Flume+Kafka+Spark Streaming+MySQL实时数据处理
文章目录
- 项目背景
- 案例需求
- 一、分析
- 1、日志分析
- 二、日志采集
- 第一步、代码编辑
- 2、启动采集代码
- 三、编写Spark Streaming的代码
- 第一步 创建工程
- 第二步 选择创建Scala工程
- 第三步 设置工程名与工程所在路径和使用的Scala版本后完成创建
- 第四步 创建scala文件
- 第五步:导入依赖包
- 第六步:引入本程序所需要的全部方法
- 第七步:创建main函数与Spark程序入口。
- 第八步:设置kafka服务的主机地址和端口号,并设置从哪个topic接收数据和设置消费者组
- 第九步:数分析
- 第十步:保存计算结果
- 第十一步 数据库设计
- jumpertab表
- pvtab表
- regusetab表
- 四、编译运行
- 第一步、将工程添加到jar文件并设置文件名称
- 第二步、生成jar包
- 第三步、提交运行Spark Streaming程序
- 第四步:查看数据库
- 完整代码如下
本案例源码下载
链接:https://pan.baidu.com/s/1IzOvSCtLvZzj81XZaYl6CQ
提取码:i6i8
项目背景
网络发展迅速的时代,越来越多人通过网络获取跟多的信息或通过网络作一番自己的事业,当投身于搭建属于自己的网站、APP或小程序时会发现,经过一段时间经营和维护发现浏览量和用户数量的增长速度始终没有提升。在对其进行设计改造时无从下手,当在不了解用户的浏览喜欢和个用户群体的喜好。虽然服务器日志中明确的记载了用户访浏览的喜好但是通过普通方式很难从大量的日志中及时有效的筛选出优质信息。Spark Streaming是一个实时的流计算框架,该技术可以对数据进行实时快速的分析,通过与Flume、Kafka的结合能够做到近乎零延迟的数据统计分析。
案例需求
要求:实时分析服务器日志数据,并实时计算出某时间段内的浏览量等信息。
使用技术:Flume-》Kafka-》SparkStreaming-》MySql数据库
#案例架构
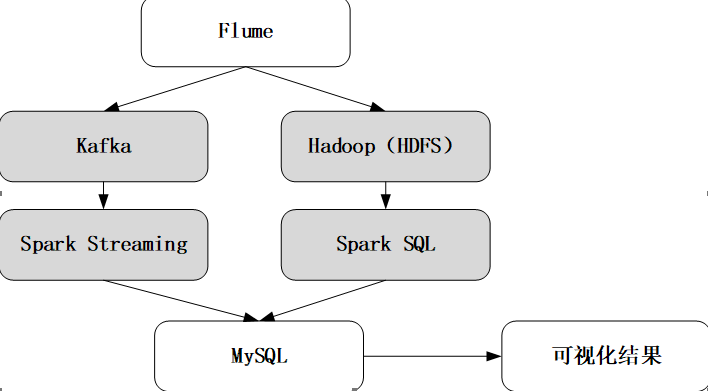
架构中通过Flume实时监控日志文件,当日志文件中出现新数据时将该条数据发送给Kafka,并有Spark Streaming接收进行实时的数据分析最后将分析结果保存到MySQL数据库中。
一、分析
1、日志分析
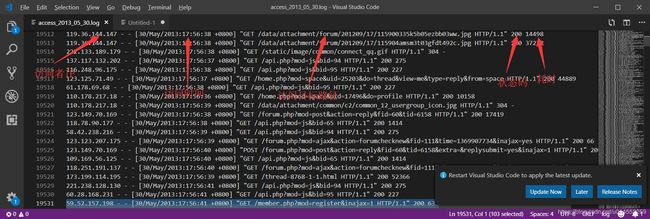
1.通过浏览器访问服务器中的网页,每访问一次就会产生一条日志信息。日志中包含访问者IP、访问时间、访问地址、状态码和耗时等信息,如下图所示:
二、日志采集
第一步、代码编辑
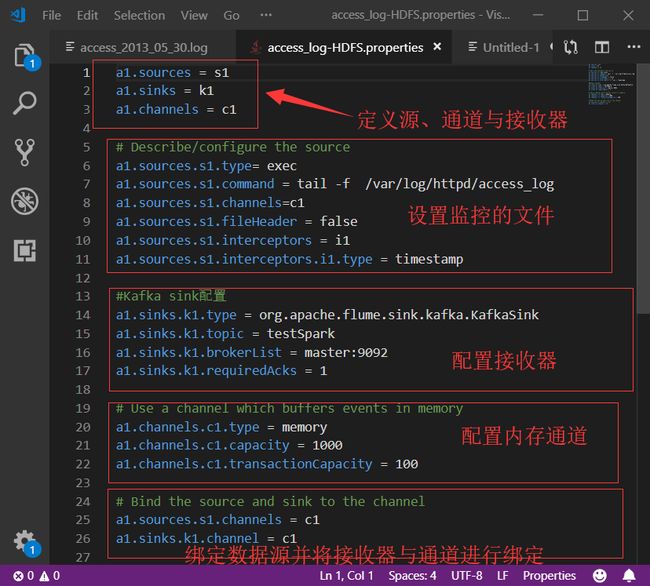
通过使用Flume实时监控服务器日志文件内容,每生成一条都会进行采集,并将采集的结构发送给Kafka,Flume代码如下。
2、启动采集代码
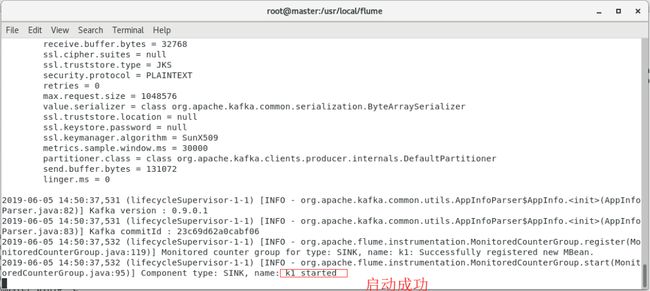
代码编辑完成后启动Flume对服务器日志信息进行监控,进入Flume安装目录执行如下代码。
[root@master flume]# bin/flume-ng agent --name a1 --conf conf --conf-file conf/access_log-HDFS.properties -Dflume.root.logger=INFO,console
效果下图所示。
三、编写Spark Streaming的代码
第一步 创建工程

