Make a Face: Towards Arbitrary High Fidelity Face Manipulation(做个脸:走向任意高保真脸部操纵)
本博客是对 论文 Make a Face: Towards Arbitrary High Fidelity Face Manipulation(做个脸:走向任意高保真脸部操纵)的翻译,因作者水平有限,翻译难免会有不妥当的地方,还请读者不吝赐教。
摘要
最近的研究表明,随着GAN和VAE范例的发展,在面部操作任务中取得了显著成功,但输出有时仅限于低分辨率并且缺乏多样性。在这项工作中,我们提出了附加焦点变分自编码器(AF-VAE),这是一种新颖的方法,可以使用简单而有效的模型任意操纵高分辨率的人脸图像,并且仅对重建和KL散度进行弱监督损失。首先,引入了一种新的附加高斯混合假设,该假设在结构潜在空间中具有无监督的聚类机制,从而赋予了更好的解纠缠度并增强了具有外部记忆的多模态表示。其次,为了提高合成结果的感知质量,首次针对人类视觉系统(HVS)的行为进一步量身定制了两种简单的架构设计策略,并进行了讨论,从而可以对模型的复杂性和样本质量进行精细控制。人类意见的研究和最新的先验得分(IS)/ Fr’echetInception Distance(FID)证明了我们的方法优于现有算法,从而提高了面部操作任务的保真度和极限度。

图1:通过转移从CelebA数据集中获得的知识,可以在野外样本上进行面部操作。第一列显示输入图像,其余为AF-VAE以目标表情/旋转边界图为条件生成的图像。请注意,该模型已使用来自YouTube的256×256分辨率的影片剪辑帧进行了微调。先前看不到所有生成的姿势。
1 引言
自动操纵单张图像的面部表情和头部姿势是一项具有挑战性的开放式条件生成任务。真实逼真的面部处理技术在工业上有广泛的应用,例如胶片制作,面部分析和摄影技术。随着生成模型的蓬勃发展,近年来,产生了各种逼真的结果,面部处理技术也有了很大的发展。不过,由于缺乏成对训练数据,对于生成模型而言,学习内在的人像特征的紧凑表示,用于合成具有高保真或大的面部表情/姿势的人脸图像,依旧具有挑战性。
当前最先进的面部操作方法[32、22、9、37]主要受益于生成对抗网络(GAN)的发展。为了解决上述两个瓶颈(高保真的图像和大的姿势和表情变化),大量算法着重于对损失项或生成器结构的复杂修改,并注入了不同的面部属性信息[54、37、22、48、50、34、49、27]。其它一些工作[54, 16, 48, 55, 7, 2, 28, 29]注重于特定任务的训练程序。然而,由于训练方法不稳定以及受到环境限制,在极端面孔形状变形和复杂的不受控制的数据集上成功生成合理的样本仍然是这些方法需要解决的问题。RaFD [26]人脸表情合成中的最新技术[32]实现了Fr’echet起始距离(FID)[15]为34的结果,这说明即使在受控环境中,生成结果与真实数据仍有很大差距。
在这项工作中,我们着手通过一个简单而有效的框架来缩小由当前最先进技术生成的图像和现实世界中的面部图像所产生的面部表情/旋转之间的逼真度和极限。我们探索了用于面部操作任务的条件变分自动编码器(C-VAE)的形式[21,41]。显而易见的是使用C-VAE的良好流型表示和文稳定的训练机制。尽管如此,针对变分条件自编码器量身定做的面部操纵任务并非易事:(1)由于通常假定潜分布是单位高斯分布,因此将牺牲合成输出的多样性。然而,如图2(b)所示,需要描述年龄,肤色,亮度和姿势等因素的复杂潜在表示形式会破坏高斯分布的假设。(2)面部表情比其他来源(如风景,手指和动物)更精细。因此,VAE的属本质和通用架构无法满足在高分辨率图像上保持面部细节的要求。
作为解决此类问题的方法,我们提出了一种新颖的附加焦点变分自动编码器(AF-VAE)框架。通过应用轻量级的几何导向显式地分解潜在空间中的面部外观和结构,我们鼓励将潜在代码分成姿势不变的外观表示和结构表示,从而在几何变形下保持外观和结构信息。为了解决多样性问题,我们在框架中引入了一种新颖的附加存储模块,该模块在结构潜空间中将无监督的聚类机制与高斯混合先验相结合,赋予了多模态面部 表情/旋转 生成的能力。
为了进一步提高合成结果的感知质量,我们还在模型设计中发现了两种简单而有效的策略,并根据人类视觉系统(HVS)的行为,凭经验对它们进行表征。利用来自此经验分析的见解,我们证明了简单注入这些策略可以轻松提高合成结果的感知质量。我们的模型可以在不受控制的设置下以256 ×256的分辨率稳定地操纵逼真的面部表情和面部旋转。提出的AM-VAE将在不受控制的CelebA数据集上取得的最好 FID 和 IS 分数[26] 从71.3和1.065提高到36.82和2.15。我们与当前最先进的操作算法进行了比较[9,32,37,46],并表明我们的方法在定量和定性评估方面均优于这些方法。广泛的自我评估实验进一步证明了所提出组件的有效性。
2 相关工作
人脸操纵:在人脸图像操纵的文献中,除了经典的质量弹簧模型和2D / 3D变形方法[42、43、44]外,最近,利用生成对抗网络(GANs)[32、22、9、37、53、51]也取得了重大进展。,获得了逼真的合成结果。为了提高GAN的鲁棒性和多样性,人们进行了各种方面的调整。例如,StarGAN [9]利用循环一致性来保留源图像和目标图像之间的关键属性。 GANimation [32]进一步走了一步,通过使用更密集的AUs先验向量通过改变每个AUs的大小来增加多样性。生成器体系结构中的注意力机制还用于屏蔽不相关的面部区域,从而迫使网络仅合成区域内纹理。FaceID-GAN [37]引入了一种三部分对抗方案,并利用3DMM [3]更好地保留了面部属性。CAPG-GAN [16]训练一个耦合剂判别器来约束姿势和面部结构的分布。由于GAN在脆弱的训练过程以及在采样多样性方面面临挑战,因此一些作品利用了变分自动编码器(VAE)范式及其变体的优势,探索了潜在空间中固有的面部特征。例如,神经人脸编辑[40]和变形自动编码器[39]利用图形渲染元素(例如UV贴图,反照率和阴影)来消除潜在表示的耦合。但是,这些基于VAE的方法的主要缺点是合成的结果模糊,这是由注入的元素方差测量和不完善的网络体系结构导致的。CVAE-GAN [1]将VAE和GAN结合到一个框架中,该框架具有不对称的训练损失和细粒度的类别标签。这些方法缺少用户可任意操纵面部表情的接口,因为他们通过流行遍历编辑结果。值得注意的是,在其他任务(如图像字幕)中还讨论了VAE的容量约束,在[45,33]中,提出了加性高斯编码空间以提供更多样化和准确的字幕结果。受这些先前工作的启发,我们利用AF-VAE,它可以通过在框架之前提供条件几何相关的附加存储以及两种轻量级网络设计策略来弥补VAE的缺点。
