监控端口数据官方案例
需求
首先,Flume监控本机55566端口,然后通过telnet工具向本机55566端口发送消息,最后Flume将监听的数据实时显示在控制台
分析
- 通过telnet工具向本机的55566端口发送数据
- Flume监控本机的55566端口,通过Flume的source端读取数据
- Flume将获取的数据通过Sink端写出到控制台
实现步骤
- 安装telnet
在/opt/module目录下创建flume-telnet文件夹
mkdir flume-telnet
将telnet-0.17-59.el7.x86_64.rpm和telnet-server-0.17-59.el7.x86_64.rpm拷入到/opt/module/flume-telnet文件夹下面
cp -r CentOS7.2\ telnet/* flume-telnet/
执行如下命令
rpm -ivh telnet-0.17-59.el7.x86_64.rpm
rpm -ivh telnet-server-0.17-59.el7.x86_64.rpm - 判断端口55566端口是否被占用
sudo netstat -tunlp | grep 55566
功能描述:netstat命令是一个监控TCP/IP网络的非常有用的工具,它可以显示路由表、实际的网络连接以及每一个网络接口设备的状态信息。
基本语法:netstat [选项]
选项参数:
-t或--tcp,显示TCP传输协议的连线状况;
-u或--udp,显示UDP传输协议的连线状况;
-n或--numeric,直接使用ip地址,而不通过域名服务器;
-l或--listening,显示监控中的服务器的Socket;
-p或--programs,显示正在使用Socket的程序识别码和程序名称; - 创建Flume Agent配置文件flume-telnet-logger.conf
在flume目录下创建job文件夹并进入job文件夹
cd /opt/module/flume
mkdir job
cd job
在job文件夹下创建Flume Agent配置文件flume-telnet-logger.conf
vim flume-telnet-logger.conf
在flume-telnet-logger.conf文件中添加如下内容
#表示将r1和c1连接起来
# Name the components on this agent #表示agent的名称
#r1表示a1的输入源
a1.sources = r1
#k1表示a1的输出目的地
a1.sinks = k1
#c1表示a1的缓冲区
a1.channels = c1
# Describe/configure the source
#表示a1的输入源类型为netcat端口类型
a1.sources.r1.type = netcat
#表示a1的监听的主机
a1.sources.r1.bind = localhost
#表示a1的监听的端口号
a1.sources.r1.port = 55566
# Describe the sink
#表示a1的输出目的地是控制台logger类型
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
#表示a1的channel类型是memory内存型
a1.channels.c1.type = memory
#表示a1的channel总容量是1000个event
a1.channels.c1.capacity = 1000
#表示a1的channel传输时收集到了100条event以后再去提交事务
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
#表示将r1和c1连接起来
a1.sources.r1.channels = c1
#表示将k1和c1连接起来
a1.sinks.k1.channel = c1
- 先开启flume监听端口
bin/flume-ng agent --conf conf/ --name a1 --conf-file job/flume-telnet-logger.conf -Dflume.root.logger=INFO,console
参数说明:
--conf conf/ :表示配置文件存储在conf/目录
--name a1 :表示给agent起名为a1
--conf-file job/flume-telnet.conf :flume本次启动读取的配置文件是在job文件夹下的flume-telnet.conf文件。
-Dflume.root.logger==INFO,console :-D表示flume运行时动态修改flume.root.logger参数属性值,并将控制台日志打印级别设置为INFO级别。日志级别包括:log、info、warn、error。 - 使用telnet工具向本机的55566端口发送内容
telnet localhost 55566
实时读取本地文件到HDFS案例
需求,实时监控Hive日志,并上传到HDFS中
- Flume要想将数据输出到HDFS,必须持有Hadoop相关jar包
将commons-configuration-1.6.jar、hadoop-auth-2.8.3.jar、hadoop-common-2.8.3.jar、hadoop-hdfs-2.8.3.jar、commons-io-2.4.jar、htrace-core4-4.0.1-incubating.jar拷贝到/opt/module/flume/lib文件夹下,后两个jar包是1.99版本必须引用的jar,其他版本可以不用
其中commons-configuration-1.6.jar,hadoop-auth-2.8.3.jar,commons-io-2.4.jar、htrace-core4-4.0.1-incubating.jar在/opt/module/hadoop-2.8.3/share/hadoop/common/lib可以找到,hadoop-common-2.8.3.jar在/opt/module/hadoop-2.8.3/share/hadoop/common可以找到、hadoop-hdfs-2.8.3.jar可以再/opt/module/hadoop-2.8.3/share/hadoop/hdfs找到 - 创建flume-file-hdfs.conf文件
vim flume-file-hdfs.conf - 输入以下内容
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /opt/module/hive/logs/hive.log
a2.sources.r2.shell = /bin/bash -c
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop-100:9000/flume/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k2.hdfs.batchSize = 1000
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 600
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k2.hdfs.rollCount = 0
#最小冗余数
a2.sinks.k2.hdfs.minBlockReplicas = 1
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
- 执行监控配置
bin/flume-ng agent --conf conf/ --name a2 --conf-file job/flume-file-hdfs.conf -
查看hdfs文件
 flume监控hive日志.png
flume监控hive日志.png
实时读取目录文件到HDFS案例
需求,使用flume监听整个目录的文件
- 创建配置文件flume-dir-hdfs.conf
vim flume-dir-hdfs.conf - 添加如下内容
