常见问题集锦
- MLSQL 架构图有么?
- 用Docker一键安装后,注册时出现 No identifer specified for entity: tech.mlsql.model...?
- 数据源有详细参数配置文档么?...
- 后台是怎么区分batch还是streaming的?比如我load kafka,同时又load hbase,mysql或者es,这种情况下底层对应的作业时 streaming的还是batch的,逻辑都是在window范围内执行的吗
- engine本身是个spark的app,里面提供的restful服务,那么这个服务可以是高可用的吗?
- 权限管理 比如A,B,C 3张表 允许用户查询A表,BC两张不可查 这种授权是自己写client实现吗?
- 如果udf的代码比较多,同时又import了很多第三方的jar包,怎么处理?
- udf 依赖的第三方jar如果加载?
- 哪里有MLSQL三套件的http接口文档
- 借助mlsql完成注册的udf,能不能通过api服务的形式暴露出来,然后直接在scala代码里调用呢
- 为什么cluster 和 console 启动会出现:Too many connections
- 为什么cluster 和 console 会出现 org.hibernate.AnnotationException: No identifier specified for entity:tech.mlsql.model...
- 使用python project 时出现 should be a directory which contains MLproject file or directly a python file 错误。
- Python执行失败该如何排查问题?
- 在Console执行最简单的命令显示"Error 500" 错误。
- 如何知道load/save数据源都有哪些where参数可以配置?
- AbstractMethodError 一般是什么问题?
- 字面量包含#怎么办?
- 启动是jetty/jersray
- mlsql做数据中台,对mysql查询速度,跟系统直连mysql查询速度比较会不会效率差点
- Mlsql engine 有集成日志模块吗,目前只能依靠nohup打印
- carbondata只能在spark 2.2.x 和 spark 2.3.1版本里使用 是吧
- 提示 Could not initialzize class steaming.core.datasourc.DataSourceRegistry$
MLSQL 架构图有么?

MLSQL Console 包含了几个组件,分别是
- script center (脚本管理体系)
- auth center (权限体系)
- web (交互探索使用)
- api (供接口调用)
其中1,2 会被后端的MLSQL Engine回调,从而实现一系列功能。
MLSQL Cluster 主要是为了方便多租户,多Engine实例管理,你可以理解为一个路由功能(虽然不局限于此)。在MLSQL Console中,默认每个Engine实例都会被打上一组team_role标签,这样就可以给任何一个role配置一个或者多个MLSQL Engine,从而实现例如负载均衡等功能。
MLSQL Engine 底层基于Spark Engine,是一个典型的master-slave结构,在原生的Spark SQL之上,我们提供了MLSQL语言,从而更好的满足复杂交互诉求,比如批处理脚本,机器学习,邮件发送等等。
大家可以一键体验上面的所有功能:MLSQL生态一键体验
用Docker一键安装后,注册时出现 No identifer specified for entity: tech.mlsql.model...?
这个可能是数据库初始化没有正确完成。请仔细看看docker安装脚本是否有错误输出。为了获得帮助,你可以在Issue 页面详细贴出您的所有输出。
数据源有详细参数配置文档么?比如kafka,我可以理解成kafka consumer的配置都可以写到option里面吗
MLSQL大部分数据源集成的是第三方实现。比如excel的支持得益于spark-excel项目。同样,Kafka的配置参数和Spark 对Kafka的需求配置是一样的,JDBC则也是标准的Spark文档中描述的那样。不过大部分人使用时,不会使用所有参数,
MLSQL也提供了两种方式展示可选参数:
- 使用MLSQL Console, Console支持参数自动补全

