【梳理】简明操作系统原理 第七章 线程和锁(内附文档高清截图)
参考教材:
Operating Systems: Three Easy Pieces
Remzi H. Arpaci-Dusseau and Andrea C. Arpaci-Dusseau
在线阅读:
http://pages.cs.wisc.edu/~remzi/OSTEP/
University of Wisconsin Madison 教授 Remzi Arpaci-Dusseau 认为课本应该是免费的。
————————————————————————————————————————
这是专业必修课《操作系统原理》的复习指引。
在本文的最后附有复习指导的高清截图。需要掌握的概念在文档截图中以蓝色标识,并用可读性更好的字体显示 Linux 命令和代码。代码部分语法高亮。
操作系统原理不是语言课,本复习指导对用到的编程语言的语法的讲解也不会很细致。如果不知道代码中的一些关键字或函数的具体用法,你应该自行查找相关资料。
七 线程和锁
1、第一章我们介绍过进程。现在我们介绍一种新的抽象:线程(thread)。一个多线程的程序有多个程序计数器(PC),每个PC指向一个线程的下一条准备执行的指令。线程很像进程,不过线程与进程的区别是:一个进程的全部线程共用一个进程的地址空间,而且都可以访问该进程的全部数据。可以把线程看作轻量级的进程。虽然用多线程可以做到的事,用多个进程来做也可以,但是线程之间共用地址空间,因此更容易分享需要共用的数据。进程之间的数据一般是很少共享的。
2、每个进程都要有自己的寄存器,因此在单个CPU核心上通过上下文切换选择不同的线程来执行时,也要将当前线程的寄存器数据保存在线程控制块(thread control block,TCB)中。同样,TCB还要保存线程的其它状态信息,以确保在切换回原线程时能够顺利恢复进度并继续执行。但是切换线程时,地址空间不变。
3、每个线程都要有自己的栈,因此一个多线程的进程含有多个栈,用于保存各个线程自己的局部变量、函数参数和返回值等。但是一个多线程的进程一般只有一个堆。
4、引入线程的原因至少有两个:一是对并行(parallel)执行的要求。二是为了防止进程请求IO时打断本可以继续执行的任务:如果一个进程有多个线程,可以用其中一个线程发起IO请求,剩下的线程继续进行计算,也可以准备请求或同时请求新的IO。于是当一个线程被阻塞时,CPU就可以调度该进程的其它线程继续在当前核心上执行。Web服务器、DBMS(数据库管理系统)等服务器级大型应用几乎无一例外地充分进行了多线程优化。
5、运行下面的代码若干次:
#include
#include
#pragma warning(disable:4996)
using std::thread;
inline void f(const char* _Str) { puts(_Str); }
int main() {
thread t1(f, “A”), t2(f, “B”);
t1.join(); t2.join();
return 0;
}
虽然输出"A"的线程t1的创建总是先于输出"B"的线程t2,但是输出结果并不总是保持相同:
(注:在Linux下,运行g++ demo.cpp -o demo -O2 -m64 -std=c++1y -pthread进行编译)
线程开始执行或执行完毕的次序与其创建顺序无关。
运行下面的代码若干次:
#include
#include
#pragma warning(disable:4996)
using std::thread;
volatile unsigned c = 0;
inline void f(const char* _Str) {
printf("%s: Begin.\n", _Str);
for (unsigned i = 0; i < 1e8; ++i)++c;
printf("%s: End.\n", _Str);
}
int main() {
puts(“Main: Begin.”);
thread t1(f, “A”), t2(f, “B”);
t1.join(); t2.join();
printf(“Main: End. c = %u\n”, c);
return 0;
}
(volatile关键字修饰的变量在被访问时必须老老实实从内存中访问,不能对需要访问该变量的代码进行优化(例如:将上一次读取的该变量的值保存到寄存器,下次读取时直接使用寄存器中的保存结果而不管其在内存中的值是否已改变))
你应该会认为c的值在最终输出时一定是200 000 000。但是:
连最终输出的值也无法确定!这中间发生了什么呢?
