【论文翻译】Out of time: automated lip sync in the wild
pdf: https://ora.ox.ac.uk/objects/uuid:6bdd4768-6fbd-40ac-8efc-edca8a0325b3/download_file?file_format=pdf&safe_filename=Chung%2Band%2BZisserman%252C%2BOut%2Bof%2Btime%2B-%2Bautomated%2Blip%2Bsync%2Bin%2Bthe%2Bwild.pdf&type_of_work=Conference+item
github: https://github.com/joonson/syncnet_python
1.介绍
1.1.相关工作
2. 表征和架构
2.1音频流

图1.输入表示。左:时间表示为音频热图。音频图像中的13行(A到M)分别对代表不同频率箱内功率的13个MFCC特征进行编码。右图:嘴巴区域的灰度图像。
表征
音频被编码为表示每个时间步长和每个mel频带的MFCC值的热图图像(参见图1)。图像的顶部和底部三行被反射以减少边界效果。以前的工作[9]也曾尝试训练类似输入的图像样式的ConvNet。
架构
我们使用的卷积神经网络灵感来自那些设计的图像识别..我们的层体系结构(图2)是基于VGGM[5],但有修改的过滤器大小,以吸收输入的不寻常的维度。VGG-M采用的是尺寸为224×224像素的正方形图像,而我们的输入尺寸为20像素(时间步长),而另一方向只有13像素(因此,输入图像为13×20像素)。
2.2 视频流
表征
视觉网络的输入格式是口区域作为灰度图像的序列,如图1所示。输入维度为111×111×5 (W×H×T)为5帧,相当于0.2秒25 hz的帧速率。
架构
我们的体系结构基于[7],它是为视觉语音识别的任务而设计的。特别是,该体系结构基于早期的融合模型,该模型紧凑且训练速度快。已经修改了conv1过滤器以摄取5通道输入。

图2.双流ConvNet架构。两条溪流同时训练。
2.3 损失函数
训练目标是音频和视频网络的输出与真对相似,与假对不同。具体地说,网络输出之间的欧氏距离被最小化或最大化。我们建议使用最初提出的用于训练Siamese网络[6]的对比损耗(公式1)。v和a分别是视频流和音频流的fc7向量。y∈[0,1]是音频和视频输入之间的二进制相似度度量。

