spark partitioner使用技巧
spark partitioner使用技巧
以下源码分析基于Spark-1.5.2
在Spark的PairRDDFunctions,OrderedRDDFunctions这两个类中,都会用到RDD的partitioner信息.具体使用到的partitioner的方法如下:
combineByKey
aggregateByKey
groupByKey
aggregateByKey
groupByKey
reduceByKey
cogroup
join
leftOuterJoin
rightOuterJoin
fullOuterJoin
cogroup
join
leftOuterJoin
rightOuterJoin
fullOuterJoin
在使用SparkContext构建RDD的时候,RDD的partitioner信息,一开始为None,只有在key-value类型的RDD中可以设置partitioner信息,在使用partitioner优化RDD的代码的时,最常用到的还是几个链接操作,cogroup/join/leftOuterJoin/rightOuterJoin/fullOuterJoin,这几个操作最终都是调用cogroup方法进行链接操作.
cogroup链接两个RDD的时候,会创建CoGroupedRDD,这个RDD在计算的时候,会判断RDD是否已经已经按要求分区,如果是则属于窄依赖,不需要shuffle,否则需要shuffle.
private
[spark]
class
CoGroupPartition

可以看出,如果一个RDD需要多次在join(特别是迭代)中使用,那么事先使用partitionBy对RDD进行分区,可以减少大量的shuffle.
以下两图分别说明partitionBy前后join的依赖关系:
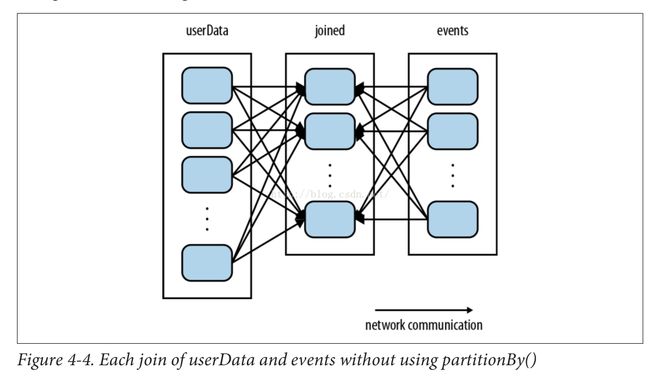
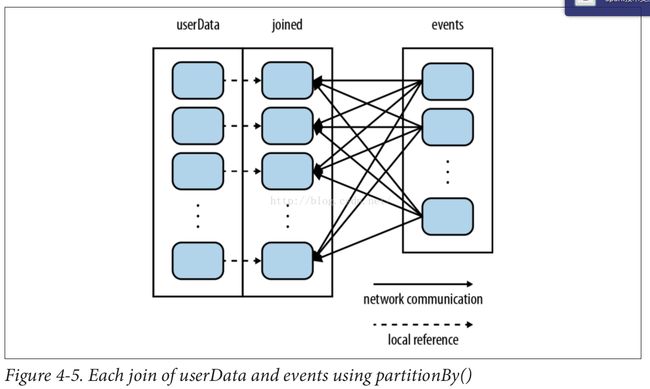
示例说明:

以上代码注意:
1.partitionBy之后一定要使用persist()将partitionBy的结构保存下来,否则下次使用的时候还会重新计算依赖链,(官方说的,我这里还不确定,持怀疑态度).
2.map等普通RDD的操作会将rdd中partitioner属性设置为None,因为map等操作能够改变key的类型。
3.对join效率的提高,不一定要用HashPartitioner,使用RangePartitioner也行这和Partitioner的类型无关.
4.在使用到partitioner的方法中,如果没有显示的指明partitioner的类型,会调用Partitioner类的defaultPartitioner方法,查看这个方法的代码会发现,
如果
rdd
已
经设
置了
partitioner
的信息,
spark.default.parallelism
这个属性会失效
。
5.HashPartitioner(num),num决定了shuffle过程的并发量。
6.不要使用Array类型作为key-value数据的key,HashPartitioner不能以Array为Key进行分区.
defaultPartitoner的代码及其说明如下:
object
Partitioner {
/**
* Choose a partitioner to use for a cogroup-like operation between a number of RDDs.
*
* If any of the RDDs already has a partitioner, choose that one.
*
* Otherwise, we use a default HashPartitioner. For the number of partitions, if
* spark.default.parallelism is set, then we'll use the value from SparkContext
* defaultParallelism, otherwise we'll use the max number of upstream partitions.
*
* Unless spark.default.parallelism is set, the number of partitions will be the
* same as the number of partitions in the largest upstream RDD, as this should
* be least likely to cause out-of-memory errors.
*
* We use two method parameters (rdd, others) to enforce callers passing at least 1 RDD.
*/
def defaultPartitioner (rdd: RDD[_] , others: RDD[_]*): Partitioner = {
/**
* 这一部分代码说明 ,join 等操作 , 即使事先使用了 partitionBy 方法 , 也不一定有优化效果 ,
* 例如 :rdd1.join(rdd2), 期望通过 rdd1 事先 partitionBy 达到优化的目的 , 但是如果在
* join 之前 rdd2 也已经 partitionBy 过 , 并且 rdd2 的 numPartitions>rdd1 的 numPartitions
* 那么 rdd1 还是会按照 rdd2 的分区数量重新进行分区 .