MLSQL Console 实现了数据源和参数联动。不过目前只有部分数据源支持,我们会尽快覆盖所有数据源。
- 使用帮助语句。
查看所有数据源:
load _mlsql_.`datasources` as output;
查看具体某个数据源的可选参数:
load _mlsql_.`datasources/params/excel` as output;
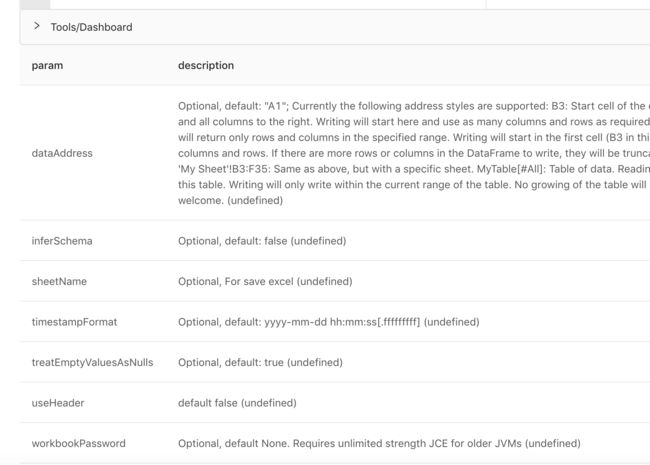
除了数据源,其他所有MLSQL特有模块,也都是支持前面两种方式的。比如,我想查看BigDL模块的示例:

接着就可以看到:

或者通过命令查看所有可选参数:
load modelParams.`BigDLClassifyExt` as output;
后台是怎么区分batch还是streaming的?比如我load kafka,同时又load hbase,mysql或者es,这种情况下底层对应的作业时streaming的还是batch的,逻辑都是在window范围内执行的吗
后台是根据 set streamName="streamExample";因为流式计算我们需要用户定义一个唯一的名字。MLSQL底层是使用spark structured streaming,所以structured streaming存在的限制,MLSQL都存在。structured streaming支持对静态数据的Join。如果您需要深入,请多了解structured streaming。
engine本身是个spark的app,里面提供的restful服务,那么这个服务可以是高可用的吗?
Engine自身无法保证高可用,但是你可以通过如下两种方式的一种保持其高可用:
第一是部署环境比如在yarn-cluster模式下,Engine支持将自己注册到ZK中,而Yarn又能保证driver挂掉后自动找一个其他节点启动,但在yarn-client模式则不行。
第二个是,通过MLSQL-Cluster来完成。MLSQL-Cluster 现在实现了多策略的负载均衡,以及多集群的管理。通过负载均衡,也可以保证Engine的高可用,比如后端部署三个Engine,任意down掉两个,都不影响。
权限管理 比如A,B,C 3张表 允许用户查询A表,BC两张不可查
这种授权是自己写client实现吗?
MLSQL Console已经实现了一个。你也可以参考它实现自己的。MLSQL 架构足够灵活可以让你做很多定制扩展。为了实现A,B,C,三张表的授权,大致有如下几个流程:
*** 配置Team ***
- 创建一个Team 比如: TestTeam(有则忽略)
- 邀请用户到Team
- 给Team添加Role
- 给Team添加表资源
*** 配置Role***
- 给Role添加一个Bakend(有则忽略)
- 将需要的表权限授Role
- 将用户角色设置为需要的Role
*** 用户自身配置 ***
用户登陆后,可能在多个team,多个role里,所以他需要配置下自己默认运行的Backend(MLSQL Engine)是什么。
如果是在MLSQL Console 里操作如上流程:
- 创建TestTeam

- 创建Role

2.1 给Role指定一个Backend:

