kafka+storm+hbase整合试验(Wordcount)
这里把kafka生产的数据作为storm的源头spout来消费,经过bolt处理把结果保存到hbase。
基础环境:
Redhat 5.5 64位(我这里是三台虚拟机h40,h41,h42)
myeclipse 8.5
jdk1.7.0_25
zookeeper-3.4.5集群
hadoop-2.6.0集群
apache-storm-0.9.5集群
kafka_2.10-0.8.2.0集群
hbase-1.0.0集群
两个Bolt:
package hui;
import java.util.StringTokenizer;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class SpliterBolt extends BaseBasicBolt{
@Override
public void execute(Tuple tuple, BasicOutputCollector collector){
String sentence = tuple.getString(0);
StringTokenizer iter = new StringTokenizer(sentence);
while(iter.hasMoreElements()){
collector.emit(new Values(iter.nextToken()));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer){
declarer.declare(new Fields("word"));
}
}
package hui;
import java.io.FileWriter;
import java.util.HashMap;
import java.util.Map;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class CountBolt extends BaseBasicBolt {
Map counts = new HashMap();
private FileWriter writer = null;
@Override
public void prepare(Map stormConf, TopologyContext context) {
}
@Override
public void execute(Tuple tuple, BasicOutputCollector collector){
String word = tuple.getString(0);
Integer count = counts.get(word);
if(count == null)
count = 0;
count++;
counts.put(word,count);
System.out.println("hello word!");
System.out.println(word +" "+count);
collector.emit(new Values(word, count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer){
declarer.declare(new Fields("word","count"));
}
} package hui;
import java.util.HashMap;
import java.util.Map;
import org.apache.storm.hbase.bolt.HBaseBolt;
import org.apache.storm.hbase.bolt.mapper.SimpleHBaseMapper;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import storm.kafka.BrokerHosts;
import storm.kafka.KafkaSpout;
import storm.kafka.SpoutConfig;
import storm.kafka.StringScheme;
import storm.kafka.ZkHosts;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.spout.SchemeAsMultiScheme;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
public class Topohogy {
static Logger logger = LoggerFactory.getLogger(Topohogy.class);
public static void main(String[] args) throws AlreadyAliveException, InvalidTopologyException, InterruptedException {
String topic = "hehe";
String zkRoot = "/kafka-storm";
String id = "old";
BrokerHosts brokerHosts = new ZkHosts("h40:2181,h41:2181,h42:2181");
SpoutConfig spoutConfig = new SpoutConfig(brokerHosts, topic, zkRoot, id);
spoutConfig.forceFromStart = true;
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
TopologyBuilder builder = new TopologyBuilder();
//设置一个spout用来从kaflka消息队列中读取数据并发送给下一级的bolt组件,此处用的spout组件并非自定义的,而是storm中已经开发好的KafkaSpout
builder.setSpout("KafkaSpout", new KafkaSpout(spoutConfig));
builder.setBolt("word-spilter", new SpliterBolt()).shuffleGrouping("KafkaSpout");
builder.setBolt("writer", new CountBolt(), 3).fieldsGrouping("word-spilter", new Fields("word"));
SimpleHBaseMapper mapper = new SimpleHBaseMapper();
//wordcount为表名
HBaseBolt hBaseBolt = new HBaseBolt("wordcount", mapper).withConfigKey("hbase.conf");
//result为列族名
mapper.withColumnFamily("result");
mapper.withColumnFields(new Fields("count"));
mapper.withRowKeyField("word");
Config conf = new Config();
conf.setNumWorkers(4);
conf.setNumAckers(0);
conf.setDebug(false);
Map hbConf = new HashMap();
hbConf.put("hbase.rootdir", "hdfs://h40:9000/hbase");
hbConf.put("hbase.zookeeper.quorum", "h40:2181");
conf.put("hbase.conf", hbConf);
// hbase-bolt
builder.setBolt("hbase", hBaseBolt, 3).shuffleGrouping("writer");
if (args != null && args.length > 0) {
//提交topology到storm集群中运行
StormSubmitter.submitTopology("sufei-topo", conf, builder.createTopology());
} else {
//LocalCluster用来将topology提交到本地模拟器运行,方便开发调试
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("WordCount", conf, builder.createTopology());
}
}
}
启动hadoop集群、zookeeper集群、kafka集群、storm集群、hbase集群,配置好环境变量,将所依赖的jar包导入到storm的lib目录下
在hbase中建立相应的表:
hbase(main):060:0> create 'wordcount','result'
在kafka中建立相应的topic:
[hadoop@h40 kafka_2.10-0.8.2.0]$ bin/kafka-topics.sh --create --zookeeper h40:2181 --replication-factor 3 --partitions 3 --topic hehe
Created topic "hehe".
