【目标检测】算法梳理
目标检测20年综述之(一)
传统方法
VJ 检测器—检测人脸
方向梯度直方图(Histogram of Oriented Gradient, HOG)特征 从cell到bolck构造检测的特征向量
Deformable Part-based Model (DPM)利用HOG和SVM进行后续的分割、分类
候选区域/窗 + 深度学习分类
在深度学习时代,目标检测可以分为两类:two-stage和one-stage,前者是由粗到精的过程,而后者则一步到位。RCNN、Fast RCNN、ROI Pooling、Faster RCNN、YOLO、SSD、YOLO V2、YOLO V3、SSD V2、FCN较为经典的算法,需要熟知。
推荐阅读1:R-CNN系列与SPP-Net总结
推荐阅读2:一文读懂目标检测:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD
RCNN Regions with CNN features
论文解析推荐阅读
R-CNN的简要核心步骤如下,核心思想是分成:分类和回归
(1) 输入测试图像,利用选择性搜索Selective Search(这是个什么东西,说出来你看你不信,pip可以直接安装他,主要思想就是分割、贪心融合)算法在图像中从下到上提取2000个左右的可能包含物体的候选区域Region Proposal。
(3) 调整大小:因为取出的区域大小各自不同,所以需要将每个Region Proposal缩放(warp)成统一的227x227的大小并输入到CNN,将CNN的fc7层的输出作为特征
(4) 将每个Region Proposal提取到的CNN特征输入到SVM进行分类
(5) 使用回归器精细修正候选框位置:对于每一个类,训练一个线性回归模型去判定这个框是否框得完美。(Bounding-box回归,就是算出他的xyhw来确定这个框)
在测试阶段,最后用SVM分类好之后,会用针对每个类,通过计算 IoU(IoU=重叠面积 /(面积1+面积2-重叠面积)) 指标,然后采取非极大性抑制,以最高分的区域为基础,剔除掉那些重叠位置的区域。
提问:为什么不直接用softmax的输出结果?
因为在训练softmax的时候数据本来就不是很准确,而SVM的训练使用的是hard negative也就是样本比较严格,所以SVM效果会更好。
补充:非极大值抑制(Non-Maximum Suppression,NMS),顾名思义就是抑制不是极大值的元素,可以理解为局部最大搜索。这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二是邻域的大小。在RCNN中,目的是选出最好的那个框,常用的阈值是 0.3 ~ 0.5。推荐阅读
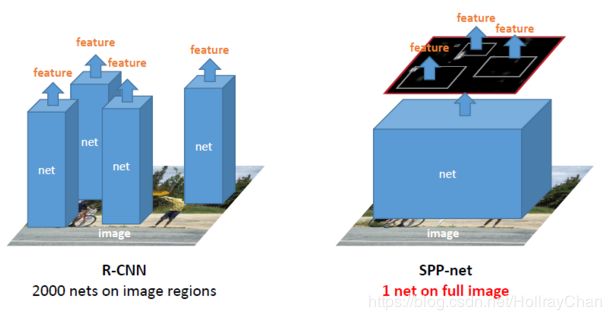
SPP Net(我有ROI Pooling,不要Selective Search,还要SVM)
SPP Net的第一个贡献就是在最后一个卷积层后,接入了金字塔池化层,保证传到下一层全连接层的输入固定。SPP Net在普通的CNN结构中加入了ROI池化层(ROI Pooling就是池化的一种,加在激活函数后面),使得网络的输入图像可以是任意尺寸的,输出则不变,同样是一个固定维数的向量。(不需要Region Proposal,神经网络帮你搞定这些候选区域,直接输入图片就完事了)。
spatial pyramid pooling layer:具体做法是,在conv5层得到的特征图是256层,每层都做一次spatial pyramid pooling。先把每个特征图分割成多个不同尺寸的网格,比如网格分别为44、22、11,然后每个网格做max pooling,这样256层特征图就形成了16256,4256,1256维特征,他们连(Concatinate)起来就形成了一个固定长度的特征向量,将这个向量输入到后面的全连接层。之后再将原图的proposal映射到到feature map。