高保真图像合成:最近,生成具有精细细节和逼真的纹理的高分辨率样本已成为图像合成任务中的一种趋势。例如,pix2pixHD [47]在pix2pix [20]的基础上引入了从粗到精的生成器,多尺度鉴别器和特征匹配损失。它可以将面部边缘转换为分辨率为1024×1024的逼真面部图像,但是它需要成对的训练数据,因此无法推广到任意边缘。[8]利用渐进式GAN在离散的one-hot属性的控制下生成512×512人脸图像。 IntroVAE [17]提出以内省的方式联合训练其推论和生成器,以达到1024×1024的分辨率。BigGAN [4]修改了正则化方案和采样技术,以对有条件的GAN进行分类,以在ImageNet上实现512分辨率。虽然所有这些框架都只能不受控制地生成或离散地进行属性编辑,但我们的框架专注于挑战高保真度的面部操作,而无需利用配对的训练数据。
3 方法
在本节中,我们探索操纵面部表情/旋转和扩大模态训练的方法,来详细了解我们体系结构设计的好处。首先在这里定义符号,给定来自数据集X的面部图像x,我们的任务是学习以目标面部结构信息c为条件的映射G 来转换x到输出图像 x ~ \tilde x x~。这项任务背后的内在挑战是在高保真度设置和剧烈结构变化的条件下保持面部外观不变。在这种情况下,我们将映射G分解为 ϕ a p p \phi_{app} ϕapp和 μ s t r \mu_{str} μstr,期望分别学习姿势不变的外观表示 z = ϕ a p p ( x , c ) z =\phi_{app}(x,c) z=ϕapp(x,c) 和合理的结构表示 y = μ s t r ( c ) y =μ_{str}(c) y=μstr(c)。
这样,通过最大化条件数据对数似然度 p ( x ∣ y ) p(x|y) p(x∣y)的下限,可以将条件变分自编码器(C_VAE)定制为基线,使其具有解耦z和y的哪能力:
log p ( x ∣ y ) ≥ E q [ log p ( x ∣ z , y ) ] − D K L [ q ( z ∣ x , y ) , p ( z ∣ y ) ] (1) \log p(x|y)\geq \mathbb E_q[\log p(x|z,y)]-D_{KL}[q(z|x,y),p(z|y)]\tag{1} logp(x∣y)≥Eq[logp(x∣z,y)]−DKL[q(z∣x,y),p(z∣y)](1)
其中, q ( z ∣ x , y ) q(z | x,y) q(z∣x,y)是后验 p ( z ∣ y ) p(z | y) p(z∣y)的近似分布。具体来说, q ( z ∣ x , y ) q(z | x,y) q(z∣x,y)和 p ( x ∣ z , y ) p(x | z,y) p(x∣z,y)分别是编码器和解码器。通常使用以下随机目标训练模型:
L ( x , ϕ , φ ) = − 1 N ∑ i = 1 N log p φ ( x i ∣ z i , y i ) + D K L [ q ϕ ( z ∣ x , y ) , p ( z ∣ y ) ] , s . t . ∀ i ~ q ϕ ( z ∣ x , y ) (2) L(x,\phi,\varphi)=-\frac{1}{N}\sum_{i=1}^N\log p_{\varphi}(x^i|z^i,y^i)+D_{KL}[q_{\phi}(z|x,y),p(z|y)]\quad,s.t.\forall i~q_\phi(z|x,y)\tag{2} L(x,ϕ,φ)=−N1i=1∑Nlogpφ(xi∣zi,yi)+DKL[qϕ(z∣x,y),p(z∣y)],s.t.∀i~qϕ(z∣x,y)(2)
其中 ϕ \phi ϕ和 φ \varphi φ是编码器和解码器的参数,可通过重新参数化技巧来学习[21]。通常将 q ϕ ( z ∣ x , y ) q_\phi(z | x,y) qϕ(z∣x,y)限制为N(0,I)上的分布[21]。
但是,在问题的表述下要讨论三个问题:(1)如何准确地解开潜在空间以保证z与结构先验y互补,只具有外观信息。(2)KL散度项促进了学习到的潜在空间的结构接近N(0,I)上的先验p(z | y)。此选择是否满足编码器对面部样本多样性的建模?(3)合成结果的感知质量是否对仅重建和KL散度损失的观看者有吸引力?我们关注这些选择在面部操作方面的最优性,并在以下部分中探索更好的解决方案。我们的框架概述如图2(a)所示。
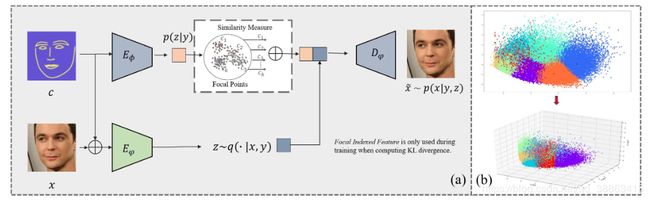
图2:(a) 我们的模型框架(b)5000个面部结构表示的2D和3D投影。每个颜色表示一个群集,我们方法的更直观的说明是将每个群集映射到高斯先验,从而扩展了由单优先级约束的C-VAE的容量。
3.1 几何向导解耦
为了任意操纵人脸图像,应在c中提供足够的几何信息。典型可选择的操纵条件包括面部标志(facia landmarks),3DMM参数和蒙版。基于Pix2pixHD [47]中使用的稀疏地标信息,我们使用[52]中的离线插值处理来获得边界图。该离线过程被公式化为 c = F ω ( x ) c=F_\omega(x) c=Fω(x)。潜在结构表示y可以通过使用编码器 E μ E_\mu Eμ编码c来获得。
在没有任何语义假设的情况下,框架只能确保从x提取的潜在代码z不变于结构。为此,我们利用提取的几何信息y显式地分解潜在空间。具体来说,y与推断的外观表示z级联。然后,级联表示被馈送到解码器 D φ D_\varphi Dφ。在 E μ E_\mu Eμ和 D φ D_\varphi Dφ之间的跳跃连接被进一步合并以潜在地确保从先验(即,解码器 D φ D_\varphi Dφ)获得足够的结构信息。因此,鼓励z对有关外观的信息进行编码,而不是对结构进行编码,否则,对于较大的重建误差,将产生似然性 p ( x ∣ y , z ) p(x | y,z) p(x∣y,z)的损失。