第二步 选择创建Scala工程
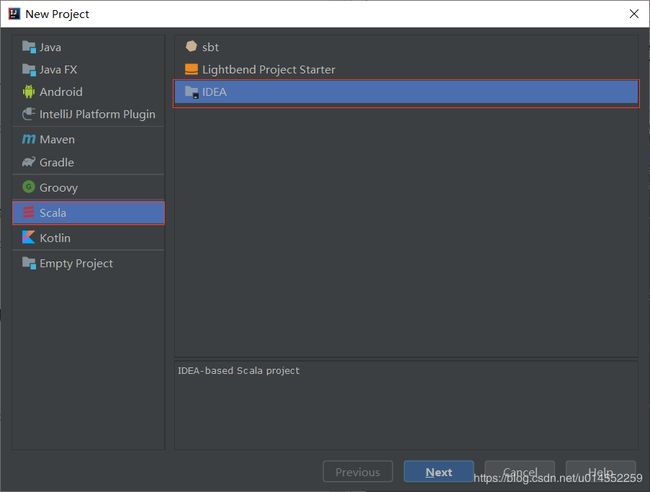
第三步 设置工程名与工程所在路径和使用的Scala版本后完成创建
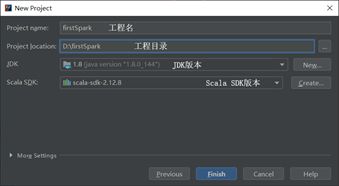
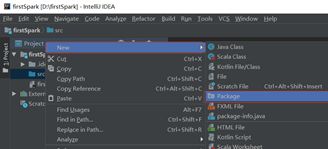
第四步 创建scala文件
项目目录的”src”处单机鼠标右键依次选择”New”->”Package”创建一个包名为”com.wordcountdemo”,并在该包处单机右键依次选择”New”->”scala class”创建文件命名为wordcount
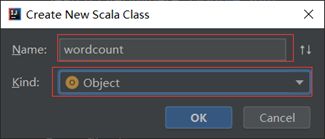
第五步:导入依赖包
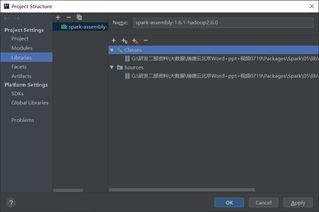
在IDEA中导入Spark依赖包,在菜单中依次选择”File”->”Project Structure”->”Libraries”后单击”+”号按钮选择”Java”选项,在弹出的对话框中找到spark-assembly-1.6.1-hadoop2.6.0.jar依赖包点击”OK”将所有依赖包加载到工程中,结果如图X所示。
第六步:引入本程序所需要的全部方法
注意此处使用了三个spark2中没有的jar包分别为kafka_2.11-0.8.2.1.jar、
metrics-core-2.2.0.jar、spark-streaming-kafka_2.11-1.6.3.jar。
import java.sql.DriverManager //连接数据库
import kafka.serializer.StringDecoder //序列化数据
import org.apache.spark.streaming.dstream.DStream //接收输入数据流
import org.apache.spark.streaming.kafka.KafkaUtils //连接Kafka
import org.apache.spark.streaming.{Seconds, StreamingContext} //实时流处理
import org.apache.spark.SparkConf //spark程序的入口函数
结果如图所示。

