MapReduce类型与格式
输入格式
1)输入分片与记录
a)JobClient通过指定的输入文件的格式来生成数据分片InputSpilit
输入格式概览如图所示:
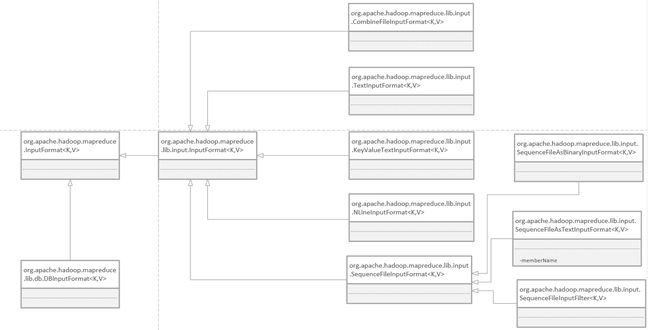
抽象类:FileInputFormat
1、FileInputFormat是所有使用文件作为数据源的InputFormat实现的基类
2、FileInputFormat输入数据格式的分片大小由数据块大小决定
在org.apache.hadoop.mapreduce.lib.input.FileInputFormat.java中的getSplits方法
/**
* Generate the list of files and make them into FileSplits.
*/
public List getSplits(JobContext job
) throws IOException {
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job);
// generate splits
List splits = new ArrayList();
Listfiles = listStatus(job);
for (FileStatus file: files) {
Path path = file.getPath();
FileSystem fs = path.getFileSystem(job.getConfiguration());
long length = file.getLen();
BlockLocation[] blkLocations = fs.getFileBlockLocations(file, 0, length);
if ((length != 0) && isSplitable(job, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(new FileSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts()));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
splits.add(new FileSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkLocations.length-1].getHosts()));
}
} else if (length != 0) {
splits.add(new FileSplit(path, 0, length, blkLocations[0].getHosts()));
} else {
//Create empty hosts array for zero length files
splits.add(new FileSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files in the job-conf
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
LOG.debug("Total # of splits: " + splits.size());
return splits;
} 调用org.apache.hadoop.mapreduce.lib.input.FileInputFormat.java中的computeSplitSize方法
protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}b)一个分片不是数据本身,而是可分片数据的引用
c)InputFormat接口负责生成分片
2)文件输入
抽象类:CombineFileInputFormat
1、可以使用CombineFileInputFormat来合并小文件
2、因为CombineFileInputFormat是一个抽象类,使用的时候需要创建一个CombineFileInputFormat的实体类,并且实现getRecordReader()的方法
3、避免文件分割的方法:
A、数据块大小尽可能大,这样使文件的大小小于数据块的大小,就不用进行分片
B、继承FileInputFormat,并且重载isSplitable()方法
3)文本输入
类名:TextInputFormat
1、TextInputFormat是默认的InputFormat,每一行数据就是一条记录
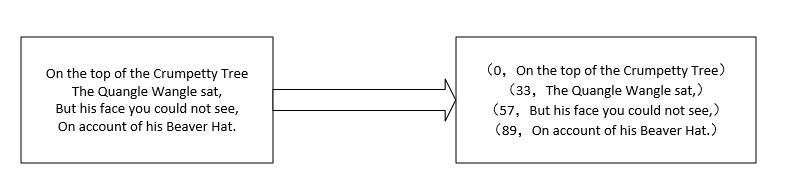
2、TextInputFormat的key是LongWritable类型的,存储该行在整个文件的偏移量,value是每行的数据内容,Text类型
3、输入分片与HDFS数据块关系:TextInputFormat每一条记录就是一行,很有可能某一行跨数据块存放
类名:KeyValueTextInputFormat
1、KeyValueTextInputFormat类可以通过设置key为行号的方式来知道记录的行号,并且可以通过key.value.separator.in.input设置key与value的分割符
类名:NLineInputFormat
1、可以设置每个mapper处理的行数,可以通过mapred.line.input.format.linespermap属性设置
4)二进制输入
类:SequenceFileInputFormat
SequenceFileAsTextInputFormat
SequenceFileAsBinaryInputFormat
1、由于SequenceFile能够支持Splittable,所以能够作为mapreduce输入的格式,能够很方便的得到已经含有
/**
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount " );
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
现在修改代码使其对SequenceFile进行词频统计
package com.mr;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class TestInputFormat {
public static class TokenizerMapper
