多尺度目标检测调研(-2019.10)
本文是大概花费1个月时间做的目标检测调研报告,其中有些论文总结是基于个人理解从网上摘录,论文的细节还需找到原始paper阅读。可作为一个目标检测领域研究情况的快速浏览,仅供参考。
目录
多尺度目标检测概况
目标检测常用数据集
目标检测经典论文
基于深度学习检测方法的总结
Anchor方面的改进
Loss方面的改进
NMS -后处理上的优化
其它方法
个人总结
多尺度目标检测概况
今年5月份arxiv出的一篇目标检测综述文章写的特别全面,能帮助你快速了解目标检测领域研究进展。文章链接为:https://arxiv.org/pdf/1905.05055.pdf

多尺度目标检测发展历程:
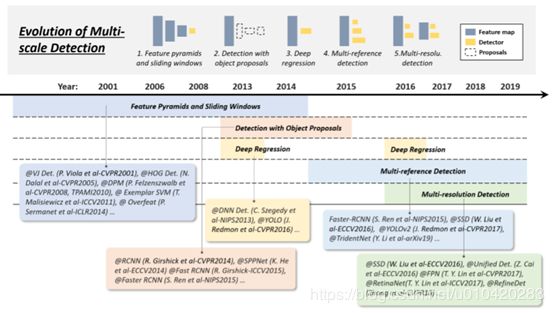
以下是几个重要阶段:
Feature pyramids + sliding windows ( -2014):
梯度方向直方图(HOG)进行行人检测;
可变形的组件模型(Deformable Part Model, DPM):基于组件的检测算法
Object Proposals (2010-2015)
segmentation grouping approaches(分段分组法)
window scoring approaches(窗口评分法)
neural network based approaches(基于神经网络的方法)
Deep regression (2013-2016)
Multi-reference/-resolution detection (2015- )
提前设置一些不同尺寸和纵横比的reference boxes(anchor boxes)
基于深度学习的目标检测方法分为两个分支:one-stage(yolo系列,SSD): 仅使用一个卷积神经网络CNN直接预测不同目标的类别与位置; two-stage(RCNN系列,mask RCNN等): 先产生目标候选框,也就是目标位置,然后再对候选框做分类与回归.
刚开始one-stage的网络和two-stage网络在mAP和速度上各有优劣,one-stage在准确率上一致落后于two-stage,但是近年来对此也出现了很多优化工作。
目标检测的评价主要从两个方面:mAP,FPS
两个检测分支的共同组件是:backbone网络(resnet101,vgg等),Anchor reference, NMS, Loss
目标检测常用数据集
Pascal VOC(VOC07和VOC12),2005-2012,20 classes of object
VOC07:包含5k训练图像+12k 标注目标;
VOC12:11k 训练图像+ 27k 标注目标
ILSVRC(ImageNet Large Scale Visual Recognition Challenge),2010-2017,200 classes of object
图像或者目标实例比VOC大两个数据量级,比如ILSVRC-14包含517k图像和534k个标注目标
MS-COCO,2015- ,
常用的目标检测挑战数据集;
类别比ILSVRC少,但是标注数据更多,比如MS-COCO-17包含80类,其中164k图像和897k目标标注;每一个目标不止有标记框标注,还添加了实例分割标注,以便更精确定位。
MS-COCO小目标(所占区域小于图像总区域的1%)数据更多,更接近真实的自然世界目标识别。
Open Images Detection(OID),2018- ,
Following MS-COCO ,但规模空前:unprecedented scale