![]()
另一种方法是将这个问题作为一个类化(同步/不同步,或使用合成数据进入不同的偏移箱)来处理,但是我们无法使用这种方法来实现收敛。
2.4 训练
该训练程序是对单流卷积神经网络常用程序的改编[14,24],并受到[6,23]的启发。然而,我们的网络是不同的,因为它由不同的流组成,两组独立参数以及来自两个不同领域的输入。利用带动量的随机梯度下降法学习网络权值。两个网络流的参数是同时学习的。
数据增强
在卷积神经网络的图像分类任务[14]中,应用数据增强通常可以提高验证性能并减少过拟合。对于音频,音量在±10%的范围内随机改变。我们不会改变音频播放速度,因为这可能会影响重要的计时信息。对于错误的例子,我们采取随机的作物在时间。对于视频,我们采用了ImageNet分类任务中使用的标准增强方法[14,24](例如随机剪切、翻转、颜色移动)。单个转换应用于单个剪辑中的所有视频帧。
细节
我们的实现是基于MATLAB工具箱MatConvNet[26],在NVIDIA Titan X GPU上训练12GB内存。网络使用批处理规范化[10]进行训练,10-2到10-4的学习速率,这比通常用于训练具有批处理规范化的ConvNet的速度要慢。训练在20个epoch后停止,或者当验证错误在3个epoch内没有改善时,以较早者为准。
3 数据集
图3.BBC News视频的静止图片
在本节中,我们描述了自动生成用于训练唇同步系统的大型视听数据集的管道。使用上述方法,我们从BBC视频中收集了数百小时的演讲,覆盖了数百名演讲者。我们从2013年到2016年的BBC新闻节目开始(图3),因为新闻中出现了大量不同的人,而不是固定的演员阵容。训练集、验证集和测试集按时间进行划分,各集对应的视频日期如表1所示。
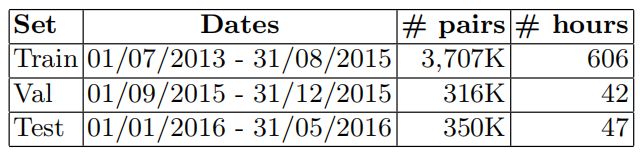
表1。数据集统计:记录日期,真实(阳性)和假唇同步音频视频训练样本的数量,facetrack的小时数。
处理管道如图4所示。管道的可视化部分基于Chung和Zisserman[7]使用的方法,我们在这里给出了该方法的简要概述。首先,通过比较颜色直方图在连续帧[16]来确定镜头边界。然后在每帧上执行基于hogb的人脸检测方法,并使用KLT tracker[25]将人脸检测分组到帧上。我们将丢弃视频中出现多个面孔的任何剪辑,因为在此场景中不知道说话者。
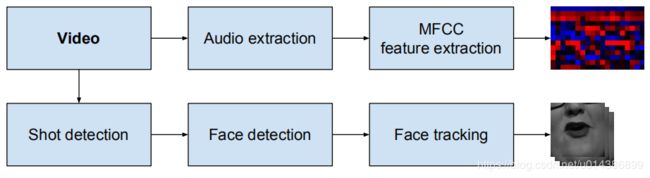
图4.管道生成视听数据集。
pipeline的音频部分非常简单。在语音识别系统中,音频通常采用Mel-frequency cepstral coefficient (MFCC)[8]特征来描述。对音频不执行其他预处理。
3.1汇编培训数据
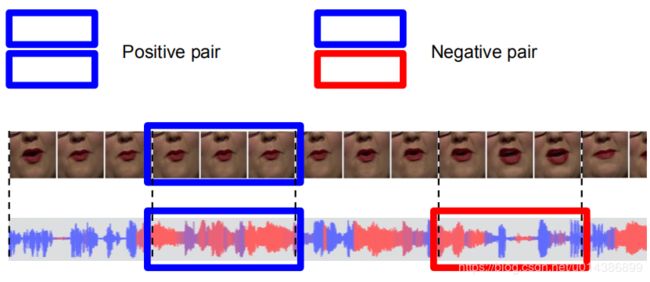
图5.获取真、假音视频对的过程。
真正的音视频对是由一个5帧的视频剪辑和相应的音频剪辑生成的。只有音频被随机移动2秒,以生成合成的假音视频对。如图5所示。我们从相同的剪辑中提取音频,这样网络就能识别排列,而不是扬声器。
细化训练数据
使用该方法生成的训练数据是有噪声的,因为它包含声音和嘴巴形状不相关的视频(例如配音视频)或不同步的视频。
网络最初针对这些有噪声的数据进行训练,训练后的网络通过拒绝超过阈值的正对来丢弃训练集中的误报。然后根据这些新数据对网络进行重新训练。
讨论
该方法不需要对训练数据进行注释,与以前的一些基于音素识别的工作不同。我们使用音视频对进行训练,这种方法的优点是,可用数据的数量几乎是无限的,而获取数据的成本是最低的(几乎所有从互联网上下载的语音视频都可以用于训练)。关键的假设是,我们下载的大多数视频都是近似同步的,尽管有些视频可能存在口型同步错误。卷积神经网络损失函数和训练通常能容忍数据的噪声。
4.实验
在本节中,我们使用经过训练的网络来确定视频中的假同步错误。每个流的256维fc7向量被用作表示音频和视频的特征。为了得到信号之间的相似度度量,需要特征的欧氏距离。这是训练时使用的距离函数。直方图(图6)显示了度量的分布。
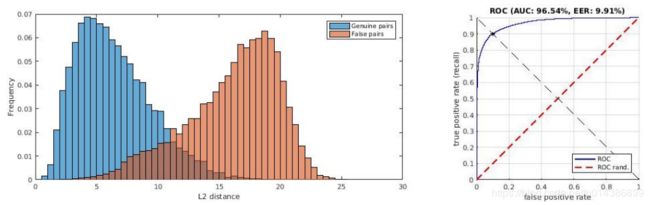
图6.欧几里德距离的分布为真和假音视频对,使用单一的0.2秒样本。注意,这是在嘈杂的验证数据上,其中可能包括非扬声器或配音视频的剪辑。
4.1确定嘴唇同步错误
为了找到音频和视频之间的时间偏移,我们采取了滑动窗口的方法。对于每个样本,在±1秒范围内计算一个5帧视频特征和所有音频特征之间的距离。正确的偏移量是当这个距离最小时。然而,如表2所示,并不是剪辑中的所有样本都是有区别的(例如,在某个特定时间可能有一些样本什么都没有说),因此对每个剪辑取多个样本,然后取平均值。典型的响应图如图8所示。
评估
音频和视频之间的精确时间偏移是未知的。因此,评估是手工完成的,如果同步是成功的,那么对口型的错误就不会被人发现。我们从保留用于测试的数据集中随机抽取几百个片段,如第3节所述。成功率见表2。