过程f的循环部分的汇编代码大概是这样的:
mov 0x8049a1c, %eax
add $0x1, %eax
mov %eax, 0x8049a1c
变量c位于0x8049a1c中,它在循环中会先被放到eax里,然后增加1,再把寄存器eax的值放回内存中去。
假设线程1开始执行时,c = 50。它将c移到eax中,然后递增1。但是这时定时器中断引发了上下文切换,于是eax的值被保存到线程1的TCB中,线程1暂停。而后,线程2开始运行。它先将c移到eax中,但此时线程2获得的c的值是50而不是51。这次线程2能够在定时器中断到来前执行完一次循环,将eax中的值写回到内存,此时c = 51。下一次又轮到线程1运行了,它从上次中断的位置开始继续执行,将线程1暂停执行时eax的值写回内存,此时c = 51。可以看出,其实c应该被增加2次,值为52;但实际上只增加了1次,值为51。
多线程的情况下,对共享资源进行混乱操作,导致整个处理过程变得混乱。这种情况称为竞争条件(race condition)。这导致了计算机的计算结果不再是可确定的。如果用多个线程执行同一段代码会导致竞争条件,就称这段代码所在的位置为临界区(critical section)。也就是说,临界区中的代码是一段访问共享资源的代码。为了避免这种情况,不允许多个线程同时执行临界区的代码。换个说法就是互斥(mutual exclusion,mutex):临界区的代码被一个线程执行时,它不允许被其它线程执行。
6、原子操作(atomic operations)是建设强大而可靠的计算机系统必不可少的一种思想。无论是我们刚才讨论和后续将讨论的简单代码中,还是在文件系统(将在后续章节学习)、DBMS(数据库管理系统)乃至分布式系统(distributed system)里,都充分体现了这种思想。“原子的”(atomic)一词简单解释为“All or nothing”,也就是说一个原子动作要么将其执行完毕,要么不要执行。将一系列指令组合为原子操作后,就称为事务(transaction)。这是数据库并发中的最基本的概念之一。一个事务中的一系列指令,要么全部执行完毕,要么不能开始执行;如果尚未执行完毕而发生故障,则需要撤销(undo)已经进行的操作。
第6点中的代码如果要正确执行,那么就要将一次循环包含的3条汇编指令视为一个原子操作。当中断发生时,不能暂停执行该操作,而是待其执行完毕后再处理中断(切换到其它线程)。硬件提供了同步原语(synchronization primitives)的支持。在硬件与操作系统的支持下,可以将一系列操作合并为原子操作。
7、为了整体执行临界区的操作,需要用到锁(lock)。锁是一种变量,用于刻画锁的状态。一个锁要么不被进程使用(称为可用(available)、解锁(unlocked)或空闲(free)),要么在一个线程执行临界区的代码时被该线程独占(称为acquired,locked或者held)。锁变量还可以保存其它的信息,例如占用该锁的线程,或者等待获得该锁的线程队列。当然这些在锁这个类中不是公有成员,对用户不可见。
8、为了考察一个锁是否能正确、高效地发挥作用,有必要建立相应的评估准则。
第一个评价标准是互斥。换句话说,就是要考察一个锁是否确实能阻止其它进程访问正在被执行的临界区。
第二个评价标准是公平。意即每一个请求获得锁的进程是否总能获得这个锁(即不会饥饿)。
第三个评价标准是性能。考察标准分成单线程、单核心多线程和多核心多线程三种情况。
9、早期的单核计算机中,进程获得锁和释放锁时,分别通过调用硬件指令禁用中断和启用中断来实现。这个方法非常简单,但有许多缺点。首先,禁用和启用中断显然是特权级指令。如果我们要让程序可以实现锁的功能,那么就要允许它们调用特权指令。这自然是很危险的:一个恶意程序可以在获得锁后开始跑一个死循环,于是它就成功霸占了全部CPU时间。其次,禁用和启用中断是对单个CPU核心控制的。如果CPU有多个核心,仍然可以通过其它核心来访问该临界区。此外,禁用中断期间如果其它硬件请求了中断,这些中断就会丢失,这将会导致非常严重的问题:例如在禁用中断期间,硬盘完成了一个读取操作,向CPU发出相应中断。如果这个中断丢失了,那么OS怎样得知何时应该让因为请求读磁盘而被阻塞的进程继续执行呢?并且,中断的开启关闭(屏蔽或解除屏蔽)操作在CPU上执行起来比一般的指令要慢。
所以,禁用中断只在非常少的情况下使用。例如OS在维护自己的数据结构期间会屏蔽中断。这也在一定程度上阻止了处理中断带来的一些问题。