Two task:1,标准检测;2. 探测成对object之间的关系
包含600类别:1910k图像,15440k标注
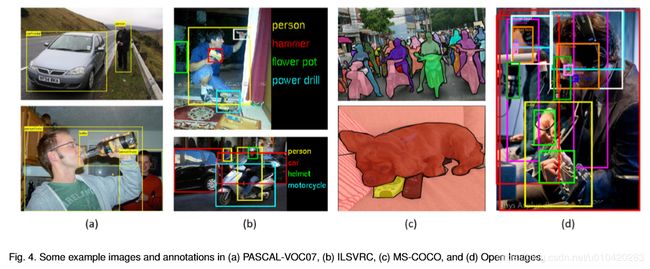
目标检测经典论文
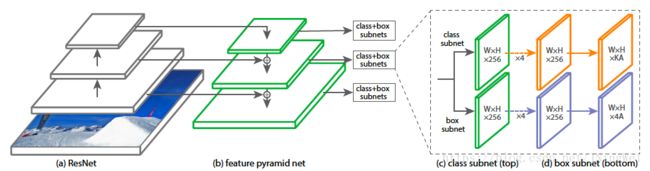
1. RetinaNet (ICCV2017 best paper,facebook, one-stage, code)【loss改进,anchor中前景类别失衡】
One-stage虽快且简单,但accuracy一直落后于two-stage,RetinaNet认为在密集探测器的训练过程中遇到的极端前景背景类失衡是主要原因,提出focal loss代替cross entropy是网络在训练过程中更多关注hard, misclassified examples, 动态调整anchor box的权重,最终在维持高的检测速度同时取得了和two-stage同样的检测accuracy。后面one-stage论文多采用此作为基础网络进行改进。(Resnet+FPN+focal_loss)
2. CornerNet,《CornerNet-Lite: Effcient Keypoint Based Object Detection》,(ECCV2018, one-stage, code)【anchor改进,减少anchor数量】
单阶段检测通过密集的anchor box及后续的增强定位来获得好的检测效果,但使用anchor存在以下几点问题:(1)需要大量的anchor box,然而只有一小部分的anchor box与ground truth 存在较大的重叠,这就会造成类别不平衡问题,而且不利于训练。(2)使用anchor 引入了大量人为的超参数及设计方法。
提出了目标检测算法的新的模型结构,利用单个卷积网络将框的左上角及右下角两个点组成一对关键点,进而不需要设计在单阶段检测中大量的anchor boxes,同时,引入了corner pooling用于提升角点定位效果。
3. RelationNet(CVPR2018 oral, MSRA, two-stage, code)【受attention启发,考虑物体和周围环境之间的关系】
在目标检测中,周围其它物体信息可能和某个物体的分类定位有着帮助作用,这在目前使用ROI的网络中体现不出来,作者考虑改良这种情况,启发于NLP的attention模块,将目标检测任务引入关联性信息。提出了一种object relation module,通过引入不同物体之间的外观和geometry特征做interaction,实现对物体之间relation的建模,提高检测效果,并且将关系模块运用在duplicate remove中,进行可学习的NMS(提出了一种特别的代替NMS的去重模块,可以避免NMS需要手动设置参数的问题),实现了第一个完全end-to-end的目标检测系统。
1)提出一种relation module,可以在以往常见的物体特征中融合进物体之间的关联性信息,同时不改变特征的维数,能很好的嵌进目前各种检测框架,提高性能;2) 在1)的基础上,提出了一种特别的代替NMS的去重模块,避免NMS需要手动设参问题。
4. Cascade RCNN(CVPR2018,two-stage, code)【IOU阈值设为定值的局限性】
作者通过实验证实了不同IOU阈值对于网络的影响,证实固定IOU阈值的训练方式具有局限性。Cascade RCNN由一系列IOU阈值递增训练的探测器组成,达到state-of-art 性能.
