第十天 - MapReduce实体数据类型 - 与Web交互
第十天 - MapReduce实体数据类型 - 与Web交互
- 第十天 - MapReduce实体数据类型 - 与Web交互
-
- 一、MapReduce使用实体作为数据类型案例
-
- 输入
- 输出
- 编写代码
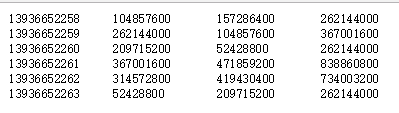
- 运行结果:
-
- 二、MapReduce与Web进行交互案例
-
- index.jsp
- RunMRServlet.java
- system.properties
- RemoteUtil.java
- PropertiesUtil.java
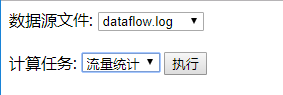
- 运行结果
-
- 一、MapReduce使用实体作为数据类型案例
-
一、MapReduce使用实体作为数据类型案例
输入
输入数据共30w+行,以下为其中部分
13936652258,200,300
13936652259,500,200
13936652260,400,100
13936652261,700,900
13936652262,600,800
13936652263,100,400
13936652258,200,300
13936652259,500,200
13936652260,400,100
13936652261,700,900
13936652262,600,800
13936652263,100,400输出
中间以”\t”间隔
13936652258 400 600 1000
13936652259 1000 400 1400
13936652260 800 200 1000
13936652261 1400 1800 3200
13936652262 1200 1600 2800
13936652263 200 800 1000编写代码
实体类:Flow.java
编写实体类时需要注意两点:
- 需要实现Writable接口进行对实体类的序列化,并重写readFields和write方法
- 实体类需要提供空参的构造方法
package com.qf.mr.bean; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.Writable; public class Flow implements Writable{ private int up; private int down; private int total; public Flow() { } public Flow(int up, int down) { this.up = up; this.down = down; this.total = up + down; } public int getUp() { return up; } public void setUp(int up) { this.up = up; } public int getDown() { return down; } public void setDown(int down) { this.down = down; } public int getTotal() { return total; } public void setTotal(int total) { this.total = total; } @Override public String toString() { return up + "\t" + down + "\t" + total; } @Override public void readFields(DataInput in) throws IOException { this.up = in.readInt(); this.down = in.readInt(); this.total = in.readInt(); } @Override public void write(DataOutput out) throws IOException { out.writeInt(up); out.writeInt(down); out.writeInt(total); } }FluxCountMapper.java
package com.qf.mr.mapper; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import com.qf.mr.bean.Flow; public class FluxCountMapper extends MapperFluxCountReducer.java
package com.qf.mr.reducer; import java.io.IOException; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import com.qf.mr.bean.Flow; public class FluxCountReducer extends Reducervalues, Reducer FluxCountMaster.java
package com.qf.mr.master; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import com.qf.mr.bean.Flow; import com.qf.mr.mapper.FluxCountMapper; import com.qf.mr.reducer.FluxCountReducer; public class FluxCountMaster { public static void main(String[] args) throws Exception{ // 初始化配置 Configuration conf = new Configuration(); // 初始化job参数,指定job名称 Job job = Job.getInstance(conf, "dataflow"); // 设置运行job的类 job.setJarByClass(FluxCountMaster.class); // 设置Mapper类 job.setMapperClass(FluxCountMapper.class); // 设置Reducer类 job.setReducerClass(FluxCountReducer.class); // 设置Map的输出数据类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Flow.class); // 设置Reducer的输出数据类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(Flow.class); // 设置输入的路径 FileInputFormat.setInputPaths(job, new Path("hdfs://SZ01:8020/input/dataflow")); // 设置输出的路径 FileOutputFormat.setOutputPath(job, new Path("hdfs://SZ01:8020/output/dataflow3")); // 提交job boolean result = job.waitForCompletion(true); // 执行成功后进行后续操作 if (result) { System.out.println("Congratulations!"); } } }
运行结果:

二、MapReduce与Web进行交互案例
需求:从网页获得要执行任务的方法类、数据文件位置,在Servlet中执行相应的方法,将结果在网页显示。
index.jsp
<body>
<form action="RunMRServlet">
<span>数据源文件:span>
<select name="inputPath">
<option value="dataflow/">dataflow.logoption>
<option value="wordCount/">wordsData.txtoption>
<option value="avg/">avgoption>
select>
<br />
<br />
<span>计算任务:span>
<select name="job">
<option value="wordCount">单词计数option>
<option value="flowCount">流量统计option>
