粗体突出显示。请注意,否定(“Not”)离开了依赖路径。
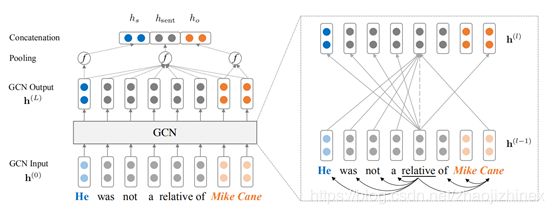
用图卷积网络进行关系提取。左侧显示整体架构,而右侧则只显示“relative”一词的详细图卷积计算,以求清晰。本文还提供了一个完整的、未标记的句子依赖解析,以供参考。
15.N-ary Relation Extraction using Graph State LSTM(使用图状态LSTM的N元关系提取)(N元提取不确定用不用,存个标题)
16.Multi-Level Structured Self-Attentions for Distantly Supervised Relation Extraction
简介:在远监督关系提取(DSRE)中,深层神经网络中经常使用注意机制来区分有效的和有噪声的实例。然而,传统的1-D矢量注意力模型不足以在选择有效实例来预测实体对的关系的情况下学习不同的上下文。为了缓解这个问题,我们在使用双向递归神经网络的多实例学习(MIL)框架中为DS-RE提出了一种新颖的多层结构(2-D矩阵)自注意机制。在所提出的方法中,结构化的单词级自我关注机制学习2-D矩阵,其中每个行向量表示关于两个实体的实例的不同方面的权重分布。针对MIL问题,结构化句子级注意学习一个二维矩阵,其中每个行向量表示在选择不同有效实例时的权重分布。

17.Extracting Entities and Relations with Joint Minimum Risk Training联合最小风险培训提取实体和关系(联合抽取)
NAACL2018
18.Joint Bootstrapping Machines for High Confidence Relation Extraction
简介:我们介绍了BREX,一种新的自举方法,通过高效的置信度评估来防止false positive这种污染。这是通过联合使用实体和模板种子(与之前的工作中只有一个相反),通过在每次迭代中并行地以相互约束的方式扩展实体和模板并通过为模板引入更高质量的相似性度量来实现的。
19.Global Relation Embedding for Relation Extraction
简介:附加方法。我们提出将文本关系与全局关系统计相结合,即从整个语料库收集的文本关系和知识库关系的共现统计。该方法对远程监控引入的训练噪声具有更强的鲁棒性。在一个流行的关系抽取数据集上,我们证明了学习到的文本关系嵌入可以用来扩充现有的关系提取模型,并能有效地提高它们的性能。最值得注意的是,对于现有的最优模型发现的前1,000个关系事实,精度可以从83.9%提高到89.3%。

远程监控中的错误标注问题,以及如何利用全球统计数据与之作斗争。左:常规远程监督。每个文本关系都将被标记为两个KB关系,而只有一个是正确的(蓝色实心线)。另一个是错误的(红色虚线)。右:远程监督全局统计。这两种文本关系可以通过KB关系的共现分布来明确区分.

关系图。左节点集是文本关系,右边节点集是KB关系。对原始共现计数进行归一化,使得对应于相同文本关系的KB关系形成有效的概率分布。边用文本关系着色,用归一化共现统计量加权.