3.2 附加存储编码
尽管显式的几何学指导的解开有助于保持脸部结构以及构造对几何形状具有不变性的潜在的外观表现形式,但仍然难以满足对细粒度面部操作的要求。如图8所示,具有极端表达或在野外环境下的合成结果很容易崩溃为“平均表情”现象。C-VAE公式被限制为从简单的结构(通常为零均值单位方差高斯)中得出先验 p ( z ∣ y ) p(z | y) p(z∣y)。但是,年龄,肤色,亮度和姿势等因素构成了复杂的分布,这打破了通常的假设。因此,在训练过程中,某些特殊的面部特征可能会成为分布的“异常值“。
为此,为了体面的外观表示,将探索对先验结构的更好选择。直观地,从简单分布的组合中提取复杂的先验将增加潜在代码z的多样性,同时能够计算闭合形式。
因此,我们鼓励外观表示具有由K簇组成的多模式结构,每一簇都与一个语义特征相对应。在实践中,我们通过对训练集中的所有边界进行K-均值聚类来构造存储库。每个聚类中心都称为焦点,它通常是指独特的特征,例如笑声或侧脸。这样,训练中使用的每个边界图将具有k维焦点索引特征: w ( b ) = ( w 1 ( b ) , w 2 ( b ) , ⋯ , w k ( b ) ) w(b)=(w_1(b),w_2(b),\cdots,w_k(b)) w(b)=(w1(b),w2(b),⋯,wk(b)),表示其与每个焦点的相似性度量。焦点索引功能用于训练中,以增强潜在表示中的多样性和丰富的外观。由于外部存储器包含较大的几何变化,因此总体思路是利用焦点提供的明确而简洁的空间语义指导来建立潜在的表示能力。通过将 p ( z ∣ y ) p(z | y) p(z∣y)建模为高斯混合,对于每个具有权重 w k w_k wk,均值 μ k \mu_k μk和标准偏差 σ k \sigma_k σk的聚类k,我们具有:
p ( z ∣ y ) = ∑ k = 1 N w k N ( z ∣ μ k , σ k 2 I ) (3) p(z|y)=\sum_{k=1}^Nw_kN(z|\mu_k,\sigma_k^2I)\tag{3} p(z∣y)=k=1∑NwkN(z∣μk,σk2I)(3)
但是,由于事先无法通过GMM优化等式(2),因此在训练中需要接近KL散度,并根据其概率从一个集群中采样z。因此,此操作无法对包含多个面部几何图形特征(例如,同时具有笑声和侧脸)的目标进行建模。因此,我们在框架之前引入了附加焦点,其公式为:
p ( z ∣ y ) = N ( z ∣ ∑ k = 1 K w k μ k , σ 2 I ) (4) p(z|y)=N(z|\sum_{k=1}^Kw_k\mu_k,\sigma^2I)\tag{4} p(z∣y)=N(z∣k=1∑Kwkμk,σ2I)(4)
其中 σ 2 I \sigma^2I σ2I是一个协方差矩阵( σ 2 = ∑ k = 1 K w k 2 σ k 2 \sigma^2=\sum_{k=1}^Kw_k^2\sigma_k^2 σ2=∑k=1Kwk2σk2)。在公式之后,我们假设人脸图像包含多重具有权重 w k w_k wk的多重结构特征。该值对应于每个焦点的相似性测量值,这由归一化余弦距离定义。簇的均值 μ \mu μ在单位球上被随机初始化。KL项可以通过 q ( z ∣ x , y ) = N ( z ∣ μ ( x , y ) , σ 2 ( x , y ) I ) q(z|x,y)=N(z|\mu(x,y),\sigma^2(x,y)I) q(z∣x,y)=N(z∣μ(x,y),σ2(x,y)I)计算得到,可得:
D K L = log ( σ σ ϕ ) + 1 2 σ 2 E q ϕ [ ( z − ∑ k = 1 K w k μ k ) 2 ] − 1 2 = log ( σ σ ϕ ) + σ ϕ 2 + ( μ p h i − ∑ k = 1 K w k μ k ) 2 2 σ 2 − 1 2 (5) D_{KL}=\log(\frac{\sigma}{\sigma_\phi})+\frac{1}{2\sigma^2}E_{q_\phi}[(z-\sum_{k=1}^Kw_k\mu_k)^2]-\frac{1}{2}\\\quad\\=\log(\frac{\sigma}{\sigma_\phi})+\frac{\sigma_\phi^2+(\mu_phi-\sum_{k=1}^Kw_k\mu_k)^2}{2\sigma^2}-\frac{1}{2}\tag{5} DKL=log(σϕσ)+2σ21Eqϕ[(z−k=1∑Kwkμk)2]−21=log(σϕσ)+2σ2σϕ2+(μphi−∑k=1Kwkμk)2−21(5)
通过将上述KL项组合到公式2中,我们获得了最终损失函数来训练生成器。
3.3 注意质量的生成
给定一张源图像x和目标边界 b ^ \hat{b} b^,我们可以通过提出的AF-VAE模型操纵图像x的面部表情和头部姿势。参考[6,11]中的方法,我们使用特征匹配损失作为重建损失来克服使用 L 1 / L 2 L_1/L_2 L1/L2损失的模糊结果。但是,从表3可以看出,结果仍然远未达到感官上的吸引力。
有许多因素可能导致合成图像中出现伪像并导致感知质量失真,例如丢失,不稳定的训练过程和网络体系结构。直观地讲,可以通过合并辅助目标函数[13,30]或设计复杂的注意力机制来捕获更好的全局结构来缓解问题[32]。但是,我们首次通过观察和HVS基础转向网络结构中的两个轻量级设计。
代替在解码器中使用反卷积运算来执行上采样,我们在每个上采样层中使用子像素卷积[38]。如图3所示,“棋盘”伪像明显减少了。然而,有趣的是,从具有/不具有子像素的AF-VAE模型生成的重建结果在其直方图上产生相似的分布,并且它们的熵差很小(无子像素为7.6405,有子像素为7.6794,源图像为7.8267)这意味着子像素不会实质性地过滤伪像,而是将其散布到图像的各个部分。但是,HVS根据图像区域不均匀地处理伪影信号。如感知度量学习的任务所示,位于低频区域的伪像或边缘区域的伪像会被强调,而位于高频区域的伪像会被掩盖[31,24,25,56]。因此,我们可以在感知测量的改进上为子像素卷积做一个合理的解释。
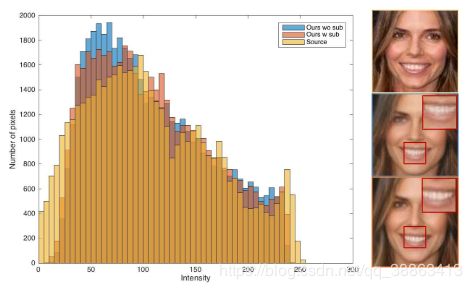
图3:具有/不具有子像卷积的直方图(放大图片获得更好浏览)