5. SNIP, SNIPER,《an analysis of scale invariance in object detection》,(CVPR2018,two-stage, code)【优化多尺度训练时候对过大/过小尺寸目标网络都进行上下采样得到多尺度金字塔的不必要性】
SNIP:文章从COCO数据集开始分析,认为目标检测的难点在于数据集中object的尺寸分布较大,尤其对小目标的检测效果也有待提高,提出Scale Normalization for Image Pyramids(SNIP)算法解决这个问题。针对目标检测的domain-shift问题,提出只对与训练尺度相匹配的目标进行梯度回传策略。
研究表明在进行多尺度训练的时候,实际上忽略一部分过大或者过小的目标是比较有利的。那这样的话,作者就认为我们每次都将全部图片都进行上下采样得到多尺度金字塔实际上没有必要。SNIP的算法忽略掉大图中大的Proposal和小图中的小proposal,在测试时构建一个输入图像金字塔,金字塔上每一张图像只测试该图片指定尺度范围的目标,最终合并做NMS输出结果,但这仍然是全像素的问题。SNIPER是SNIP的升级版本,减少了计算消耗从而使模型运行更快。SNIPER通过生成scale specific context-regions,不管哪个尺度都采样到512x512,这样既保留RCNN的尺度不变性和Fast系列的速度,也由于过滤到了很大一部分背景而比SNIP快很多。
6. RefineDet, 《 Single-Shot Refinement Neural Network for Object Detection 》(CVPR2018, code)【结合one-stage和two-stage的优势,设计的single-shot检测模型】
结合了one-stage方法和two-stage方法各自的优势, 提出了一个基于single-shot的检测模型: 模型主要包含两大模块, 分别是anchor精化模块和物体检测模块. 网络采用了类似FPN的思想, 通过 Transfer Connection Block 将特征图谱在两个模块之间传送, 不仅提升了的精度, 同时还在速度方面取得了与one-stage方案相媲美的表现。
anchor精化模块(anchor refinement module): 1. 过滤掉负样本的anchors, 以减少分类器的搜索空间; 2. 对anchors的位置和size进行粗糙的调整, 以便为后续的回归网络提供更好的初始化状态.
物体检测模块(object detection module):1. 用refined anchors作为输入进行回归预测;2. 设计一个传送连接模块(transfer connection block), 将anchor refinement module里面的特征进行传送, 以此来预测框的位置, size 和类别标签。由于使用了多任务联合损失函数, 因此可以进行端到端的训练。
基于深度学习检测方法的总结
Anchor方面的改进
GA-RPN,《Region proposal by Guided Anchoring》,(CVPR2019,code)【图像特征指导anchor生成】
COCO challenge2018检测任务冠军方案。
传统faster RCNN的两个局限:1. 预先定义anchor尺寸,对性能影响很大, 不同任务都需做调整;2. 生成过多anchor,引入过多负样本,影响模型速率。