不足:1.虽然解决了R-CNN许多大量冗余计算的问题,但是还是沿用了R-CNN的训练结构,也训练了SVM分类器, 单独进行BBox regression。2.SPP-Net 很难通过fine-tuning对SPP-layer之前的网络进行参数微调,效率会很低,原因具体是(Fast-RCNN中的解释): SPP做fine-tuning时输入是多个不同的图片,这样对于每一个图片都要重新产出新的feature map,效率很低,而Fast-RCNN对其进行了改进。
Fast R-CNN(ROI Pooling,Selective Search我都要,不要SVM)
推荐阅读:Fast RCNN算法详解
算法概述:Fast R-CNN还是用的Selective Search来提取region proposal,Fast R-CNN 将整个图片与通过Selective Search筛选出的region proposals一同输入(我全都用),经过卷积层、池化层产出feature map,计算出原图的proposal在feature map的映射,将相应的feature送到ROI pooling层,进行池化,产出固定长度的feature vector作为FC层(SVD分解实现,说白了就是得到包含重要信息的矩阵)的输入最终分支成两个兄弟输出层:一个通过softmax产生K+1个分类的概率,另一个对于每个object 类别输出四个实数,代表一个较为精确的BBox position,最后进行NMS得到最终的结果。
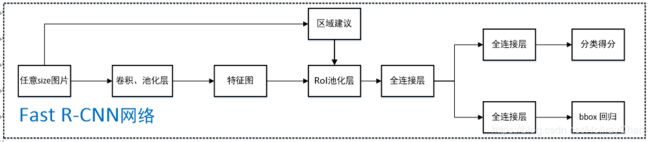
创新点:1.SVD分解实现FC层加速什么是SVD;2.在全连接层之前加了简化版的spp层
使用softmax进行预测概率而不是SVM:由于softmax在分类过程中引入了类间竞争,分类效果更好;(对于类间竞争,我的理解是softmax所有类的概率相加为1,一个类的概率变高,其他类的概率必然有所下降,这样即使论文中的competition between classes)。Fast R-CNN去掉了SVM这一步,所有的特征都暂存在显存中,就不需要额外的磁盘空间,省时省力。
Faster R-CNN(ROI Pooling,RPN替代Selective Search,不要SVM)
Faster R-CNN文章详细解读
算法概述:Faster R-CNN就此问题提出了使用RPN生成region proposal,然后再接上Fast R-CNN形成了一个完全的end-to-end的CNN对象检测模型,可以完全在GPU运行,同时RPN与后面的detection network 共享full-image convolutional features
RPN在预训练的网络模型生成的特征图(convolutional feature map )上滑动一个小网络(slide a small network),这个网络把特征图上的一个n x n窗口(文章中n=3)的特征作为输入,对于每个窗口,以窗口的中心点作为基准,通过不同(文章中9个)的anchors映射到原图从而得到一个个proposals,之后通过对这些proposal进行softmax分类与BBox regression的学习,从而输出调优后的proposal with score。
ROI Pooling层 补充:
ROI Pooling层:Pooling层的一种,输入特征图尺寸不固定,但是输出特征图尺寸固定,最大的好处就在于降低了参数量,极大地提高了处理速度。