<option value="avg">求平均数option>
select>
<input type="submit" class="button" value="执行" />
form>
<br /><br />
<div class="result">div>
body>RunMRServlet.java
实现思路:
- 通过index页面获得单词数据文件目录、计算任务名
- 通过任务名进入不同的判断结构,获得运行此MapReduce任务的主类名
- 输出路径通过获取时间戳来拼接,避免重复
注意:调用RemoteUtil远程访问Linux执行命令时,需要写命令的全路径才能执行,否则报命令不存在的错误。
import java.io.IOException;
import java.io.PrintWriter;
import java.util.Date;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import com.sand.util.PropertiesUtil;
import com.sand.util.RemoteUtil;
/**
* Servlet implementation class RunMRServlet
*/
@WebServlet("/RunMRServlet")
public class RunMRServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
/**
* @see HttpServlet#HttpServlet()
*/
public RunMRServlet() {
super();
// TODO Auto-generated constructor stub
}
/**
* @see HttpServlet#doGet(HttpServletRequest request, HttpServletResponse response)
*/
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// 接收参数 - 源文件路径
String inputPath = request.getParameter("inputPath");
// 接收参数 - 算法名称
String jobName = request.getParameter("job");
PrintWriter out = response.getWriter();
// 初始化配置文件读取工具类
PropertiesUtil propertiesUtil = new PropertiesUtil("system.properties");
String host = propertiesUtil.readPropertyByKey("hostName");
String userName = propertiesUtil.readPropertyByKey("hadoopUser");
String userPwd = propertiesUtil.readPropertyByKey("hadoopPwd");
// 初始化远程登录Linux执行命令工具类
RemoteUtil remoteUtil = new RemoteUtil(host, userName, userPwd);
// 获取当前用户信息
// String userId = ((User)request.getSession().getAttribute("user")).getId();
// 拼接完整的源文件路径
inputPath = propertiesUtil.readPropertyByKey("userDataDir") + "/" + inputPath;
String mainClass = "";
String outputPath = propertiesUtil.readPropertyByKey("resultPath");
//String outputPath = resultPath;
// 获得完整的MainClass名称
if ("wordCount".equals(jobName)) {
mainClass = propertiesUtil.readPropertyByKey("wordCount");
outputPath += "wordCount";
}else if("flowCount".equals(jobName)){
mainClass = propertiesUtil.readPropertyByKey("flowCount");
outputPath += "dataflow";
}else if("avg".equals(jobName)) {
mainClass = propertiesUtil.readPropertyByKey("avg");
outputPath += "avg";
}
// 获得完整的运行jar包路径
String jarPath = propertiesUtil.readPropertyByKey("jarPath");
// 如果不清楚历史结果文件则保证当前结果文件名称的唯一性
outputPath += new Date().getTime();
// 获得hadoopBin目录,才能执行hadoop命令
String hadoopBin = propertiesUtil.readPropertyByKey("hadoopBinHome");
// 拼接为完整的命令执行语句
String cmd = hadoopBin + "hadoop jar " + jarPath + " " + mainClass + " " + inputPath + " " + outputPath;
System.out.println(cmd);
String result = remoteUtil.execute(cmd);
System.out.println(result);
// 需要使用contains
if(result.contains("Congratulations!")) {
System.out.println("MapReduce成功");
// 查看运行结果文件
cmd = hadoopBin + "hdfs dfs -cat " + outputPath + "/part-r-00000";
result = remoteUtil.execute(cmd);
//request.setAttribute("result", result);
// 直接write打印结果
out.write(result);
//request.getRequestDispatcher("show.jsp").forward(request, response);
}
}
/**
* @see HttpServlet#doPost(HttpServletRequest request, HttpServletResponse response)
*/
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// TODO Auto-generated method stub
doGet(request, response);
}
}system.properties
# 主机名
hostName=SZ01
# hdfs端口号
hdfsPort=8020
# 操作Hadoop软件用户名
hadoopUser=bigdata
# 操作Hadoop软件用户密码
hadoopPwd=bigdata
# Hadoop命令文件所在路径
hadoopBinHome=/home/bigdata/hadoop-2.7.2/bin/
# 用户文件根目录
userDataDir=/input
# 算法包所在路径
jarPath=/home/bigdata/hadoopTest/mapreduce.jar
# 单词计数主类
wordCount=com.qf.mr.master.WordCountMaster
# 流量统计主类
flowCount=com.qf.mr.master.FluxCountMaster
# 计算平均数主类
avg=com.qf.mr.master.AvgMaster
# 结果文件根目录
resultPath=/output/RemoteUtil.java
点击查看:RemoteUtil.java
PropertiesUtil.java
点击查看:PropertiesUtil.java
运行结果