另一种技术是我们利用权重归一化(WN)[36]进行模型训练。在基于GAN的方法中习惯性地将BatchNorm(BN)[19]替换为WN或其变体,以稳定辨别器的训练。相反,我们针对AF-VAE的编码器和解码器调整了该策略。经过权重归一化训练的模型与没有WN的训练迭代相比,具有更快的收敛性和更低的重建损失。附录中提供了详细的分析和损失曲线图。此现象类似于GAN。但是,从图8可以看出,WN有助于增加复杂数据集中生成的图像的多样性,使合成结果对于人类观察更为合理,从而提高了感知质量。表3显示,使用WN的综合结果的感知质量比使用BN和不使用BN的模型更好。使IS和FID分别提高57.7%和43.6%。
4 实验
我们的框架提供了一种灵活的方法来将输入的人脸图像处理为任意表情并在边界图的控制下进行姿势变换。在本节中,我们将与4.1节中的最新方法进行定性和定量比较。然后,我们执行自我评估,以在4.2节中分析模型的关键组件。最后,我们在4.3节中讨论了我们方法的局限性。所有实验都是在训练阶段使用来自看不见的图像输出的模型进行的。
实现细节: 训练之前,所有图像被对齐并裁剪为256×256分辨率。使用开源预训练模型获得每个图像的面部landmark。然后,对landmark进行插值以获得面部边界图。对于聚类操作,设置k=8,共8簇,使用K-Means作为聚类算法获取簇的边界。有关更多信息,参考附录中的内容。
数据集: 我们主要在涵盖室内和室外环境的RaFD [23],MultiPIE [12]和CelebA [26]数据集上进行实验,还引入了3D合成的面部数据集,以进一步评估该方法在面部纹理细节(例如照明,复杂度和皱纹)方面的性能。我们使用手掌和猫咪作为非人类数据集,手掌和猫咪数据集的地标分别通过预先训练的手检测器和人类注释获得。对于每个数据集,将使用90%的身份进行训练。将剩余的10%的身份输入模型进行测试。由于空间限制,附录中显示了其他数据集的其他定量和定性结果。
基准线: 我们将模型与基于GAN的三种最新算法进行比较,分别为:StarGAN [9],GANimation [32]和pix2pixHD [47]。为了进行公平的比较,我们使用作者提供的实现对这些模型进行训练,并采用公开可用的预训练模型来获得条件输入,例如用于训练和测试模型的行动单位(AU)或地标。
性能指标: 为了进行定量比较,对于合成结果,我们评估了三个方面:真实性,感知质量和多样性。对于感知质量和多样性的测量,我们使用Fr’echet起始距离(FID,较低的值表示更好的质量)[15]和起始分数(IS,较高的值表示更好的质量)[35]度量。为了达到真实感,我们使用 Amazon Mechanical Turk(AMT)将我们的方法在视觉上的保真度与现有方法进行比较。我们使用每个算法从25个参与者收集的数据来报告TS(TrueSkill)[14]和FR(愚弄率,生成图像成功欺骗用户的估计概率)。每个参与者被要求完成50个试验。
4.1 与现有工作的比较
4.1.1 定性比较
面部表情编辑:我们在Rafd上使用StarGAN,GANimation和pix2pix进行了面部操纵,并提供了7种典型表情。如图4所示,以前的方法在处理诸如256×256分辨率的“厌恶”和“恐惧”等夸张表情时比较脆弱。相反,我们的方法可以消除模糊的伪像,同时保持面部细节。这归功于精细地潜在空间解耦和质量细化的方案。值得注意的是,我们的结果远胜于所有基于GAN的基线,特别是在口和眼的详细纹理方面,它们带来了更高的感知质量。第4.1.2节中的定量评估进一步证明了这一发现。
面部旋转:我们验证了模型以任意定向姿势进行面旋转任务的能力。请注意,在我们的环境中,不需要任何成对的训练样本和外部监督,这与最先进的方法(例如[18,16])有所不同。首先,我们在3D合成人脸数据集上进行了定性实验,以评估模型的详细光/纹理保留性质。通过操纵3D landmark地图转换到新的表情,然后将其投影到2D的视图,得到不同方向的landmark地图。如图5所示,肤色,质地和照明等因素可以很好地保留。这种现象在模型上确定了解耦机制的有效性。接下来,我们在真实数据集上评估其有效性。如图6所示,即使在90度的情况下,我们的模型仍可以通过简单的弱监督方式生成高保真度和逼真的结果。
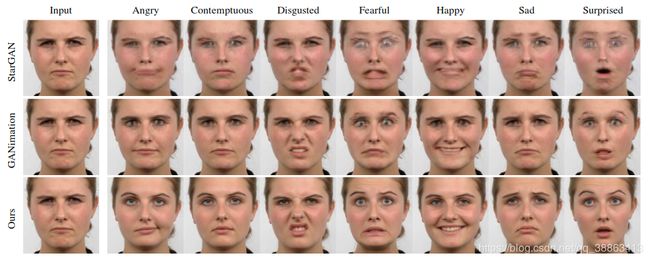 图4:与三种最新算法的比较。(放大以获得更好的细节。左三张图片是输入面部,右三行分别是这三种算法的生成结果。StarGAN[9]和GANimation [32]是当前处理较大的姿势最好的模型,仍会显示一定程度的模糊。最好放大以查看细节。
图4:与三种最新算法的比较。(放大以获得更好的细节。左三张图片是输入面部,右三行分别是这三种算法的生成结果。StarGAN[9]和GANimation [32]是当前处理较大的姿势最好的模型,仍会显示一定程度的模糊。最好放大以查看细节。
 图5:在3D合成人脸数据集上进行人脸旋转。共有6个块,左上方的块代表5个目标边界图。对于每个块,带红色方框的左上角是输入图像,其余五个是与第一个块中的边界图相对应的合成结果。每个光源都有不同的纹理和照明。更好地放大以查看细节。
图5:在3D合成人脸数据集上进行人脸旋转。共有6个块,左上方的块代表5个目标边界图。对于每个块,带红色方框的左上角是输入图像,其余五个是与第一个块中的边界图相对应的合成结果。每个光源都有不同的纹理和照明。更好地放大以查看细节。
 图6:MultiPIE [12]数据集上的面部旋转结果。
图6:MultiPIE [12]数据集上的面部旋转结果。
 图7:手和猫数据集上的实验。(a)显示手操作结果。左边是来源手。在右侧,第一行显示目标手的骨骼,接下来的两行分别代表生成的样本。 (b)(c)(d)是三只猫的操作结果。每行显示一个源目录图像和6个操作结果。
图7:手和猫数据集上的实验。(a)显示手操作结果。左边是来源手。在右侧,第一行显示目标手的骨骼,接下来的两行分别代表生成的样本。 (b)(c)(d)是三只猫的操作结果。每行显示一个源目录图像和6个操作结果。
4.1.2 定量比较
| Model | FID | IS |
|---|---|---|
| Real Data | 0.000 | 1.383 |
| pix2pixHD [47] | 75.376 | 0.875 |