GA_RPN通过图像特征指导anchor生成,CNN预测anchor位置和形状,生成稀疏且形状任意的anchor,设计feature adaption模块来修正特征图使其与anchor精确匹配,FGA-RPN相比RPN减少90%的anchor,并提高90%的召回率。
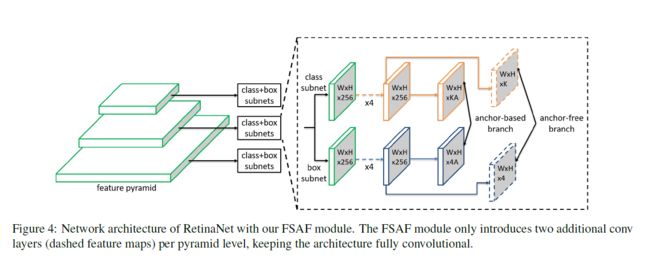
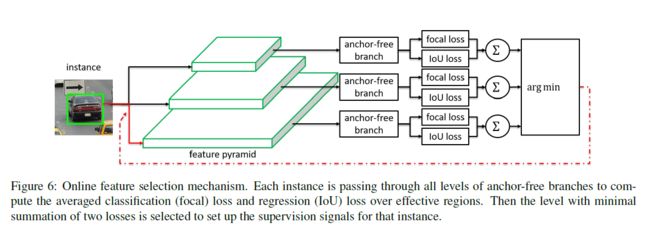
FSAF, 《Feature Selective Anchor-Free for Single-Shot Object Detection》,(CVPR2019,no code)【anchor自动选择feature, 释放anchor size作用】
提出的FSAF模块是为了解决特征图选择和重叠anchor选择,让每个anchor instance自动的选择合适的feature。提出anchor free概念,是说不再根据anchor size提取特征,而是根据FSAF模块自动选择合适的feature,即anchor size成为了一个无关的变量。 基于RetinaNet。
Loss方面的改进
AP-loss,《Towards Accurate One-Stage Object Detection with AP-Loss》 (CVPR2019, no code)【也是针对前景和背景类不平衡,引入设计AP作为损失函数】
一阶的目标检测器通常是通过同时优化分类损失函数和定位损失函数来训练。而由于存在大量的锚框,分类损失函数的效果会严重受限于前景-背景类的不平衡。本文通过提出一种新的训练框架来解决这个问题。我们使用排序任务替换一阶目标检测器中的分类任务,并使用排序问题的中的评价指标 AP 来作为损失函数。针对AP-loss是不可微且非凸的,提出新的方法-误差驱动更新机制,来优化该函数。实验使用RetinaNet网络。
G-IOU, 《Generalized Intersection over Union》(CVPR2019, code )【针对L1,L2和IOU直接作为损失函数的局限,设计使用 generalized IOU作为损失函数】
文章的motivation比较好,指出用L1、L2作为regression损失函数的缺点,以及用直接指标IoU作为损失函数的缺陷性,提出新的metric来代替L1、L2损失函数,从而提升regression效果,想法简单粗暴,但与IOU作为损失函数相比,yolo-v3上性能较好,在two-stage网络性能无提高。可能是two-stage经过第一步粗检测将很多与GT不重叠的框过滤了。
《Bounding Box Regression with Uncertainty for Accurate Object Detection》,(CVPR2019,旷世+CMU,coding)【根据目标检测标准的质量问题,学习Bounding Box分布,结合KL散度提出新的回归损失方法】
动机:使用传统的边界框回归方法会导致对应loss特别大。因为label定义得模糊,所以网络对这些目标边界的学习也很模糊,学习不稳定梯度/loss大。 [label标记的不好, 混合了其它object]
作者提出一个全新的 regression loss,通过学习bounding box的一个分布,结合kl散度,使得网络可以更好的学习拟合ground truth,让网络更好的学习和收敛(而不被模糊样例造成大的loss干扰)。另外,由于学习了bounding box的分布,这一环节可以嵌入nms阶段,使得定位目标更准确。
NMS -后处理上的优化