- 邀请用户到特定Role

- 创建A,B,C三张表

- 给Role添加表权限
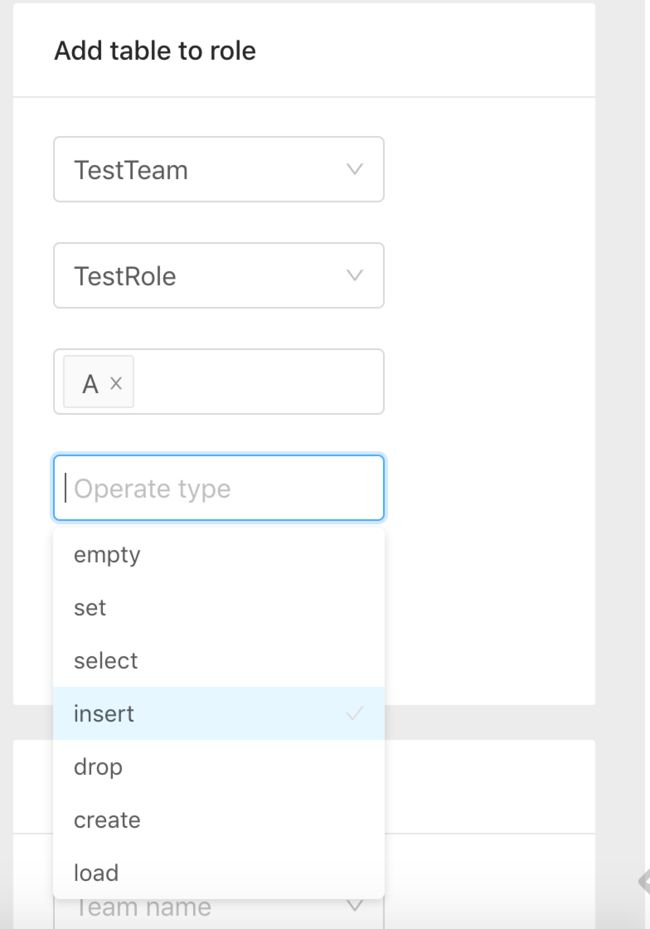
- 被授权用户将自己默认的Backend设置为新的:

现在被授权用户可以正常使用了。
如果udf的代码比较多,同时又import了很多第三方的jar包,怎么处理?
MLSQL自身的项目已经非常庞大,理论上你UDF要的库,都有了。如果没有,你需要用--jars带上。某些场景可能还需要配置driver/executor classpath,不过最简单的方案是把你的jar包放到spark 发型包里。
udf 依赖的第三方jar如果加载?
解决类似问题:写了一个udf ,用了一个fastjson第三方包,把fastjson放到engine的--jars 启动,运行时报错找不到fastjson
- 将第三方 Jar 包分发到所有的 $SPARK_HOME/jars 目录下
- 在$SPARK_HOME/conf/spark-default.conf 中添加 spark.driver.extraClassPath 和 spark.executor.extraClassPath 这两个属性, 后多个jar使用":"分隔
- 启动时增加 --jar 第三方jar --driver-class-path 第三方jar
哪里有MLSQL三套件的http接口文档
因为三者都是通过ServiceFramework框架实现的,所以他们都可以通过 http://ip:port/openapi/ui/spec/ 进行查看。下面是mlsql-engine的例子:

借助mlsql完成注册的udf,能不能通过api服务的形式暴露出来,然后直接在scala代码里调用呢
是的,MLSQL提供了暴露函数的能力。假设你提供的函数为substring,那么你可以这么使用:
curl -X POST \
http://127.0.0.1:9003/model/predict \
-H 'content-type: application/x-www-form-urlencoded' \
-d 'data=%5B%7B%22feature%22%3A%22%E7%B3%96%E5%B0%BF%E7%97%85%E6%80%8E%E4%B9%88%E5%8A%9E%E5%91%A2%EF%BC%9F%E6%88%91%E4%B9%9F%E4%B8%8D%E5%A4%AA%E6%B8%85%E6%A5%9A%22%7D%5D&dataType=row&sql=select%20substring(feature%2C0%2C3)%20as%20p'
转义钱的url请求参数:

格式形态如下:
dataType=row
data=[{"feature":[1,2,3...]}]
sql=select bayes_predict(vec_dense(feature)) as p
返回结果:
这个本质上是为了ET,以及算法模型提供的功能,但是你也可以把他用作函数API。
为什么cluster 和 console 启动会出现:Too many connections
一般错误如下:

可以修改application.yml文件:

将连接池的初始化值调小。
为什么cluster 和 console 会出现 org.hibernate.AnnotationException: No identifier specified for entity:tech.mlsql.model...
一般错误如下:

主要是数据库的表没有更新,先删除所有表,然后使用使用对应项目 resources目录下的db.sql 文件重新创建一次所有的表。
使用python project 时出现 should be a directory which contains MLproject file or directly a python file 错误。
一般错误类似这个:

一般是因为两个原因
- 对应的路径里没有MLproject文件,请确保你按要求组织了python项目的结构。
- 该路径一般为HDFS路径。不要和本地路径混淆。
Python执行失败该如何排查问题?
比如如下问题:

下面的FileNotFoundException是由前面的python脚本执行失败导致的。所以我们只要关注前面的异常即可。前面的异常显示,我们正确的切换了Python环境,并且执行python train.py 0.5 0.1 ,但是这个train.py脚本执行失败了。那么为什么失败呢?我们需要继续往上翻日志,大家可以通过 [email protected](你的用户名) 进行过滤,里面会有Python详细的执行错误信息。如果出现的缺少某个pip包,那么一般是环境创建的有问题,可以删除对应的环境重复执行即可Python环境管理工具。如果是其他的错误,则可能是你写的脚本存在问题,具体问题要具体查看。
在Console执行最简单的命令显示"Error 500" 错误。
典型的如下图:

我们可以先看Console的日志,其次是Cluster的日志,最后才是Engine的日志。 在看Cluster的日志时,我们发现了问题,日志大概是这样的。

可以看到,发生了500错误,并且是因为Response的问题,也就是Cluster 到 Engine 的请求后的Response异常。再网上看,
Error when remote search url: [http://....:9003/run/script]
也就是访问Engine后端失败了。那这个时候可以回想下是不是这个URL地址确实是网络不通的。
如何知道load/save数据源都有哪些where参数可以配置?
MLSQL Engine 数据源的配置参数,可以通过类似下面的命令获取。

MLSQL Console的参数实现也是基于该接口完成的:

目前还只有少量数据源支持该接口。我们会继续完善。
AbstractMethodError 一般是什么问题?
比如如下的错误:

这一般是你编译时和运行时的Spark版本不统一导致的。
- 字面量包含#怎么办?
比如如下代码:
set abc='''
start ###{}### end
''';
load csvStr.`abc` as output;
因为#是一个特殊的指令,所以这么加载是有问题的。可以按如下方式解决:
set sharp='''
#[[#]]#
''';
set abc='''
start #[[###]]#{}#[[###]]# end
${sharp}
''';
load csvStr.`abc` as output;
mlsql做数据中台,对mysql查询速度,跟系统直连mysql查询速度比较会不会效率差点
mlsql有directquery模是,直连mysql:

对的directquery是没有额外性能损耗的。不过我们正在努力解决权限相关的问题。然后就是,如果不采用directquery,性能和原生mysql比,取决于你的SQL语句。有可能更快也可能很慢。
Mlsql engine 有集成日志模块吗,目前只能依靠nohup打印
MLSQL Stack是可以实时回显日志的,你需要在你driver的机器 手动创建一个目录: /tmp/mlsql/logs/ 。
如果你们希望自己获取到日志(轮训),可以调用
load _mlsql_.`log/[offset]` where filePath="/tmp/__mlsql__/logs/mlsql_engine.log" as output;
其中offset 每次会返回一个新值给你。
carbondata只能在spark 2.2.x 和 spark 2.3.1版本里使用 是吧
carbondata好像只能在2.2.0里用,原因是因为carbondata没有在maven仓库上传这个版本以外的版本,我们已经推动carbondata的同学解决这个问题了。
提示 Could not initialzize class steaming.core.datasourc.DataSourceRegistry$
这是运行的spark版本和mlsql engine需要的spark版本不一致引起的。mlsql-engine_2.4-1.2.0 发行包第一个2.4表示该engine发行包需要基于2.4.x 运行。第二个1.2.0表示该engine的版本为1.2.0。 如果你用spark 2.3.3去跑,就会得到类似的错误。
ChatRoom