| StarGAN [9] | 56.937 | 1.036 |
| GANimation[32] | 34.360 | 1.112 |
| Ours | 25.069 | 1.237 |
表1:使用FID和IS指标对RaFD数据集进行最新技术的定量比较。
首先,我们评估所生成图像的感知质量和多样性。如表1所示,我们的方法在两种测量方法上都有很大的优势,胜过了当前的最新方法。我们的FID和IS分别比以前的领先方法高1.3倍和1.1倍。
然后,我们使用Amazon Mechanical Turk(AMT)将我们的方法的感知视觉现实与现有方法进行比较。表2报告了AMT真实感任务的结果。我们发现,我们的方法可以比其他方法更好地欺骗参与者。此外,关于TrueSkill,我们的模型更有可能获得用户的青睐,这进一步支持了我们的方法在生成的现实方面超过了这些基线很大的差距。
| Model | Fool Rate (%) | TrueSkill |
|---|---|---|
| StarGAN [9] | 3%±0.4% | 18.1±0.9 |
| pix2pixHD [47] | 4.8%±0.9% | N/A |
| GANimation [32] | 7.0%±1.2% | 24.4±0.8 |
| Ours | 36.4%±2.8% | 32.6±0.9 |
表2:评估用户研究,并与最新技术进行比较。
4.2 消融研究
我们进行消融研究,以分析所提出方法中各个成分的贡献。
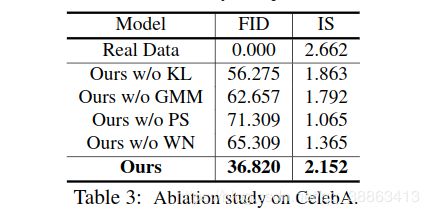
定性消融:如图8所示,如果没有GMM和KL,就无法生成具有较大空间运动的目标,例如张开嘴巴和转过脸。如果没有像素混洗,则生成的面上会出现伪像。没有WN,视觉质量将受到限制。
定量消融:我们根据具有FID和IS度量标准的生成样本的质量来评估每个变体。如表3所示,引入的GMM,像素调整和权重归一化极大地改善了FID和IS得分。从上面的观察推断,每个组件在我们的方法中都有不同的作用,删除其中任何一个都会导致性能下降。
插值结果:为了验证我们的模型学习到的特征分布是密集且清晰的,所生成图像的外观和结构都应分别随潜矢量连续变化。通过在不同样本之间进行插值,我们的模型在图9中显示了照片级逼真的结果,这表明该模型具有很好的概括性和鲁棒性,而不是简单地存储训练数据。
图9:CelebA的插值结果。左上和右下是两个真实图像,每行和每行分别表示潜在外观和结构矢量的线性内插:。
身份保存问题:保持身份是面部生成领域的长期挑战。先前的领先方法[2,37]通常通过使用身份分类器扩展网络来限制合成人脸的多样性来解决此问题。为了研究不同因素对面部身份的影响,我们对 RafD,3D synthetic face 和 EmotionNet 数据集进行了三个实验,如图10所示。我们发现,当修改源图像中的landmark时(图10(a)),或使用其他人的面部轮廓相似的边界(图10(b))作为条件边界图,该模型可以合成保留身份且高保真的人脸图像。相反,当条件边界图的面部轮廓与源图像显着不同时(图10(c)),合成结果的标识趋于多样化。这些观察结果还表明,面部身份信息主要是在结构空间中编码的,如[5,10]中所示。
图10:三种实验设置下的身份保留评估。
4.3 局限性和失败案例
我们在图11中显示了四类故障案例,它们都是挑战我们模型极限的代表性案例。具体而言,第一种情况(左上角)与稀有数据相关。由于在我们的训练样本中很少看到蛋糕,因此该模型可能无法保持样本的语义,并且可能会变得模糊。在右上图中发生了类似的问题,其中源图像中的某些源部分被遮挡了。 当源图像被遮挡时,我们的模型容易混淆,由于模型设计中强大的结构一致性,可能会使遮挡从源头简单地移开。 我们的模型无法很好处理的另一个具有挑战性的情况是特殊样式。 如图11左下所示,当参考人脸边界时,源样式的特性可能会丢失。由于估计的地标可能会与某些属性(例如性别和头部姿势)强烈相关,而这些属性只是在这样的给定边界下施加,因此结果图像可能会简单地将这些属性与我们的目标外观进行变形,如图11右下部所示。 通过简单地变形结构,目标结果是不自然的并且失去身份。
 图11:故障案例。从CelebA和EmotionNet数据集中选择所有四个失败案例。我们在左侧表示源图像,然后是操纵结果及其边界参考。
图11:故障案例。从CelebA和EmotionNet数据集中选择所有四个失败案例。我们在左侧表示源图像,然后是操纵结果及其边界参考。
5 结论
在本文中,我们提出了一种用于面部操作的附加焦点变化自动编码器(AF-VAE)框架,该框架能够对面部结构和外观之间的复杂交互进行建模。基于HVS设计的轻量级体系结构可提供更好的合成结果。它推动了当前关于面部合成的工作,包括生成质量和适应极端操作设置,以及其简单的结构和稳定的训练过程。我们希望我们的工作可以在这个方向上阐明更多的线索。
参考文献
- jianmin Bao, Dong Chen, Fang Wen, Houqiang Li, and GangHua. CVAE-GAN: fine-grained image generation through asymmetric training. In ICCV, 2017.3
- Jianmin Bao, Dong Chen, Fang Wen, Houqiang Li, and GangHua. Towards open-set identity preserving face synthesis. InCVPR, 2018.2,7
- Volker Blanz and Thomas Vetter. A morphable model forthe synthesis of 3d faces. InProceedings of the 26th an-nual conference on Computer graphics and interactive tech-niques, 1999.2
- Andrew Brock, Jeff Donahue, and Karen Simonyan. Largescale gan training for high fidelity natural image synthesis.arXiv preprint arXiv:1809.11096, 2018.3
