Sparkstreaming读取kafka数据写入hive和es
一、主要流程
此demo用到的软件如下,软件需先自行安装
springboot 1.5.9.RELEASE、hadoop 2.7.2、spark 2.1.1、elasticsearch 5.2.2、kafka 0.10.2.1、hive、sqoop、。
demo的主要流程如下图:
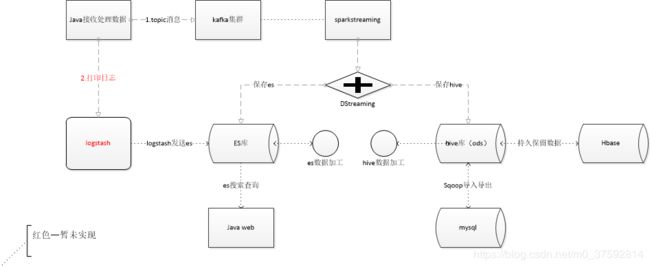
二、流程步骤
1.数据采集
数据采集主要是通过java程序模拟造数据和使用fiddler抓包转发response数据,然后通过发送消息到kafka。
实现如下:
/**
* @Description: 菜品列表
* @author tang
* @date 2020/3/7 22:26
*/
public void getH5FoodList(String response_data){
BaseResultVO baseResultVO = JSON.parseObject(response_data, BaseResultVO.class);
if(0!=baseResultVO.getCode()){
return;
}
ShopDTO shopDTO = JSON.parseObject(JSON.toJSONString(baseResultVO.getData()), ShopDTO.class);
if(null==shopDTO){
return;
}
//组装数据
Shop shop = buildShopMessageToKafka(shopDTO);
//发送给kafka
logger.info("send message to kafka topic {} start current time is {}" ,KafkaTopicEnum.SHOP.getTopic(),System.currentTimeMillis());
KafkaProducerUtils kafkaProducerUtils = new KafkaProducerUtils();
kafkaProducerUtils.produceMassage(KafkaTopicEnum.SHOP.getTopic(),JSON.toJSONString(shop));
logger.info("send message to kafka topic {} success current time is {}" ,KafkaTopicEnum.SHOP.getTopic(),System.currentTimeMillis());
}kafka发送消息工具类
public class KafkaProducerUtils {
private Producer producer;
/**
* @Description: 生产消息
* @author tang
* @date 2018/12/24 22:42
*/
public void produceMassage(String topic,String massage){
/**
* 1、指定当前kafka producer生产的数据的目的地
* 创建topic可以输入以下命令,在kafka集群的任一节点进行创建。
* bin/kafka-topics.sh --create --zookeeper zk01:2181 --replication-factor 1 --partitions 1 --topic test
*/
/**
* 2、读取配置文件
*/
Properties props = new Properties();
/*
* key.serializer.class默认为serializer.class
*/
props.put("serializer.class", "kafka.serializer.StringEncoder");
/*
* kafka broker对应的主机,格式为host1:port1,host2:port2
*/
props.put("metadata.broker.list", "192.168.25.128:9092,192.168.25.129:9092,192.168.25.130:9092");
/*
* request.required.acks,设置发送数据是否需要服务端的反馈,有三个值0,1,-1
* 0,意味着producer永远不会等待一个来自broker的ack,这就是0.7版本的行为。
* 这个选项提供了最低的延迟,但是持久化的保证是最弱的,当server挂掉的时候会丢失一些数据。
* 1,意味着在leader replica已经接收到数据后,producer会得到一个ack。
* 这个选项提供了更好的持久性,因为在server确认请求成功处理后,client才会返回。
* 如果刚写到leader上,还没来得及复制leader就挂了,那么消息才可能会丢失。
* -1,意味着在所有的ISR都接收到数据后,producer才得到一个ack。
* 这个选项提供了最好的持久性,只要还有一个replica存活,那么数据就不会丢失
*/
props.put("request.required.acks", "1");
/*
* 可选配置,如果不配置,则使用默认的partitioner partitioner.class
* 默认值:kafka.producer.DefaultPartitioner
* 用来把消息分到各个partition中,默认行为是对key进行hash。
*/
/*props.put("partitioner.class", "cn.itcast.bigdata.kafka.MyLogPartitioner");*/
props.put("partitioner.class", "kafka.producer.DefaultPartitioner");
/**
* 3、通过配置文件,创建生产者
*/
producer = new Producer(new ProducerConfig(props));
producer.send(new KeyedMessage(topic,massage));
}
} 到kafka上验证是否已经有数据:
sh bin/kafka-console-consumer.sh --zookeeper ELK01:2181 --from-beginning --topic test1