- ROI Pooling的输入 输入有两部分组成:
- 特征图:指的是图1中所示的特征图,在Fast RCNN中,它位于RoI Pooling之前,在Faster RCNN中,它是与RPN共享那个特征图,通常我们常常称之为“share_conv”;
- rois:在Fast RCNN中,指的是Selective Search的输出;在Faster RCNN中指的是RPN的输出,一堆矩形候选框框,形状为1x5x1x1(4个坐标+索引index),其中值得注意的是:坐标的参考系不是针对feature map这张图的,而是针对原图的(神经网络最开始的输入)
ROI Pooling的输出
输出是batch个vector,其中batch的值等于RoI的个数,vector的大小为channel * w * h;RoI Pooling的过程就是将一个个大小不同的box矩形框,都映射成大小固定(w * h)的矩形框;
基于深度学习的回归方法
一步走(one-stage)算法:直接对输入图像应用算法并输出类别和相应的定位(YOLO系列)
推荐阅读:YOLO目标检测从V1到V3结构详解
YOLO
(CVPR2016, oral)论文解析阅读传送门1
论文解析阅读传送门2
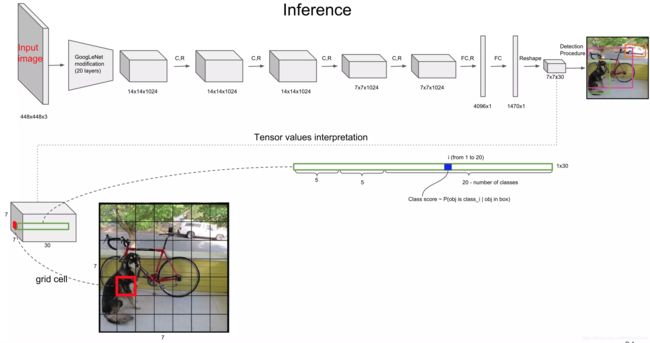
网络输入:图片为448*448大小
网络输出:网络是根据GoogLeNet改进的,输出回归得到的7x7x(2x5+20)张量(7是单元格;2x5是指每个单元格需要预测B个bbox值(bbox值包括坐标和宽高,原文中B=2),同时为每个bbox值预测一个置信度(confidence scores),也就是每个单元格需要预测B×(x,y,w,h,confidence)个值;20是物体种类个数,相应的损失函数的权重有所不同,关于坐标的权重更大,)(confidence置信度是由两部分组成,一是格子内是否有目标,二是bbox的准确度)
最终输出:得到每个 box 的 class-specific confidence score 以后,设置阈值,滤掉得分低的 boxes,对保留的 boxes 进行 NMS 非极大值抑制处理,就得到最终的检测结果。
不足:
1.小物体你就不行,后续的改进也是针对这个问题:对于目标比较小的物体,虽然采用均方误差,其同等对待大小不同的边界框,但是实际上较小的边界框的坐标误差应该要比较大的边界框要更敏感。为了保证这一点,将网络的边界框的宽与高预测改为对其平方根的预测,但是效果还是不太行。
2.一个格多个物体你就不行:另外一点时,由于每个单元格预测多个边界框。但是其对应类别只有一个。那么在训练时,如果该单元格内确实存在目标,那么只选择与ground truth的IOU最大的那个边界框来负责预测该目标,而其它边界框认为不存在目标。这样设置的一个结果将会使一个单元格对应的边界框更加专业化,其可以分别适用不同大小,不同高宽比的目标,从而提升模型性能。大家可能会想如果一个单元格内存在多个目标怎么办,其实这时候Yolo算法就只能选择其中一个来训练,这也是Yolo算法的缺点之一。
3.在测试阶段:对于输出的7x7x2=98个boxes,首先将小于置信度阈值的值归0,然后分类别地对置信度值采用NMS,这里NMS处理结果不是剔除,而是将其置信度值归为0。最后才是确定各个box的类别,当其置信度值不为0时才做出检测结果输出。这个策略不是很直接,但是貌似Yolo源码就是这样做的。
YOLO_v2
推荐阅读传送门1
推荐阅读传送门2
相对于V1的不同点 (DarkNet-19):
1.每个卷积层后面都添加了Batch Normalization层,并且不再使用droput;
2.使用高分辨率的数据;