- Chen Cao, Yanlin Weng, Shun Zhou, Yiying Tong, and KunZhou. Facewarehouse: A 3d facial expression databasefor visual computing.IEEE Trans. Vis. Comput. Graph.,20(3):413–425, 2014.8
- Qifeng Chen and Vladlen Koltun. Photographic image syn-thesis with cascaded refinement networks. InICCV, 2017.5
- Ying-Cong Chen, Huaijia Lin, Michelle Shu, Ruiyu Li, XinTao, Xiaoyong Shen, Yangang Ye, and Jiaya Jia. Facelet-bank for fast portrait manipulation. InCVPR, 2018.2
- Zeyuan Chen, Shaoliang Nie, Tianfu Wu, and Christopher G.Healey. High resolution face completion with multiple con-trollable attributes via fully end-to-end progressive genera-tive adversarial networks.arXiv preprint arXiv:1801.07632,2018.3
- Yunjey Choi, Minje Choi, Munyoung Kim, Jung-Woo Ha,Sunghun Kim, and Jaegul Choo. Stargan: Unified genera-tive adversarial networks for multi-domain image-to-imagetranslation. InCVPR, 2018.2,5,6,7
- Jiankang Deng, Shiyang Cheng, Niannan Xue, YuxiangZhou, and Stefanos Zafeiriou. Uv-gan: Adversarial facialuv map completion for pose-invariant face recognition. InCVPR, 2018.8
- Patrick Esser, Ekaterina Sutter, and Bj ̈orn Ommer. A varia-tional u-net for conditional appearance and shape generation.InCVPR, 2018.5
- Ralph Gross, Iain Matthews, Jeffrey Cohn, Takeo Kanade,and Simon Baker. Multi-pie.Image and Vision Computing,2010.5,6
- Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, VincentDumoulin, and Aaron C Courville. Improved training ofwasserstein gans. InNIPS, 2017.5
- Ralf Herbrich, Tom Minka, and Thore Graepel. Trueskill: abayesian skill rating system. InNIPS, 2007.6
- Martin Heusel, Hubert Ramsauer, Thomas Unterthiner,Bernhard Nessler, and Sepp Hochreiter. Gans trained by atwo time-scale update rule converge to a local nash equilib-rium. InNIPS, 2017.2,6
- Yibo Hu, Xiang Wu, Bing Yu, Ran He, and Zhenan Sun.Pose-guided photorealistic face rotation. InCVPR, 2018.2,6
- Huaibo Huang, Zhihang Li, Ran He, Zhenan Sun, andTieniu Tan. Introvae: Introspective variational autoen-coders for photographic image synthesis.arXiv preprintarXiv:1807.06358, 2018.3
- Rui Huang, Shu Zhang, Tianyu Li, and Ran He. Beyondface rotation: Global and local perception gan for photoreal-istic and identity preserving frontal view synthesis. InICCV,2017.6
- Sergey Ioffe and Christian Szegedy. Batch normalization:Accelerating deep network training by reducing internal co-variate shift.arXiv preprint arXiv:1502.03167, 2015.5
- Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A.Efros. Image-to-image translation with conditional adver-sarial networks. InCVPR, 2017.3
- Diederik P. Kingma and Max Welling. Auto-encoding vari-ational bayes. InICLR, 2014.2,3