2.SparkStreaming从kafka中消费消息
sparkstreaming 从kafka中消费消息有两中方式 1. KafkaUtils.createStream 和 2.KafkaUtils.createDirectStream 两种方式,第二种方式效率更高,这里使用的是第二种方式
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("kafka_Direct_streaming").setMaster("local[4]")
sparkConf.set("es.index.auto.create", "true")
sparkConf.set("es.nodes", "localhost")
sparkConf.set("es.port", "9200")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val session = SparkSession.builder()
.enableHiveSupport()
.config(sparkConf)
.getOrCreate()
ssc.checkpoint("F:\\checkpoint\\kafka-direct")
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "ELK01:9092,ELK02:9092,ELK03:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "shopGroup",
"auto.offset.reset" -> "latest",
"max.poll.records" -> 10.toString,
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("shop1")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
val shopDS = stream.map(_.value())
shopDS.foreachRDD(rdd=>{
//保存到hive中
val sparkSession = SparkSessionSingleton.getInstance(rdd.sparkContext.getConf)
saveToHive(rdd,sparkSession)
//保存到es中
saveToEs(rdd)
})
ssc.start()
ssc.awaitTermination()
}3.SparkStreaming保存数据到hive和es中
(1)hive中创建数据库及表。

(2)sparksql通过insert 语句把rdda数据写入到hive表中
DStream 使用 foreachRDD(rdd=>{})得到每个rdd,每个rdd通过sparksql方式把数据保存到hive表中取,hive表是分区表,使用的是动态分区,按日期作为分区,写入数据时需要开启动态分区,不然写入数据报错。
/**
* 保存店铺信息
* @param rdd
* @param sparkSession
*/
def saveShopToHive(rdd:RDD[String],sparkSession: SparkSession):Unit={
import sparkSession.implicits._
val curentDate = getNowDate()
//店铺信息
val shopDataFrame = rdd.map(x=>{
val jsonObject = JSON.parseObject(x)
jsonObject
}).filter(x=>{
x.containsKey("mtWmPoiId")
}).map(x=>{
var shopBean: Shop =null
try {
shopBean =dealShop(x)
} catch {
case e: JSONException => {
}
}
shopBean
}).toDF()
val tableName = "shop"
shopDataFrame.createOrReplaceTempView(tableName)
//存入表中
sparkSession.sql("use wm")
sparkSession.sql("set hive.exec.dynamici.partition=true")
sparkSession.sql("set hive.exec.dynamic.partition.mode=nonstrict")
sparkSession.sql("insert into table ods_shop partition(batch_date) " +
"select wm_poi_id,dp_shop_id,shop_name,shop_status,shop_pic,delivery_fee," +
s"delivery_type,delivery_time,min_fee,online_pay,bulletin,shipping_time,create_time,$curentDate from shop")
}
(3)spark通过把数据处理成json格式,直接写入到es中。写入es可以通过EsSpark.saveToEs(rdd, "spark/docs")和EsSparkStreaming.saveToEs(dstream, "spark/docs") 对于streaming来说第二中方式效率更优,不用遍历每个rdd了,直接就把dstream保存进去,前提时接收kafka的数据是可以不需要处理直接保存的。关于spark和elasticsearch 整合,读写elasticsearch数据可以参考官方文档:https://www.elastic.co/guide/en/elasticsearch/hadoop/current/spark.html
/**
* 保存店铺信息
* @param rdd
*/
def saveShopToEs(rdd:RDD[String]):Unit={
val curentDate = getNowDate()
if(!rdd.isEmpty()){
val shopRdd = rdd.map(x=>{
val jsonObject = JSON.parseObject(x)
jsonObject
}).filter(x=>{
x.containsKey("mtWmPoiId")
}).map(x=>{
val jsonObject = dealShopToEsJSON(x)
jsonObject
})
EsSpark.saveToEs(shopRdd,s"shop/$curentDate")
}
}(4)到es和hadoop上查看是否有数据:
检查hive数据在hadoop上存放数据

es数据

4.hive数据加工
这里主要是把sparkstreaming生成的小文件合并成大文件,以及对店铺去重。
set hive.exec.dynamici.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
insert into table dwd_shop partition(batch_date)
select wm_poi_id,dp_shop_id,collect_set(shop_name)[0] shop_name,collect_set(shop_status)[0] shop_status ,collect_set(shop_pic)[0] shop_pic,collect_set(delivery_fee)[0] delivery_fee,
collect_set(delivery_type)[0] delivery_type,collect_set(delivery_time)[0] delivery_time,collect_set(min_fee)[0] min_fee,collect_set(online_pay)[0] online_pay,collect_set(bulletin)[0] bulletin,collect_set(shipping_time)[0] shipping_time,collect_set(create_time)[0] create_time,'2020-05-03'
from ods_shop where batch_date='2020-05-03' group by wm_poi_id,dp_shop_id;5.hive导数据导hbase
查阅另一个博客:
https://blog.csdn.net/m0_37592814/article/details/105925860
6.sqoop 导入与导出
未完待续。。。。
部分代码可以到github上查看:https://github.com/tianyadaochupao/crawler