VINS理论与代码详解5——基于滑动窗口的单目视觉紧耦合后端优化模型
VINS理论与代码详解5——基于滑动窗口的单目视觉紧耦合后端优化模型
终于讲到了真正的视觉惯性紧耦合系统了,(在这里插一句,算是写博客和学习一个SLAM系统的心得吧,一开始我们可能抱着一个必胜的心态打算征服所有的知识点和难点,但到了整个过程的中期,总会出现或多或少的问题,阻碍着我们前进的步伐,你可能想放松警惕,不想太深究具体的公式和内容,急功心切的想看到终点到底是什么,但是我要提醒大家,也包括自己,最美好的以及最有价值的永远是过程,是在过程中学到的可以为一生所用的经验,只是一味着冲到终点,而忘记了过程,你最终会发现得到的只有失望。如果你不想失望的话,那就再接再厉,给自己继续加油吧!)到这里才是整个系统的重点,前面所有提及的其实都是松耦合方式,目的是给整个系统提供优化初值和状态。视觉惯性紧耦合优化模型在第VI部分,我理解的紧耦合系统是将视觉和惯性的原始观测量进行有效的组合,也就是在数据处理前就进行数据融合,VINS中是将滑动窗口内的状态量整合到一个状态向量中,如公式21所示:
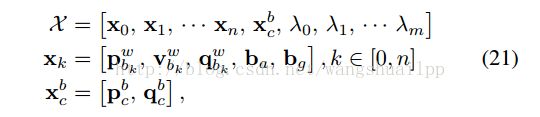
第一个式子是滑动窗口内整个状态向量,其中n是帧数,m是滑动窗口中的特征点总数,维度是15*n+6+m,第二个式子xk是在第k帧图像捕获到的IMU状态,包括位姿,速度,旋转,加速度计和陀螺仪偏置,第三个式子是相机外参,λ是特征点深度值得逆。从状态向量就可以看出xk只与IMU项以及Marginalization有关,特征点的深度值只与camera和Marginalization有关,所以下面建立BA紧耦合模型的时候按照这个思路,下面建立一个视觉惯性的BA优化模型以及鲁棒核函数模型:

从公式中可以明显的看出来,BA优化模型被分成了三个部分,分别是Marginalization(边缘化)残差部分(从滑动窗口中去掉的位姿和特征点的约束),IMU残差部分(滑动窗口中相邻帧间的IMU产生)和视觉代价误差函数部分(滑动窗口中特征点在相机下的投影产生),其中鲁棒核函数针对代价函数设定。下面具体介绍着三个部分。
(1) IMU观测值残差
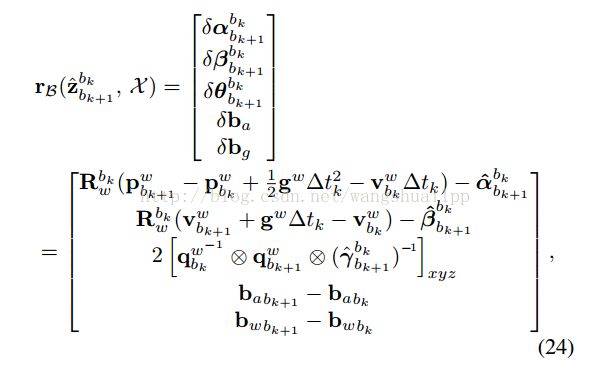
考虑到的是两个连续帧bk和bk+1之间的观测值,与前面的预积分模型相同,如公式24所示,还记得在IMU预积分的时候求得到协方差矩阵和观测值吗?那里求得的观测值就是测量值,协方差矩阵就是这里的协方差矩阵,而公式24前面的项就是预测的值,也称估计值,估计值和测量值之间的差值就是残差,其实这里的公式24是由公式5的右边左移得到,你发现了吗?
(2) 视觉观测值残差
与传统的针孔相机模型定义的重投影误差不同,论文中使用的是单位半球体的相机观测残差,是一个宽视野鱼眼或者全方位相机。相机的残差模型如下公式25所示:
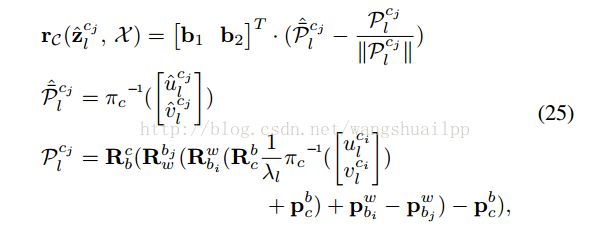
第一个式子就是残差的表达式,第二个式子是鱼眼相机反投影函数将观测到的像素坐标转换成单位向量的观测值数据,b1和b2是此单位向量的切平面上的一组基。第三个式子是重投影估计模型。
(3) Marginalization
这一部分借鉴博客:http://blog.csdn.net/q597967420/article/details/76099443
sliding windowsbounding边界化了优化问题中pose的个数, 从而防止pose和特征的个数随时间不断增加, 使得优化问题始终在一个有限的复杂度内, 不会随时间不断增长。然而, 将pose移出windows时, 有些约束会被丢弃掉, 这样势必会导致求解的精度下降, 而且当MAV进行一些退化运动(如: 匀速运动)时, 没有历史信息做约束的话是无法求解的. 所以, 在移出位姿或特征的时候, 需要将相关联的约束转变成一个约束项作为prior放到优化问题中. 这就是marginalization要做的事情。
VINS-MONO中,为了处理一些悬停的case,引入了一个two-way marginalization, 简单来说就是:如果倒数第二帧是关键帧, 则将最旧的pose移出slidingwindow, 也就是MARGIN_OLD,如果倒数第二帧不是关键帧, 则将倒数第二帧pose移出sliding window, 也就是MARGIN_NEW。选取关键帧的策略是视差足够大,在悬停等运动较小的情况下, 会频繁的MARGIN_NEW, 这样也就保留了那些比较旧但是视差比较大的pose. 这种情况如果一直MARGIN_OLD的话, 视觉约束不够强, 状态估计会受IMU积分误差影响, 具有较大的累积误差。
到这里整体VINS理论的框架基本上算是介绍完毕了,对于后面的重定位,全局位姿优化和回环检测等有时间再做下讨论,现在有没有一个比较清晰的思路?如果还比较困惑的话,那就赶紧进行下面的代码实战环节吧。下面就从代码角度来分析VINS的整个第二部分。
(4)单目视觉雅可比计算(参考贺大佬)
视觉SLAM十四讲中第162页有提到,将空间坐标系下的3D点投影到像素坐标系下做最小二乘,求出该最小二乘模型的雅各比矩阵既可以得到高斯牛顿或者LM方法的下降梯度,从而优化位姿和路标点,具体的内容请参照书本。需要注意的是VINS在计算视觉雅各比时与书上有三点不同:
①VINS中由feature_tracker传过来的像素点坐标吸收了内参K且做了归一化,因此是吸收内参的归一化图像坐标。
②VINS中使用Q旋转四元数来优化位姿,因此在计算位姿对应的雅各比矩阵时和书上的公式不完全相同。
③VINS是基于滑动窗口,优化的位姿包含滑动窗口中的11帧位姿,但同时是依靠特征点来确定所优化哪两帧的位姿,每次传入视觉残差模型是遍历特征点来确定的,设定i帧为最开始观测到次特征点的相机,则j(不等于i)就为其他共视关键帧。
4.1视觉j帧残差计算(其实也可以计算i帧残差,过程基本相似)
明白上面三个不同点就可以进行下面的公式推导了,首先下图是残差计算模型,VINS选取的是j帧图像的残差计算模型。

4.2整体雅各比公式
传入到上面的j帧视觉残差模型的优化状态量分别是7维的i帧位姿,7维的j帧位姿,7维的相机和IMU外参数以及1为的特征点逆深度。因此需要计算的雅各比如下图所示:

VINS系统的所有结果的参考坐标都是世界坐标,同时都是对应IMU时刻在世界坐标系下的旋转,平移,速度等,而且逆深度的值时相对于i时刻的相机,因此我们需要整理4.1得到的i时刻的关键帧对应到j时刻的归一化相机坐标Pj的重投影方程如下图所示:(我们需要求的是Pj对于i、j时刻关键帧,相机外参以及i时刻的逆深度,所以需要构建这样一个重投影方程,才能满足偏导数求解)

由最终的公式可以看到Pj由i,j时刻的位姿(旋转和平移),相机外参(旋转和平移)以及逆深度表示,下面可以直接求雅各比(偏导数)。
4.3视觉i帧的状态量(位移和旋转)在Pj下的雅各比
这里和视觉SLAM十四讲中有出入,但是解算原理基本相同,利用了旋转四元数和差乘的性质。得到下面的偏导后整个J[0]就可以相乘得到了。

4.4视觉j帧的状态量、相机和IMU之间外参数(位移和旋转)在Pj下的雅各比
这里的雅各比推导过程就不重复了,和上面的过程相似,就直接给结果了

4.6特征点你深度在Pj下的雅各比
逆深度求偏导就比较简单了,就是一个反函数求偏导过程,得到下面的偏导后整个J[3]就可以相乘得到了。

至此,整个基于滑动窗口的视觉残差和雅各比模型就完成了。其协方差矩阵较为简单,代码中直接赋值即可,不需要计算。