3.使用 anchor box 进行卷积,什么是anchor box,看下图(就是边界box里面,我每一个都加分类的张量进去,没想到吧);

4.用聚类先确定先验框,选用 boxes 之间的 IOU 值作为聚类指标;
5.根据所在网格单元的位置来预测坐标,并且对每个格子设置了0~1,最后在网络调整框框偏移量的时候,就不会像fast-rcnn一样会乱jb估,模型也会快点收敛;
6.像SPP一样,最后多尺度的输入(有点残差网络的感觉了)
存在的问题:YOLO v2 对 YOLO v1 的缺陷进行优化,大幅度高了检测的性能,但仍存在一定的问题,如无法解决重叠问题的分类等。
YOLO_v3
一文看懂YOLO v3
相对于的不同点 (DarkNet-53):
1.Feature Pyramid Networks for Object Detection加了图像金字塔,对小的物体有更好的特征提取
2.用逻辑回归替代 softmax 作为分类器:在实际应用场合中,一个物体有可能输入多个类别,单纯的单标签分类在实际场景中存在一定的限制。举例来说,一辆车它既可以属于 car(小汽车)类别,也可以属于 vehicle(交通工具),用单标签分类只能得到一个类别。因此在 YOLO v3 在网络结构中把原先的 softmax 层换成了逻辑回归层,从而实现把单标签分类改成多标签分类。用多个 logistic 分类器代替 softmax 并不会降低准确率,可以维持 YOLO 的检测精度不下降。
SSD: Single Shot MultiBox Detector
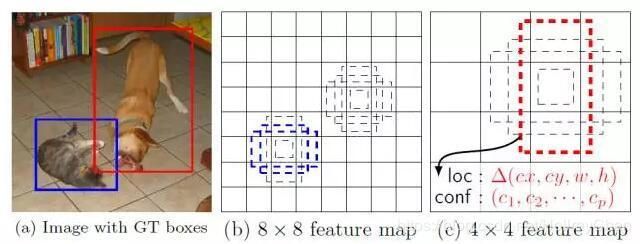
首先SSD获取目标位置和类别的方法跟YOLO一样,都是使用回归,但是YOLO预测某个位置使用的是全图的特征,SSD预测某个位置使用的是这个位置周围的特征。假如某一层特征图(图b)大小是88,那么就使用33的滑窗提取每个位置的特征,然后这个特征回归得到目标的坐标信息和类别信息(图c)。
不同于Faster R-CNN,这个anchor是在多个feature map上,这样可以利用多层的特征并且自然的达到多尺度(不同层的feature map 3*3滑窗感受野不同)。图b不同大小的框框就是default box。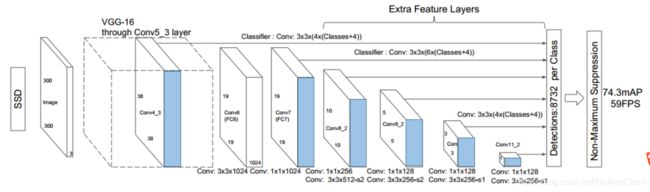
创新点:1.在多层多尺度特征图上进行检测,浅层网络不同尺度的结果会输出到detections中;2.SSD借鉴RPN网络中的anchor box概念。首先将feature map划分为小格子叫做feature map cell,再在每个cell中设置一系列不同长宽比的default box。;3.在向default box回归的时候,采用了3x3的卷积。
在YOLO中,首次提出了将特征图划分为格子,以格子为单位进行分类回归预测,但其采用了全连接层,导致参数非常多。SSD借鉴了Faster R-CNN的RPN网络,将YOLO中的全连接层换成了3x3的卷积;4.标定GT的时候还要标定一下default box
回归loss:这部分有两个loss,一个是预测的box与default box之间的偏移量,也即网络输出的4个值;另一个是ground truth与default box的偏移量(在给定输入图片groudth与为整个网络设置好default box后,该值是可以直接计算出来的,其计算公式沿用了RPN网络的中的公式)。回归部分的loss是希望预测的box与default box之间的差距尽可能与ground truth和default box差距接近,这样预测的box就能尽量和ground truth一样。
Confidence Loss:(分类loss):Confidence loss是一个softmax分类loss,为每个default box进行分类。