- Jean Kossaifi, Linh Tran, Yannis Panagakis, and Maja Pantic.Gagan: Geometry-aware generative adversarial networks. InCVPR, 2018.2
- Oliver Langner, Ron Dotsch, Gijsbert Bijlstra, Daniel HJWigboldus, Skyler T Hawk, and AD Van Knippenberg. Pre-sentation and validation of the radboud faces database.Cog-nition and emotion, 2010.5
- Kwan-Yee Lin and Guanxiang Wang. Hallucinated-iqa: No-reference image quality assessment via adversarial learning.InCVPR, 2018.5
- Xialei Liu, Joost van de Weijer, and Andrew D. Bagdanov.Rankiqa: Learning from rankings for no-reference imagequality assessment. InICCV, 2017.5
- Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang.Deep learning face attributes in the wild. InICCV, 2015.2,5
- Yongyi Lu, Yu-Wing Tai, and Chi-Keung Tang. Attribute-guided face generation using conditional cyclegan. InECCV,2018.2
- Liqian Ma, Xu Jia, Qianru Sun, Bernt Schiele, Tinne Tuyte-laars, and Luc Van Gool. Pose guided person image genera-tion. InNIPS, 2017.2
- Liqian Ma, Qianru Sun, Stamatios Georgoulis, LucVan Gool, Bernt Schiele, and Mario Fritz. Disentangled per-son image generation. InCVPR, 2018.2
- Xudong Mao, Qing Li, Haoran Xie, Raymond YK Lau, ZhenWang, and Stephen Paul Smolley. Least squares generativeadversarial networks. InICCV, 2017.5
- Da Pan, Ping Shi, Ming Hou, Zefeng Ying, Sizhe Fu, andYuan Zhang. Blind predicting similar quality map for imagequality assessment. InCVPR, 2018.5
- Albert Pumarola, Antonio Agudo, Aleix M. Martinez, Al-berto Sanfeliu, and Francesc Moreno-Noguer. Ganimation:Anatomically-aware facial animation from a single image. InECCV, 2018.2,5,6,7
- Shengju Qian, Wayne Wu, Yangxiaokang Liu, Beier Zhu,and Fumin Shen. Extending the capacity of cvae for facesynthesis and modeling. InNeurIPS Workshops, 2018.3
- Fengchun Qiao, Naiming Yao, Zirui Jiao, Zhihao Li, HuiChen, and Hongan Wang. Geometry-contrastive generativeadversarial network for facial expression synthesis.arXivpreprint arXiv:1802.01822, 2018.2
- Tim Salimans, Ian Goodfellow, Wojciech Zaremba, VickiCheung, Alec Radford, and Xi Chen. Improved techniquesfor training gans. InNIPS, 2016.6
- Tim Salimans and Diederik P Kingma. Weight normaliza-tion: A simple reparameterization to accelerate training ofdeep neural networks. InNIPS, 2016.5
- Yujun Shen, Ping Luo, Junjie Yan, Xiaogang Wang, and Xi-aoou Tang. Faceid-gan: Learning a symmetry three-playergan for identity-preserving face synthesis. InCVPR, 2018.2,7
- Wenzhe Shi, Jose Caballero, Ferenc Husz ́ar, Johannes Totz,Andrew P Aitken, Rob Bishop, Daniel Rueckert, and ZehanWang. Real-time single image and video super-resolutionusing an efficient sub-pixel convolutional neural network. InCVPR, 2016.5