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir = /opt/module/flume/upload
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
#忽略所有以.tmp结尾的文件,不上传
a3.sources.r3.ignorePattern = ([^ ]*\.tmp)
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://hadoop-100:9000/flume/upload/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 600
#设置每个文件的滚动大小大概是128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a3.sinks.k3.hdfs.rollCount = 0
#最小冗余数
a3.sinks.k3.hdfs.minBlockReplicas = 1
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
- 启动监控文件夹命令
bin/flume-ng agent --name a3 --conf conf/ --conf-file job/flume-dir-hdfs.conf - 创建文件夹并添加新文件
-
结果
 flume监控本地文件夹本地文件.png
flume监控本地文件夹本地文件.png
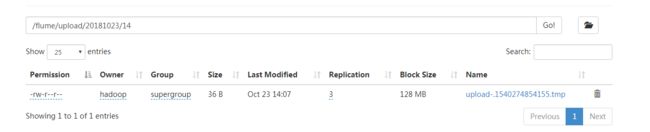 flume监控本地文件夹hdfs文件.png
flume监控本地文件夹hdfs文件.png
单数据源多出口案例一
需求,使用flume-1监控文件变动,flume-1将变动内容传递给flume-2,flume-2负责存储到HDFS。同时flume-1将变动内容传递给flume-3,flume-3负责输出到local filesystem
- 准备工作
在/opt/module/flume/job目录下创建group1文件夹
在/opt/module/datas/目录下创建flume3文件夹
了解一下Avro和RPC
Avro是由Hadoop创始人Doug Cutting创建的一种语言无关的数据序列化和RPC框架
RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议 - 创建创建flume-file-flume.conf
配置1个接收日志文件的source和两个channel、两个sink,分别输送给flume-flume-hdfs和flume-flume-dir
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# 将数据流复制给多个channel
a1.sources.r1.selector.type = replicating
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/hive/logs/hive.log
a1.sources.r1.shell = /bin/bash -c
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop-100
a1.sinks.k1.port = 14141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop-100
a1.sinks.k2.port = 14142
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
- 创建flume-flume-hdfs.conf
配置上级flume输出的source,输出是到hdfs的sink
# Describe/configure the source
a2.sources.r1.type = avro
a2.sources.r1.bind = hadoop-100
a2.sources.r1.port = 14141
# Describe the sink
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path = hdfs://hadoop-100:9000/flume2/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k1.hdfs.filePrefix = flume2-
#是否按照时间滚动文件夹
a2.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k1.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k1.hdfs.rollInterval = 600
#设置每个文件的滚动大小大概是128M
a2.sinks.k1.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k1.hdfs.rollCount = 0
#最小冗余数
a2.sinks.k1.hdfs.minBlockReplicas = 1
# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
- 创建flume-flume-dir.conf
配置上级flume输出的source,输出是到本地目录的sink
#name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c2
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop-100
a3.sources.r1.port = 14142
# Describe the sink
a3.sinks.k1.type = file_roll
a3.sinks.k1.sink.directory = /opt/module/datas/flume3
# Describe the channel
a3.channels.c2.type = memory
a3.channels.c2.capacity = 1000
a3.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c2
a3.sinks.k1.channel = c2
- 执行配置文件
bin/flume-ng agent --name a3 --conf conf/ --conf-file job/group1/flume-flume-dir.conf
bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group1/flume-flume-hdfs.conf
bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group1/flume-file-flume.conf -
检查HDFS和本地的文件
 案例1HDFS文件.png
案例1HDFS文件.png
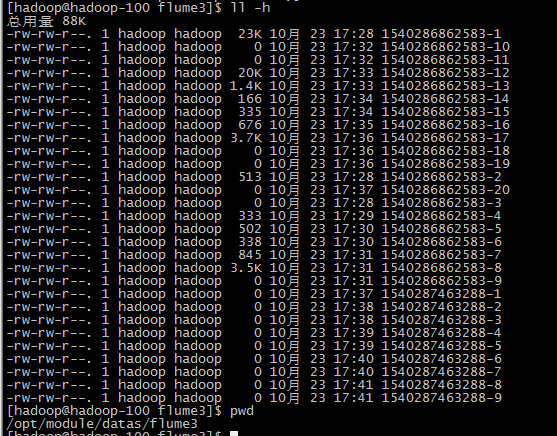 案例1本地文件.png
案例1本地文件.png
单数据源多出口案例二
需求,使用flume-1监控文件变动,flume-1将变动内容传递给flume-2,flume-2负责打印数据到控制台。同时flume-1将变动内容传递给flume-3,flume-3也负责打印数据到控制台,完成负载均衡功能
- 准备工作
在/opt/module/flume/job目录下创建group2文件夹 - 创建flume-netcat-flume.conf
# Name the components on this agent
a1.sources = r1
a1.channels = c1
a1.sinkgroups = g2
a1.sinks = k1 k2
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sinkgroups.g2.processor.type = load_balance
