应该是在四月份的时候,偶然看到这篇分析浅谈分布式存储系统数据分布方法,虽然在几年前就知道一致性hash的原理及应用,但是文中提到的CRUSH不是很清楚,就没有去关注。然后今天在知乎上关注列表中,有位同行分析了下ceph的相关读写过程,才去搜了下资料,原来是个分布式存储系统,就在网上查了些资料,然后看到里面的CRUSH算法,以及原理和应用,也和一致性HASH的不同,比如在节点增加和减少时,数据迁移方面的问题。这里我并没有去研究ceph这个源码,我也不准备在最近去研究,等有时间了再去分析下。我这里借用网上资料,看下ceph的框架,以及读写部分流程,重点是CRUSH具体原理(非源码)。
我们知道一致性hash在hash基础上解决了因为机器增加或减少而需要重新hash全部数据的问题。一致性hash的原理大致是有个整数空间环,然后根据物理节点数量,或者均衡些虚拟化多个节点,划分多个区间,落在某个区间的key顺时针找到最近的节点,存放数据,那么当有新加入或移走的节点时,并不会影响其他的区间,只需要变这个区间即可,但这样还是会有一部分数据的迁移,针对这个问题,CRUSH有较好的解决方法。还有其他诸如划分片的方法。
这里整理下参考资料中一些基本概念,及作用,用于理解ceph的基本组成部分,然后简单分析一个对象是如何进行存和取的(读写操作流程);以及数据迁移过程;

OSD:
用于集群中所有数据与对象的存储。处理集群数据的复制、恢复、回填、均衡。并向其他OSD守护进程发送心跳,然后向Monitor提供一些监控信息。
Monitor:
独立部署的daemon进程,通过组成Monitor集群来保证自己的高可用。Monitor集群通过Paxos算法实现了自己数据的一致性。维护集群的cluster MAP二进制表。ClusterMAP描述了对象块存储的物理位置,以及一个将设备聚合到物理位置的桶列表。Monitor节点中保存了最新的版本集群数据分布图(cluster map)的主副本。客户端在使用时,需要挂载Monitor节点的6789端口,下载最新的cluster map,通过crush算法获得集群中各osd的IP地址,然后再与osd节点直接建立连接来传输数据。所以对于ceph来说,并不需要有集中式的主节点用于计算与寻址,客户端分摊了这部分工作。而且客户端也可以直接和osd通信,省去了中间代理服务器的额外开销。
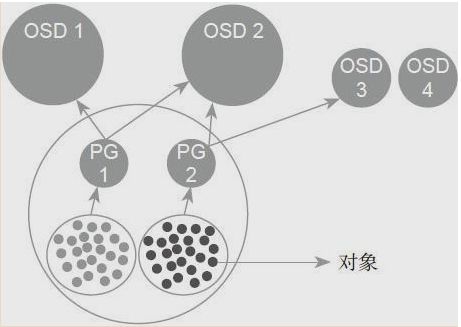
Rados对象是数据存储的基本单元,一般默认4MB大小;用唯一标识一个对象。
OSD是负责物理存储的进程,一般情况下,配置为和磁盘一一对应,一块磁盘启动一个OSD进程;一个OSD上可以分布多个PG;OSD设备是存储rados对象的载体。
PG是OSD之上的一层逻辑,可视其为一个逻辑概念;一个对象只能属于一个PG,一个PG包含很多个对象(rados object);一个PG对应于一个OSD列表,相同PG内的对象都会放到相同的硬盘上;服务端数据均衡和恢复的最小粒度就是PG;
Pool是一个抽象的存储池,它是PG之上的一层逻辑;规定了数据冗余的类型以及对应的副本分布策略;一个pool由多个PG构成,一个PG只能属于一个POOL;
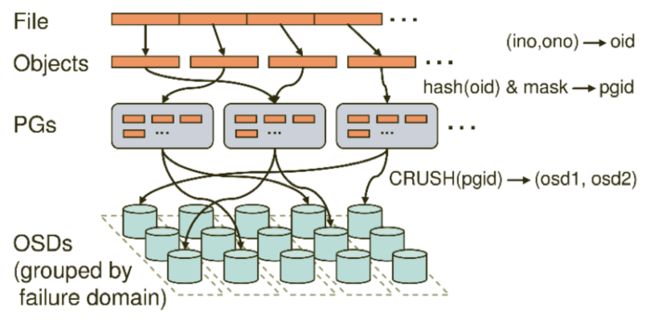

在Ceph存储系统中,数据存储分三个映射过程
首先要将用户要操作的file,映射为RADOS能够处理的object。就是简单的按照object的size对file进行切分,相当于RAID中的条带化过程。
接着把Object映射到PG,在file被映射为一个或多个object之后,就需要将每个object独立地映射到一个PG中去。
第三次映射就是将作为object的逻辑组织单元的PG映射到数据的实际存储单元OSD。
文件存入时,首先把File切分为RADOS层面的Object,每个Object一般为2MB或4MB(大小可设置)。每个Object通过哈希算法映射到唯一的PG。每个PG通过Crush算法映射到实际存储单元OSD,PG和OSD间是多对多的映射关系。

“Ceph的读写操作采用主从模型,客户端要读写数据时,只能向对象所对应的主osd节点发起请求。主节点在接受到写请求时,会同步的向从OSD中写入数据。当所有的OSD节点都写入完成后,主节点才会向客户端报告写入完成的信息。因此保证了主从节点数据的高度一致性。而读取的时候,客户端也只会向主osd节点发起读请求,并不会有类似于数据库中的读写分离的情况出现,这也是出于强一致性的考虑。。。”
crush缺点:
在小规模集群中, 会有一定的数据不均衡现象(权重的影响低,主要起作用的是伪随机算法)。
看清楚了寻址的过程,就明白为啥PG不能轻易变更了;PG是寻址第一步中的取模参数,变更PG会导致对象的PG id 都发生变化,从而导致整个集群的数据迁移;
CRUSH实现简介:
通过每个设备的权重来计算数据对象的分布;在数据迁移过程中,Straw Buckets算法有较好的性能表现,对于osd变动,造成的数据迁移率很小,如下图:


Straw Buckets:这种类型让bucket所包含的所有item公平的竞争(不像list和tree一样需要遍历)。这种算法就像抽签一样,所有的item都有机会被抽中(只有最长的签才能被抽中)。每个签的长度是由length = f(Wi)*hash(x, r, i) 决定的,f(Wi)和item的权重有关,i是item的id号。c(r, x) = MAXi(f(Wi) * hash(x, r, i))。
所以在增加或删除osd时,只要不影响“最长的签”就不会有影响。
具体CRUSH实现源码我在这里不详细介绍,接口是static __u32 crush_hash32_rjenkins1_3(__u32 a, __u32 b, __u32 c)(参数1为pgid,参数2为item,参数3为副本数),有兴趣的可以跟我一样阅读下面资料,会有很大收获的。
大概就介绍些,就当是笔记,后面如果有时间会慢慢分析透彻,里面还有很多知识点值得学习和研究。
浅谈分布式存储系统数据分布方法
Ceph 分布式存储简介
Ceph剖析:数据分布之CRUSH算法与一致性Hash
Ceph官网
ceph工作原理及安装
ceph crush算法不一样的理解,和一致性哈希没关系
Ceph源码解析:CRUSH算法
ceph的CRUSH数据分布算法介绍
大话Ceph--PG那点事儿
大话Ceph--CRUSH那点事儿
Ceph基础概述
Ceph系统架构与基本概念
Ceph简介架构原理和一些基本概念