10、有没有其它的方法实现锁?也许可以尝试用专门的标记位来标记锁。当一个线程准备进入临界区时,调用上锁的命令,标记为置位。当从临界区退出后,调用释放的命令,标记位复位。这期间,如果另一个进程准备进入同一个临界区,就要通过忙等待来检测锁的标记为是否为零。只有为零的时候,才可以继续执行。忙等待的代码大致是:
while(flag) {}
这种办法有两个问题:第一个是正确性。设想有一段程序是这样的:
lock();
while (flag) {}
flag = 1;
//Go into the critical section…
首先尝试获得锁。如果这个锁目前空闲(标记位为0),那么该线程成功获得该锁,忙等待的while循环跳过,直接设置标记位为1,此时开始其它线程将不能进入该临界区,临界区只能由获得相应的锁的线程执行。
但是,如果在线程1把标记为设为1之前,调度器就将其暂停并切换了另一个线程,而另一个线程又能在不被打断的情况下成功设置标记位为1并开始执行,那么当再次切换到线程1的时候,由于忙等待已经跳过,线程1实际上也可以进入同一个临界区执行。因此,这样实现的锁实际上连互斥都不能满足。
而且,忙等待会重复检测标记位,其对处理器的性能影响较大。并且,如果两个线程在同一个核心上轮流跑,而其中一个线程在忙等待另一个线程,那么被等待的这个进程反而还无法运行,直到下一次上下文切换。
这个实现方法是行不通的,必须换用其它方法。
11、1960年代的多处理器系统就具有了对锁的硬件支持。现在所有计算机都具备这种支持。只有软硬结合才能解决第10 点提到的软件实现的锁的正确性问题。
Test-and-set是硬件支持的锁机制,也称旋转锁(spin lock)。当一个线程尝试获得一个锁时,检测该锁是否空闲(返回检测结果)。如果空闲,则这个锁会同时被占用。也就是说,在硬件的支持下,检测一个锁是否为空闲和将空闲的锁占用这两个动作可以看成是同时进行的,是原子操作,不能被调度器中止。
我们用第8点给出的评价锁的三个原则来评估test-and-set机制是否正确且高效:
(1)正确性。Test-and-set只允许单个线程访问临界区,而且上锁过程不会像第10点中说的那样被调度器打断。
(2)公平性。如果只是简单实现旋转锁,其实不能保证公平:一个线程获得锁以后,可能会一直执行,直到执行完毕。
(3)性能。如果计算机是单核的,CPU时间会被严重浪费:因为当一个线程在占用临界区时,如果调度器切换了另一个尝试访问临界区的线程,那么这个线程在该时间片内只能进行忙等待,这个时间片就被浪费了。当然,如果计算机是多核的,且请求获得锁的线程数小于等于CPU的核心数,那么正在一个核心上访问临界区的线程与其它尝试获得锁的线程可以分配到不同的CPU核心上。虽然正在等待的线程依旧会浪费所在核心的CPU时间,但是至少没有拖累正在执行的线程的执行进度。
Test-and-set对应x86汇编中的xchg指令。C++11的头文件的std::atomic_flag中提供了这个机制。
12、另一种硬件支持的机制是compare-and-swap(SPARC平台),在x86平台上称为compare-and-exchange。这个指令也是原子的,并需要三个参数:目标内存地址、期望值、新值。运行这个指令时,检测指定的内存地址的值是否为期望的值。若是,则将其修改为指定的新值。若不是,不进行任何操作。
如果进程通过CAS指令尝试获得锁,那么可以把地址参数设为锁的地址,并把期望值设为0,新值设为自己的PID。如果指定地址的值不是0,意味着有进程在占用临界区。如果值为零,那么代表没有进程占用临界区,该进程获得锁,并修改锁变量的值为自己的PID。
13、CPU提供一对指令来构建临界区。MIPS架构的CPU的这对指令被称为load-linked和store-conditional。Alpha、PowerPC、ARM等平台也提供相近的指令。
Load-linked的功能很像一般的Load指令,从内存中取得一个值,然后存入寄存器。但是store-conditional指令只有在刚才load-linked指令读取的地址的值未被更新的时候才执行成功(更新该地址的值为指定的值)。
14、Fetch-and-add机制与compare-and-exchange类似,将目标地址的值自增(+1)的同时返回自增之前的值。
Fetch-and-add可以实现一种新的锁——票锁(ticket lock)。当一个线程想要获得一个锁时,就尝试一次fetch-and-add操作,将这个锁的ticket value增加1。每个线程自己有一个票面值。当锁的票面值与线程的票面值相同时,这个线程进入临界区。需要解锁时,线程将锁的票面值再增加1即可。