表2在人类可探测范围内的准确性。
研究人员还对韩国和日本的视频样本进行了实验(图7),以显示我们的方法可以跨不同的语言工作。定性的结果是非常好的,将从我们的研究页面。
 性能
性能
数据准备管道和网络的运行速度比中档笔记本电脑(苹果MacBook Pro)的实时运行速度要快得多
NVIDIA GeForce GT 750M图形),除了人脸检测步骤(外部应用),运行速度约×0.3实时性。
4.2应用:主动扬声器检测
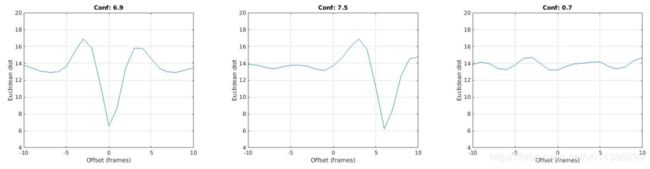
图8.对于不同的偏移值,音频和视频功能之间的平均距离,在一个剪辑上平均。实际偏移位于低谷..这里显示的三个例子片段是为了区别你的场景。左:同步AV数据;中:音频引导视频;右:音频和视频不相关。
AV同步问题和主动扬声器检测问题密切相关,因为视频和伴随音频之间的对应关系必须建立。因此,同步方法可以扩展到确定说话人在一个场景中有多个面孔。我们将时间偏移(同步误差)的置信分数定义为欧几里得距离的最小值和中值之间的差值(例如,图8中两个图中的值都在6到7之间)。在一个多主题场景中,说话者的面部自然是音频和视频之间最对应的部分。一个不会说话的人的相关性应该接近于零,因此得分也应该很低。
与单模态的主动说话人检测方法不同,我们的方法只依赖于嘴唇的运动,我们的方法也可以检测说话人的情况,但与音频不相关(例如在配音视频中)。
评估
我们使用数据集(图9)和Chakravarty等人的评估协议对我们的方法进行了测试。目的是在多主题场景中确定说话者是谁。
 图9.Columbia数据集的静止图像[4]。
图9.Columbia数据集的静止图像[4]。
数据集包含6个扬声器,其中5个(Bell、Bollinger、Lieberman、Long、Sick)用于测试。在ROC曲线与对角线相交的点上,使用剩余发言者(Abbas)的注释设置评分阈值(错误率相等)。
我们在表3中报告了f1的分数。每个测试样本的分数在10帧或100帧窗口内取平均值。对于100帧窗口,性能几乎是完美的。增加平均窗口大小的缺点是,该方法不能检测到说话人在很短时间内说话的例子;虽然在这种情况下这不是问题。

表3 在Columbia speaker检测数据集上的f1得分。[4]的结果已经从他们论文的图3b中进行了数字化处理,其准确度在±0.5%左右
4.3应用:唇部阅读
针对任何任务训练深度网络都需要大量数据,但对于唇读等问题,大规模带注释的数据的收集成本可能高得令人望而却步。然而,没有标签的口语视频是丰富的,容易获得。
同步网络的一个有用的副产品是,它使人们能够在不使用任何标记数据的情况下学习非常强的嘴巴描述符。我们使用这个结果在OuluVS2[2]数据集上达到了新的最先进的技术。这包括52名受试者说出相同的10个短语(如“谢谢”、“你好”等)或10个预先确定的数字序列。它是在一个与说话者无关的实验中评估的,在这个实验中,12个指定的对象被保留下来进行测试。只有视频流用于训练和测试,即这是一个“唇读”实验,而不是视听语音识别。
实验装置
本实验采用一种单层250个隐藏单元的简单单向LSTM分类器。设置如图10所示。LSTM网络摄取的视觉功能(fc7激活从
(ConvNet)中的5帧滑动窗口,每次移动1帧,并在序列结束时返回分类结果。
训练细节
我们对递归网络的实现是基于Caffe[11]工具箱的。该网络采用Stocastic梯度下降训练,学习率为10-3。梯度是反向传播的整个长度的剪辑。使用Softmax log loss,这里,对于10个短语或数字序列,n = 10。损失只在最后一步计算。
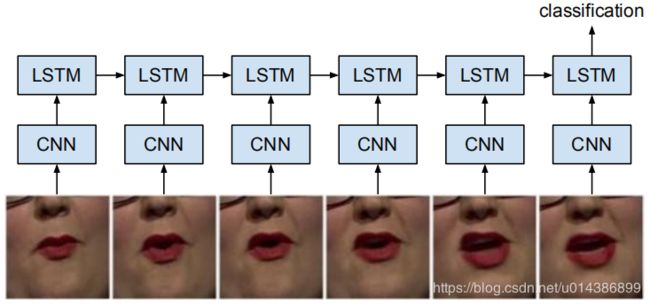
图10.网络配置为唇读实验..在LSTM训练时,ConvNet权重没有更新。
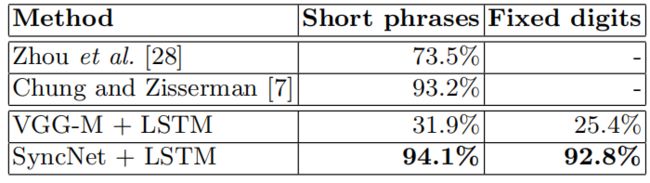
表4在OuluVS2上测试集合分类精度,正面视图。
评估
我们将我们的结果与这个数据集上的最新技术进行比较;还有同样的LSTM设置,但是用的是在ImageNet[21]上预先训练的VGG-M[5]卷积网络。我们在表4中报告了结果。特别值得注意的是,我们的结果优于[7],它是使用预先在非常大的标记数据集上训练的网络获得的。
5.结论
我们已经证明,一个双流卷积神经网络可以被训练来同步音频和嘴部动作,从很容易获得的自然语音视频。这种方法的一个有用的应用是在媒体播放器中,可以在运行时在本地机器上纠正唇同步错误。此外,该方法可以扩展到任何需要学习不同领域中相关数据之间的相似度度量的问题。我们还证明了训练后的网络对于视频中的说话人检测和唇读等任务是有效的。