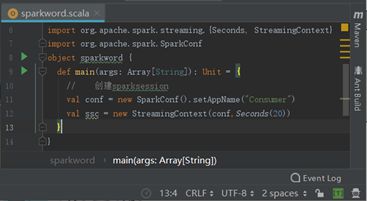
第七步:创建main函数与Spark程序入口。
def main(args: Array[String]): Unit = {
//创建sparksession
val conf = new SparkConf().setAppName("Consumer")
val ssc = new StreamingContext(conf,Seconds(20)) //设置每隔20秒接收并计算一次
}
结果如图所示。
第八步:设置kafka服务的主机地址和端口号,并设置从哪个topic接收数据和设置消费者组
//kafka服务器地址
val kafkaParam = Map("metadata.broker.list" -> "192.168.10.10:9092")
//设置topic
val topic = "testSpark".split(",").toSet
//接收kafka数据
val logDStream: DStream[String] = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParam,topic).map(_._2)
第九步:数分析
接收到数据后,对数据进行分析,将服务器日志数据按照空格进行拆分,并分别统计出阶段时间内的网站浏览量、用户注册数量和用户的跳出率并将统计结果转换为键值对类型的RDD。
//拆分接收到的数据
val RDDIP =logDStream.transform(rdd=>rdd.map(x=>x.split(" ")))
//进行数据分析
val pv = RDDIP.map(x=>x(0)).count().map(x=>("pv",x)) //用户浏览量
val jumper = RDDIP.map(x=>x(0)).map((_,1)).reduceByKey(_+_).filter(x=>x._2 == 1).map(x=>x._1).count.map(x=>("jumper",x)) //跳出率
val reguser =RDDIP.filter(_(8).replaceAll("\"","").toString == "/member.php?mod=register&inajax=1").count.map(x=>("reguser",x)) //注册用户数量
第十步:保存计算结果
遍历统计结果RDD取出键值对中的值并分别分别将分析结果保存到pvtab、jumpertab和regusetab表中,最后启动Spark Streaming程序。
pv.foreachRDD(line =>line.foreachPartition(rdd=>{
rdd.foreach(word=>{
val conn = DriverManager.getConnection("jdbc:mysql://master:3306/test", "root", "123456")
val format = new java.text.SimpleDateFormat("yyyy-MM-dd H:mm:ss")
val dateFf= format.format(new java.util.Date())
val sql = "insert into pvtab(time,pv) values("+"'"+dateFf+"'," +"'"+word._2+"')"
conn.prepareStatement(sql).executeUpdate()
})
}))
jumper.foreachRDD(line =>line.foreachPartition(rdd=>{
rdd.foreach(word=>{
val conn = DriverManager.getConnection("jdbc:mysql://master:3306/test", "root", "123456")
val format = new java.text.SimpleDateFormat("yyyy-MM-dd H:mm:ss")
val dateFf= format.format(new java.util.Date())
val sql = "insert into jumpertab(time,jumper) values("+"'"+dateFf+"'," +"'"+word._2+"')"
conn.prepareStatement(sql).executeUpdate()
})
}))
reguser.foreachRDD(line =>line.foreachPartition(rdd=>{
rdd.foreach(word=>{
val conn = DriverManager.getConnection("jdbc:mysql://master:3306/test", "root", "123456")
val format = new java.text.SimpleDateFormat("yyyy-MM-dd H:mm:ss")
val dateFf= format.format(new java.util.Date())
val sql = "insert into regusetab(time,reguse) values("+"'"+dateFf+"'," +"'"+word._2+"')"
conn.prepareStatement(sql).executeUpdate()
})
}))
ssc.start() //启动Spark Streaming程序
结果如图所示。
第十一步 数据库设计
创建一个数据库名为“test”,并在该库中创建三个表分别名为"jumpertab"、“pvtab”、“regusetab”,数据库结构如下图所示
jumpertab表
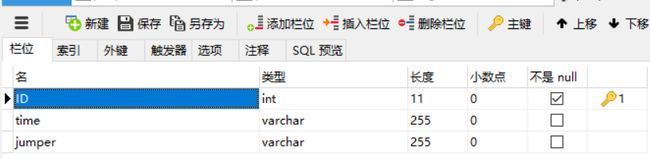
pvtab表

regusetab表

四、编译运行
将程序编辑为jar包提交到集群中运行。
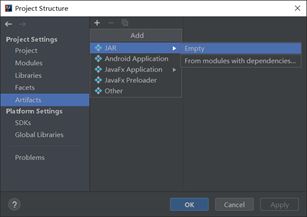
第一步、将工程添加到jar文件并设置文件名称
选择“File”-“Project Structure”命令,在弹出的对话框中选择“Artifacts”按钮,选择“+”下的“JAR”->“Empty”在随后弹出的对话框中“NAME”处设置JAR文件的名字为“WordCount”,并双击右侧“firstSpark”下的“’firstSpark’compile output”将其加载到左侧,表示已经将工程添加到JAR包中然后点击“OK”按钮,如下图所示。