提交Topohogy有两种模式:本地模式和集群模式
本地模式:
在myeclipse中直接运行主方法就可以(首先得确认Windows和虚拟机可以通信,如需要修改Windows的hosts文件)
在Topohogy.java中右击Run As-->Java Application,如图,程序处于阻塞状态:

在kafka生产者端输入数据:
[hadoop@h40 kafka_2.10-0.8.2.0]$ bin/kafka-console-producer.sh --broker-list h40:9092,h41:9092,h42:9092 --topic hehe
hello world
hello storm
hello kafka
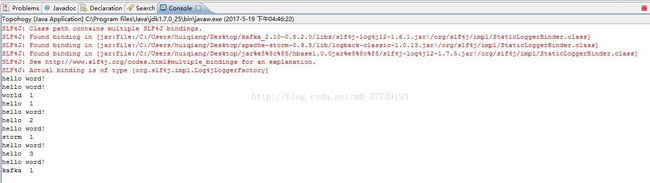
则eclipse中的控制台会打印出数据:
查看hbase中的表:
hbase(main):061:0> scan 'wordcount'
ROW COLUMN+CELL
hello column=result:count, timestamp=1495132057639, value=\x00\x00\x00\x03
kafka column=result:count, timestamp=1495132057642, value=\x00\x00\x00\x01
storm column=result:count, timestamp=1495132050608, value=\x00\x00\x00\x01
world column=result:count, timestamp=1495132050065, value=\x00\x00\x00\x01
4 row(s) in 0.0450 seconds用myeclipse将项目打成jar包上传到虚拟机的Linux下,路径你随意,我这里上传到了/home/hadoop/apache-storm-0.9.5目录下,提交Topohogy:
[hadoop@h40 apache-storm-0.9.5]$ bin/storm jar wordcount.jar hui.Topohogy h40
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/apache-storm-0.9.5/lib/slf4j-log4j12-1.6.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/apache-storm-0.9.5/lib/logback-classic-1.0.13.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/apache-storm-0.9.5/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
(程序到这里就会终止,并没有阻塞,也没有将分析结果打印出来。。。)注意:上面的输出是有问题的,原因是在storm的lib目录下同时存在slf4j-log4j12-1.6.1.jar和log4j-over-slf4j-1.6.6.jar,将slf4j-log4j12-1.6.1.jar删除,提交Topohogy后的正常输出应该是
337 [main] INFO backtype.storm.StormSubmitter - Jar not uploaded to master yet. Submitting jar...
348 [main] INFO backtype.storm.StormSubmitter - Uploading topology jar wordcount.jar to assigned location: storm-local/nimbus/inbox/stormjar-a0260e30-7c9a-465e-b796-38fe25a58a13.jar
364 [main] INFO backtype.storm.StormSubmitter - Successfully uploaded topology jar to assigned location: storm-local/nimbus/inbox/stormjar-a0260e30-7c9a-465e-b796-38fe25a58a13.jar
364 [main] INFO backtype.storm.StormSubmitter - Submitting topology sufei-topo in distributed mode with conf {"topology.workers":4,"topology.acker.executors":0,"topology.debug":false}
593 [main] INFO backtype.storm.StormSubmitter - Finished submitting topology: sufei-topo
(到这程序就结束了,并没有阻塞。。。。。。)查看Topohogy是否提交成功:
[hadoop@h40 apache-storm-0.9.5]$ bin/storm list
Topology_name Status Num_tasks Num_workers Uptime_secs
-------------------------------------------------------------------
sufei-topo ACTIVE 8 4 37 hello linux
hello world
hello world
参看hbase中的相应表:
hbase(main):062:0> scan 'wordcount'
ROW COLUMN+CELL
hello column=result:count, timestamp=1495132782238, value=\x00\x00\x00\x06
kafka column=result:count, timestamp=1495132057642, value=\x00\x00\x00\x01
linux column=result:count, timestamp=1495132768197, value=\x00\x00\x00\x01
storm column=result:count, timestamp=1495132050608, value=\x00\x00\x00\x01
world column=result:count, timestamp=1495132782238, value=\x00\x00\x00\x03
5 row(s) in 0.0830 secondsstorm和kafka安装整合的详细步骤可以浏览我的另一篇文章:flume+kafka+storm+hdfs整合
注意:
1.无法编译与hbase相关jar包的代码,错误: 找不到或无法加载主类 CreateMyTable
原因:没有将hbase中的lib目录下的jar包写到环境变量中
一开始我将:/home/hadoop/hbase-1.0.0/lib/*.jar添加到~/.bash_profile中的CLASSPATH中,却还是不好使,还必须的这样:/home/hadoop/hbase-1.0.0/lib/*才有效
2.当在eclipse中提交本地模式的时候可能会报这个错(在主方法中直接右键点击Run As-->Java Application就是提交的本地模式):
java.net.UnknownHostException: h40
解决:修改C:\Windows\System32\drivers\etc\hosts文件,添加如下内容,可能无法保存,请参考:https://jingyan.baidu.com/article/624e7459b194f134e8ba5a8e.html(Windows10),https://jingyan.baidu.com/article/e5c39bf56564a539d7603312.html(Windows7)
在末尾添加(你的storm集群的IP和主机名):
192.168.8.40 h40
192.168.8.41 h41
192.168.8.42 h42