15、上面介绍的实现锁的方法都需要在尝试获得锁的线程未获得锁的时候进行忙等待,浪费CPU时间。有没有别的方法可以解决这个问题呢?答案是:让权等待。当线程尝试上锁失败后,立刻释放CPU,不要进行忙等待,让调度器调度其它的进程。让权等待是系统调用,调用的进程被从运行态设为就绪态,然后调度器选择另一个进程运行。这个过程叫做去调度(descheduling)。
16、Linux使用futex(fast userspace mutex)来实现锁机制。在一个线程尝试获得锁失败后,会先忙等待一个比较短的时间、若仍然无法获得锁,则进入睡眠(sleeping)状态(睡眠的线程不会被调度器选择运行,不占用CPU),直到该线程尝试获得的锁变为空闲时才唤醒该线程。
这种两段锁(two-phase lock)方案混用了不同的方法。生活中,混用不同的方案往往效果更好,例如混合制经济。
C++11开始,提供了互斥锁的实现,位于头文件中。
17、线程安全(thread safety),意味着当一个线程在修改为多个线程所共享的数据时,不会有其它线程可以修改这些共享的数据。
18、下面我们列举几个将单线程的数据结构并行化的简单例子,来体会利用锁来将代码正确并行化的可行方法和可能遇到的问题。
一个简易计数器的代码如下:
template class counter {
private:
_Ty value;
public:
counter() { value = 0; }
void increment() { ++value; }
void decrement() { --value; }
_Ty get() { return value; }
};
如何将锁应用到这个数据结构,来使其线程安全呢?一个最简单的想法是:当调用一个需要写入该数据结构的成员函数时,对需要修改的成员变量上锁,直到返回后再释放锁。
我们建立若干个线程,每个线程的任务都是一样的:给这个计数器增加同样多的计数。逐渐增加线程数,每个线程为计数器增加的计数不变,统计总的运行时间。
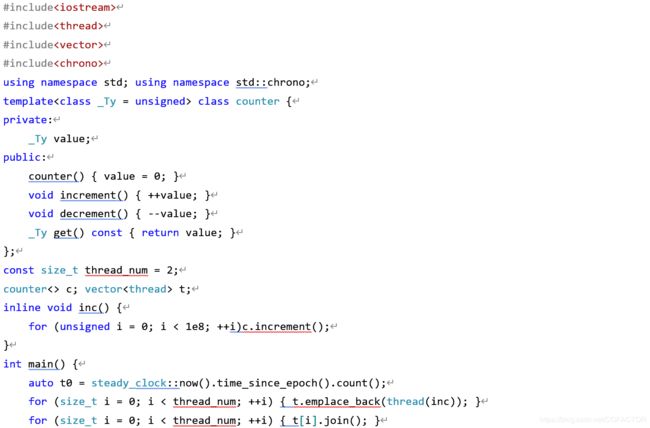
测试环境:Core i5-8400 2.80 GHz,,Windows 10 Pro,Visual Studio 2019,Release x64
测试代码:
#include
#include
#include
#include
using namespace std; using namespace std::chrono;
template class counter {
private:
_Ty value;
public:
counter() { value = 0; }
void increment() { ++value; }
void decrement() { --value; }
_Ty get() const { return value; }
};
const size_t thread_num = 2;
counter<> c; vector t;
inline void inc() {
for (unsigned i = 0; i < 1e8; ++i)c.increment();
}
int main() {
auto t0 = steady_clock::now().time_since_epoch().count();
for (size_t i = 0; i < thread_num; ++i) { t.emplace_back(thread(inc)); }
for (size_t i = 0; i < thread_num; ++i) { t[i].join(); }
auto t1 = steady_clock::now().time_since_epoch().count();
cout << "Duration = " << (t1 - t0) / 1e6 << "ms.\nThe value of the counter is " << c.get() << endl;
return 0;
}
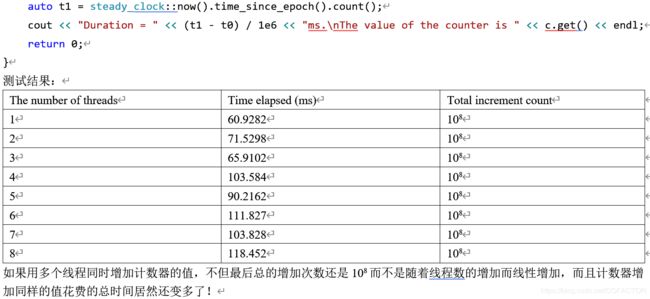
测试结果:
The number of threads Time elapsed (ms) Total increment count
1 60.9282 108
2 71.5298 108
3 65.9102 108
4 103.584 108
5 90.2162 108
6 111.827 108
7 103.828 108
8 118.452 108
如果用多个线程同时增加计数器的值,不但最后总的增加次数还是108而不是随着线程数的增加而线性增加,而且计数器增加同样的值花费的总时间居然还变多了!
如果增加线程数的同时让总的计数器增加次数不变,结果又如何呢?