第二步、生成jar包
点击菜单栏中的“Build”->“Build Artifacts…”按钮在弹出的对话框中单击“Build”按钮,jar包生成后工程根目录会自动创建一个out目录在目录中可以看到生成的jar包,结果如下图所示。

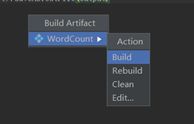
第三步、提交运行Spark Streaming程序
[root@master bin]# ./spark-submit --master local[*] --class com.spark.streaming.sparkword /usr/local/Streaminglog.jar
结果如下图所示

第四步:查看数据库

完整代码如下
package spark
import java.sql.DriverManager
import java.util.Calendar
import kafka.serializer.StringDecoder
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.SparkConf
object kafkaspark {
def main(args: Array[String]): Unit = {
// 创建sparksession
val conf = new SparkConf().setAppName("Consumer")
val ssc = new StreamingContext(conf,Seconds(1))
val kafkaParam = Map("metadata.broker.list" -> "192.168.10.10:9092")
val topic = "testSpark".split(",").toSet
//接收kafka数据
val logDStream: DStream[String] = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParam,topic).map(_._2)
//拆分接收到的数据
val RDDIP =logDStream.transform(rdd=>rdd.map(x=>x.split(" ")))
//进行数据分析
val pv = RDDIP.map(x=>x(0)).count().map(x=>("pv",x))
val jumper = RDDIP.map(x=>x(0)).map((_,1)).reduceByKey(_+_).filter(x=>x._2 == 1).map(x=>x._1).count.map(x=>("jumper",x))
val reguser =RDDIP.filter(_(8).replaceAll("\"","").toString == "/member.php?mod=register&inajax=1").count.map(x=>("reguser",x))
//将分析结果保存到MySQL数据库
pv.foreachRDD(line =>line.foreachPartition(rdd=>{
rdd.foreach(word=>{
val conn = DriverManager.getConnection("jdbc:mysql://master:3306/test", "root", "123456")
val format = new java.text.SimpleDateFormat("H:mm:ss")
val dateFf= format.format(new java.util.Date())
var cal:Calendar=Calendar.getInstance()
cal.add(Calendar.SECOND,-1)
var Beforeasecond=format.format(cal.getTime())
val date = Beforeasecond.toString+"-"+dateFf.toString
val sql = "insert into pvtab(time,pv) values("+"'"+date+"'," +"'"+word._2+"')"
conn.prepareStatement(sql).executeUpdate()
})
}))
jumper.foreachRDD(line =>line.foreachPartition(rdd=>{
rdd.foreach(word=>{
val conn = DriverManager.getConnection("jdbc:mysql://master:3306/test", "root", "123456")
val format = new java.text.SimpleDateFormat("H:mm:ss")
val dateFf= format.format(new java.util.Date())
var cal:Calendar=Calendar.getInstance()
cal.add(Calendar.SECOND,-1)
var Beforeasecond=format.format(cal.getTime())
val date = Beforeasecond.toString+"-"+dateFf.toString
val sql = "insert into jumpertab(time,jumper) values("+"'"+date+"'," +"'"+word._2+"')"
conn.prepareStatement(sql).executeUpdate()
})
}))
reguser.foreachRDD(line =>line.foreachPartition(rdd=>{
rdd.foreach(word=>{
val conn = DriverManager.getConnection("jdbc:mysql://master:3306/test", "root", "123456")
val format = new java.text.SimpleDateFormat("H:mm:ss")
val dateFf= format.format(new java.util.Date())
var cal:Calendar=Calendar.getInstance()
cal.add(Calendar.SECOND,-1)
var Beforeasecond=format.format(cal.getTime())
val date = Beforeasecond.toString+"-"+dateFf.toString
val sql = "insert into regusetab(time,reguse) values("+"'"+date+"'," +"'"+word._2+"')"
conn.prepareStatement(sql).executeUpdate()
})
}))
val num = logDStream.map(x=>(x,1)).reduceByKey(_+_)
num.print()
//启动Streaming
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}