- Zhixin Shu, Mihir Sahasrabudhe, Riza Alp G ̈uler, DimitrisSamaras, Nikos Paragios, and Iasonas Kokkinos. Deform-ing autoencoders: Unsupervised disentangling of shape andappearance. InECCV, 2018.3
- Zhixin Shu, Ersin Yumer, Sunil Hadap, Kalyan Sunkavalli,Eli Shechtman, and Dimitris Samaras. Neural face editingwith intrinsic image disentangling. InCVPR, 2017.3
- Kihyuk Sohn, Honglak Lee, and Xinchen Yan. Learningstructured output representation using deep conditional gen-erative models. InNIPS, 2015.2
- Justus Thies, Michael Zollhofer, Marc Stamminger, Chris-tian Theobalt, and Matthias Nießner. Face2face: Real-timeface capture and reenactment of rgb videos. InCVPR, 2016.2
- Luan Tran and Xiaoming Liu. Nonlinear 3d face morphablemodel. InCVPR, 2018.2
- Luan Tran and Xiaoming Liu. On learning 3d face mor-phable model from in-the-wild images.arXiv preprintarXiv:1808.09560, 2018.2
- Liwei Wang, Alexander Schwing, and Svetlana Lazebnik.Diverse and accurate image description using a variationalauto-encoder with an additive gaussian encoding space. InNIPS, 2017.3
- Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Guilin Liu,Andrew Tao, Jan Kautz, and Bryan Catanzaro. Video-to-video synthesis. InNIPS, 2018.2
- Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao,Jan Kautz, and Bryan Catanzaro. High-resolution image syn-thesis and semantic manipulation with conditional gans. InCVPR, 2018.3,5,7
- Wei Wang, Xavier Alameda-Pineda, Dan Xu, Pascal Fua,Elisa Ricci, and Nicu Sebe. Every smile is unique:Landmark-guided diverse smile generation. InCVPR, 2018.2
- Olivia Wiles, A Koepke, and Andrew Zisserman. Self-supervised learning of a facial attribute embedding fromvideo. InBMVC, 2018.2
- Olivia Wiles, A Sophia Koepke, and Andrew Zisserman.X2face: A network for controlling face generation using im-ages, audio, and pose codes. InECCV, 2018.2
- Wayne Wu, Kaidi Cao, Cheng Li, Chen Qian, andChen Change Loy. Transgaga: Geometry-aware unsuper-vised image-to-image translation. InCVPR, 2019.2
- Wayne Wu, Chen Qian, Shuo Yang, Quan Wang, Yici Cai,and Qiang Zhou. Look at boundary: A boundary-aware facealignment algorithm. InCVPR, 2018.3
- Wayne Wu, Yunxuan Zhang, Cheng Li, Chen Qian, andChen Change Loy. Reenactgan: Learning to reenact facesvia boundary transfer. InECCV, 2018.2
- Ceyuan Yang, Zhe Wang, Xinge Zhu, Chen Huang, JianpingShi, and Dahua Lin. Pose guided human video generation.InECCV, 2018.2
- Xi Yin, Xiang Yu, Kihyuk Sohn, Xiaoming Liu, and Man-mohan Chandraker. Towards large-pose face frontalizationin the wild. InICCV, 2017.2
- Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman,and Oliver Wang. The unreasonable effectiveness of deepfeatures as a perceptual metric. In CVPR, 2018.510042