extends Mapper{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(IntWritable key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount " );
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(TestInputFormat.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(SequenceFileInputFormat.class) ;
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
读取的SequenceFile文件通过如下代码生成
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.SequenceFile.CompressionType;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
public class SequenceFileWrite {
public static String uri = "hdfs://10.13.33.218:9000" ;
public static String[] data = {
"one,two" ,
"three,four" ,
"five,six" ,
"seven,eight" ,
"nine,ten"
} ;
public static void main(String args[])throws Exception{
Configuration conf = new Configuration() ;
FileSystem fs = FileSystem.get(URI.create(uri),conf) ;
// Path path = new Path("/tmp.seq") ;
Path path = new Path("/b.seq") ;
IntWritable key = new IntWritable() ;
Text value = new Text() ;
//SequenceFile.Writer writer = SequenceFile.createWriter(fs, conf,path, key.getClass(), value.getClass()) ;
SequenceFile.Writer writer = SequenceFile.createWriter(fs, conf,path, key.getClass(), value.getClass(),CompressionType.RECORD,new BZip2Codec()) ;//对SequenceFile进行记录压缩
for(int i=0;i<100;i++){
key.set(100-i) ;
value.set(data[i%data.length]) ;
writer.append(key, value) ;
}
IOUtils.closeStream(writer) ;
}
}
现在修改代码使其对SequenceFile和文本文件同时进行词频统计,代码如下:
package com.mr;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TestInputFormat {
public static class Mapper1 extends
Mapper {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class Mapper2 extends
Mapper {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(IntWritable key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends
Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
// if (otherArgs.length != 2) {
// System.err.println("Usage: wordcount " );
// System.exit(2);
// }
Job job = new Job(conf, "word count");
job.setJarByClass(TestInputFormat.class);
// job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// job.setInputFormatClass(SequenceFileInputFormat.class) ;
Path path1 = new Path("hdfs://10.13.33.218:9000/a.txt") ;
Path path2 = new Path("hdfs://10.13.33.218:9000/b.seq") ;
MultipleInputs.addInputPath(job, path1, TextInputFormat.class,Mapper1.class) ;
MultipleInputs.addInputPath(job, path2, SequenceFileInputFormat.class,Mapper2.class) ;
// FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path("hdfs://10.13.33.218:9000/output3"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
输出格式概览,如图所示:
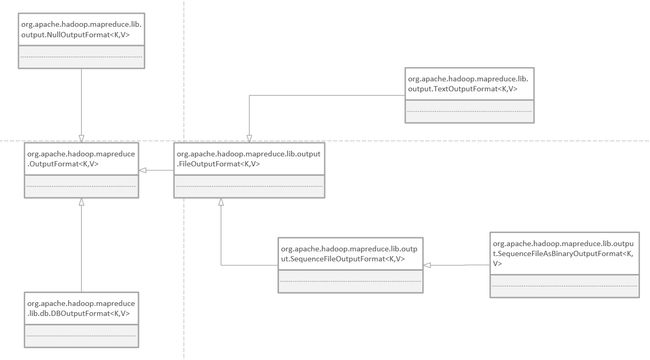
1、文本输出
类名:TextOutputFormat
1)默认的输出方式,key是LongWritable类型的,value是Text类型的
2)以“key \t value”的方式输出行
2、二进制输出
类名:SequenceFileOutputFormat
子类:SequenceFileAsBinaryOutputFormat
3、多文件输出
类名:MultipleOutputs可以产生不同类型的输出
4、数据库输出
类名:DBOutputFormat