* 另外还要说明一点 ,rdd1.join(rdd2) 和 rdd2.join(rdd1) 输出结果一样 , 优化效果也一样
*/
val bySize = ( Seq (rdd) ++ others).sortBy(_.partitions.size).reverse
for (r <- bySize if r. partitioner .isDefined && r. partitioner .get.numPartitions > 0 ) {
return r. partitioner .get
}
/**
* 如下代码可以看出 , 如果 rdd 已经设置了 partitioner 的信息 , 那么 spark.default.parallelism 这个参数就会失效
* (spark.default.parallelism 这个参数相当于 shuffle 的分区数量 , 决定了 shuffle 的并发量 )
*/
if (rdd.context.conf.contains( "spark.default.parallelism" )) {
new HashPartitioner(rdd.context.defaultParallelism)
} else {
new HashPartitioner(bySize.head.partitions.size)
}
}
}
/**
* Choose a partitioner to use for a cogroup-like operation between a number of RDDs.
*
* If any of the RDDs already has a partitioner, choose that one.
*
* Otherwise, we use a default HashPartitioner. For the number of partitions, if
* spark.default.parallelism is set, then we'll use the value from SparkContext
* defaultParallelism, otherwise we'll use the max number of upstream partitions.
*
* Unless spark.default.parallelism is set, the number of partitions will be the
* same as the number of partitions in the largest upstream RDD, as this should
* be least likely to cause out-of-memory errors.
*
* We use two method parameters (rdd, others) to enforce callers passing at least 1 RDD.
*/
def defaultPartitioner (rdd: RDD[_] , others: RDD[_]*): Partitioner = {
/**
* 这一部分代码说明 ,join 等操作 , 即使事先使用了 partitionBy 方法 , 也不一定有优化效果 ,
* 例如 :rdd1.join(rdd2), 期望通过 rdd1 事先 partitionBy 达到优化的目的 , 但是如果在
* join 之前 rdd2 也已经 partitionBy 过 , 并且 rdd2 的 numPartitions>rdd1 的 numPartitions
* 那么 rdd1 还是会按照 rdd2 的分区数量重新进行分区 .
* 另外还要说明一点 ,rdd1.join(rdd2) 和 rdd2.join(rdd1) 输出结果一样 , 优化效果也一样
*/
val bySize = ( Seq (rdd) ++ others).sortBy(_.partitions.size).reverse
for (r <- bySize if r. partitioner .isDefined && r. partitioner .get.numPartitions > 0 ) {
return r. partitioner .get
}
/**
* 如下代码可以看出 , 如果 rdd 已经设置了 partitioner 的信息 , 那么 spark.default.parallelism 这个参数就会失效
* (spark.default.parallelism 这个参数相当于 shuffle 的分区数量 , 决定了 shuffle 的并发量 )
*/
if (rdd.context.conf.contains( "spark.default.parallelism" )) {
new HashPartitioner(rdd.context.defaultParallelism)
} else {
new HashPartitioner(bySize.head.partitions.size)
}
}
}
在Spark中实现了两类Partitioner,一类是HashPartitioner,另一类是RangePartitioner.
| RangePartitioner 1.用在RDD的sortByKey和filterByRange中,其他key-value的RDD方法都是使用HashPartitioner作为默认partitioner |
| HashPartitioner 1.源码中使用HashPartitioner的地方,都会首先判断rdd是否已经进行过HashPartioner了,如果已经进行了,则属于窄依赖不需要shuffle.在这些判断中,调用的是HashPartitioner的equals方法,equals源码如下:
override def
equals (other: Any):
Boolean
= other
match
{ 可以看出,只有两个HashPartitioner使用了同样的分区数量numPartitions,两个partitioner才是相等的,所以这里要注意一点,要使用partitioner减少shuffle的时候,HashPartitioner(num)中的num要与需要shuffle的方法使用的num数量相同.case h: HashPartitioner => h.numPartitions == numPartitions case _ => false } 示例说明:
val
rdd1 = sc.parallelize( Array((
1
,
1
)
,
(
1
,
2
)
,
(
2
,
1
)
,
(
3
,
1
)
,
(
1
,
2
)
,
(
2
,
1
)
,
(
3
,
1
))) .partitionBy( new HashPartitioner( 2 )).persist() val rdd2=sc.parallelize(Array(( 1 , 'x' ) , ( 2 , 'y' ) , ( 2 , 'z' ) , ( 4 , 'w' ) , ( 2 , 'y' ) , ( 2 , 'z' ) , ( 4 , 'w' ))) /** 有优化效果 ,rdd1 不再需要 shuffle*/ rdd1.join(rdd2) /** 有优化效果 ,rdd1 不再需要 shuffle*/ rdd1.join(rdd2 ,new HashPartitioner( 2 )) /** 无优化效果 ,rdd1 需要再次 shuffle*/ rdd1.join(rdd2 ,new HashPartitioner( 3 )) |