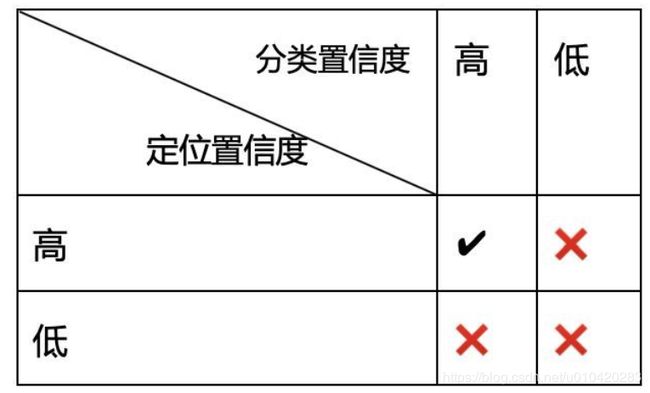
主要是解决:基于 CNN 的目标检测方法存在的分类置信度和定位置信度不匹配的问题。
NMS——soft_NMS——softer_NMS——IOU_guided NMS
NMS: 大于阈值的box直接remove
Soft_NMS: 大于阈值的box给其置信度降低分数
Softer-NMS:基于soft-NMS,对预测标注方差范围内的候选框加权平均,使得高定位置信度的bounding box具有较高的分类置信度
IoU_guided NMS(ECCV2018,IoU Net,旷世) :
问题引入:传统NMS算法缺失定位置信度信息:1. 在抑制重复检测时,使用分类分数作为给box排名的指标;2. 在缺少定位置信度情况下的边界框回归缺少可解释性或者可预测性。
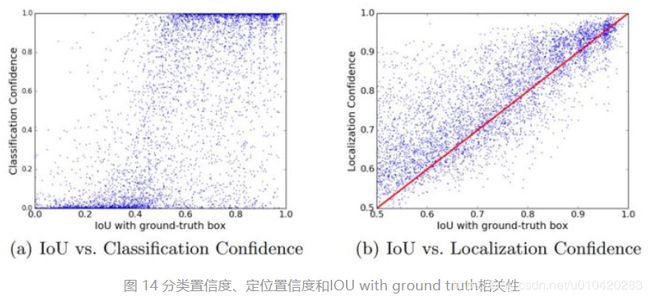
解决方案:1. 在NMS阶段引入定位得分(localization confidence)作为排序指标而不是采用传统的分类得分;2. 提出基于优化的bbox refinement替换传统的regression-based方法,提高了回归部分的可解释性。
其它方法
M2Det, 《M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid》,AAAI 2019,阿里巴巴,【针对多尺度问题,对特征金字塔结构的优化】
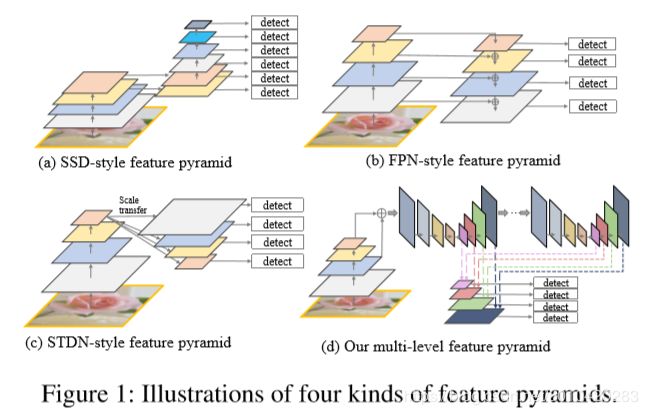
为了更好地解决目标检测中尺度变化带来的问题,论文总结了多种特征金字塔结构,提出多级特征金字塔网络MLFPN,结合SSD,提出一种新的Single-shot目标检测模型M2Det。
几种特征金字塔总结,和本文方法对比:
文章总体框架:

RDAD,《Object Detection based on Region Decomposition and Assembly》,(AAAI 2019),【更适配复杂真实场景,并结合了空间语义关系】
文章认为正是因为被遮挡了的或者不精确的 Region Proposals 导致目标检测算法的不准确。就是假如一辆车的左边被人遮挡了,那么这辆车的右边带来的信息其实才是更可信的。基于这个想法,文章提出 R-DAD即区域分解组装检测器,来改善生成的 Region Proposals。
个人总结
目标检测的研究自从卷积神经网络(CNN)流行之后,现在的方法几乎都是基于深度学习的CNN作为backbone网络,经历了two-stage和one-stage两个分支。吴恩达曾在其深度学习课程中说到,他认为one-stage将是最终的趋势,近年来很多论文也确实是围绕one-stage的方法提出的新思路。总而言之,准确,快速是其终极目标,而现在的主流方法中遍历全图提前设定anchor的学习机制,无疑是影响速度和效率的很大原因,所以今年CVPR的很多文章出现了anchor free的思想。如果说faster RCNN和yolo系列网络给目标检测领域提升的性能达到了一个瓶颈,另寻其它路径确实是再次取得突破的必然选择,小打小闹的优化帮助并不大。
我觉得结合上下文语义(场景理解)的目标检测可能会给我们带来一些惊喜。attention机制最先是在自然语言处理领域提出的概念,并且给其带来的效果显著,近年来也出现了一些基于attention机制的目标检测方法,然而自然语言处理的研究毕竟处于初期,也是一个艰巨的任务,短期内很难取得重大的突破。