a1.sinkgroups.g2.processor.backoff = true
a1.sinkgroups.g2.processor.selector = round_robin
a1.sinkgroups.g2.processor.selector.maxTimeOut=10000
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop-100
a1.sinks.k1.port = 14141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop-100
a1.sinks.k2.port = 14142
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinkgroups.g2.sinks = k1 k2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
- 创建flume-flume1.conf
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
a2.sources.r1.type = avro
a2.sources.r1.bind = hadoop-100
a2.sources.r1.port = 14141
# Describe the sink
a2.sinks.k1.type = logger
# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
- 创建flume-flume2.conf
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c2
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop-100
a3.sources.r1.port = 14142
# Describe the sink
a3.sinks.k1.type = logger
# Describe the channel
a3.channels.c2.type = memory
a3.channels.c2.capacity = 1000
a3.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c2
a3.sinks.k1.channel = c2
- 启动
bin/flume-ng agent --name a2 --conf conf/ --conf-file job/group2/flume-flume1.conf -Dflume.root.logger=INFO,console
bin/flume-ng agent --name a3 --conf conf/ --conf-file job/group2/flume-flume2.conf -Dflume.root.logger=INFO,console
bin/flume-ng agent --name a1 --conf conf/ --conf-file job/group2/flume-telnet-flume.conf -
查看结果
 案例2telnet端.png
案例2telnet端.png
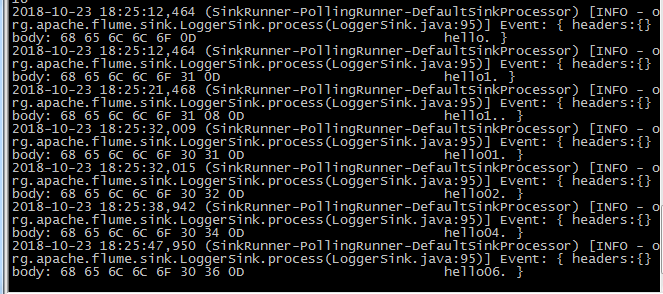 案例2flume1.png
案例2flume1.png
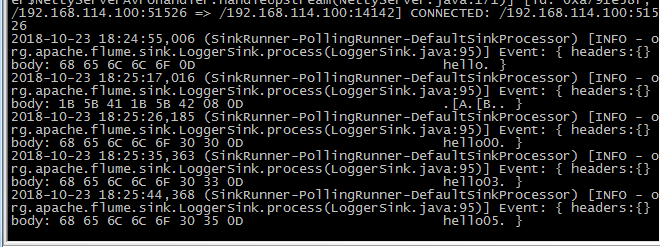 案例2flume2.png
案例2flume2.png
多数据源汇总案例
需求,hadoop-100上的flume-1监控文件hive.log,hadoop-101上的flume-2监控某一个端口的数据流,flume-1与flume-2将数据发送给hadoop-102上的flume-3,flume-3将最终数据上传到hdfs上
- 准备
分发flume,创建group3文件夹
xsync flume
在hadoop-100,hadoop-101,hadoop-102的/opt/module/flume/job/目录下创建group3文件夹
mkdir group3 - 在hadoop-100创建flume1.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/hive/logs/hive.log
a1.sources.r1.shell = /bin/bash -c
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop-102
a1.sinks.k1.port = 14141
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 在hadoop-101创建flume2.conf
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
a2.sources.r1.type = netcat
a2.sources.r1.bind = hadoop-101
a2.sources.r1.port = 44444
# Describe the sink
a2.sinks.k1.type = avro
a2.sinks.k1.hostname = hadoop-102
a2.sinks.k1.port = 14141
# Use a channel which buffers events in memory
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
- 在hadoop-102创建flume3.conf
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c1
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop-102
a3.sources.r1.port = 14141
# Describe the sink
a3.sinks.k1.type = hdfs
a3.sinks.k1.hdfs.path = hdfs://hadoop-100:9000/flume3/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k1.hdfs.filePrefix = flume3-
#是否按照时间滚动文件夹
a3.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a3.sinks.k1.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k1.hdfs.rollInterval = 600
#设置每个文件的滚动大小大概是128M
a3.sinks.k1.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a3.sinks.k1.hdfs.rollCount = 0
#最小冗余数
a3.sinks.k1.hdfs.minBlockReplicas = 1
# Describe the channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1
- 启动
在hadoop-100上执行
bin/flume-ng agent --name a1 --conf conf/ --conf-file job/group3/flume1.conf
在hadoop-101上执行
bin/flume-ng agent --name a2 --conf conf/ --conf-file job/group3/flume2.conf
在hadoop-102上执行
bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group3/flume3.conf -
查看结果
 聚合例子.png
聚合例子.png