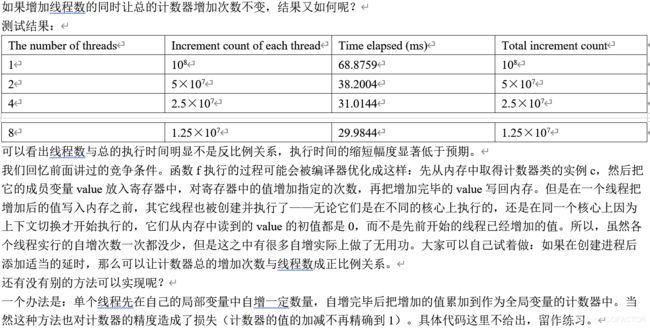
测试结果:
The number of threads Increment count of each thread Time elapsed (ms) Total increment count
1 108 68.8759 108
2 5×107 38.2004 5×107
4 2.5×107 31.0144 2.5×107
8 1.25×107 29.9844 1.25×107
可以看出线程数与总的执行时间明显不是反比例关系,执行时间的缩短幅度显著低于预期。
我们回忆前面讲过的竞争条件。函数f执行的过程可能会被编译器优化成这样:先从内存中取得计数器类的实例c,然后把它的成员变量value放入寄存器中,对寄存器中的值增加指定的次数,再把增加完毕的value写回内存。但是在一个线程把增加后的值写入内存之前,其它线程也被创建并执行了——无论它们是在不同的核心上执行的,还是在同一个核心上因为上下文切换才开始执行的,它们从内存中读到的value的初值都是0,而不是先前开始的线程已经增加的值。所以,虽然各个线程实行的自增次数一次都没少,但是这之中有很多自增实际上做了无用功。大家可以自己试着做:如果在创建进程后添加适当的延时,那么可以让计数器总的增加次数与线程数成正比例关系。
还有没有别的方法可以实现呢?
一个办法是:单个线程先在自己的局部变量中自增一定数量,自增完毕后把增加的值累加到作为全局变量的计数器中。当然这种方法也对计数器的精度造成了损失(计数器的值的加减不再精确到1)。具体代码这里不给出,留作练习。
19、对于链表,可以给每个节点都放置一个锁。修改第一个节点时把锁锁住;修改完毕时,先把下一个节点的锁锁住,再释放当前节点的锁。不过,由于这种方法频繁对锁操作,开销也是十分大的;也许可以令多个节点共用一个锁。在将代码并行化的时候,如果需要用到锁机制,务必考虑对锁的访问是否过多。特别是对一些非常底层的代码,尤其是数据结构,能够优化一点,对总体性能的提升也许就非常明显,因为这些代码的使用频率非常高。
20、对于队列,处理就稍微简单些。因为队列只在头尾进行操作,所以把头结点和尾结点各设一把锁即可。在初始化队列的时候,放一个空节点,且这个空节点始终在队列里。这样在队列无有效节点或只有一个有效的节点的时候,仍然可以对头尾同时进行修改操作。具体的实现同样留作练习。
21、对于哈希表,并行化就比较容易了,而且性能提升非常明显。哈希值相同的元素会被装在桶中,桶可以用链表或者平衡树实现。计算哈希的过程自然可以并行化。只要是对不同哈希值的元素进行操作(添加、删除),修改哈希表的过程也可以很容易做到独立进行、互不干扰。


#include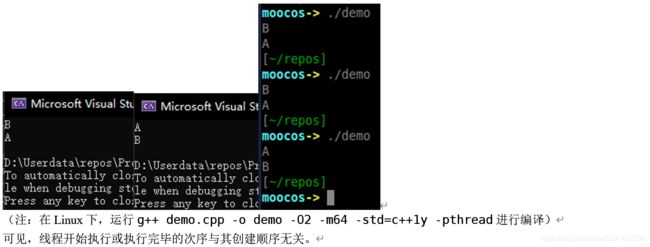

#include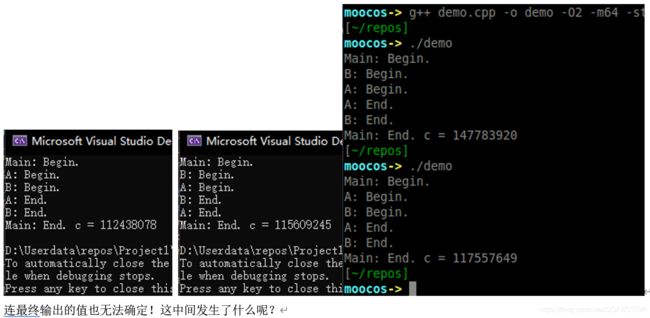







#include